
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Anmerkung der Redaktion: In einer Zeit, in der Innovationen und technologische Fortschritte unsere Welt stetig verändern, steht die Datenverarbeitung an vorderster Front des Wandels. Die Verschmelzung von generativer KI und Datenverarbeitung gestaltet nicht nur die Datenlandschaft neu, sondern eröffnet uns auch ungeahnte Möglichkeiten. Unser neuester Blogbeitrag beleuchtet diese Entwicklung eingehend und untersucht die Synergien zwischen generativer KI und Datenverarbeitung. An diesem Schnittpunkt entdecken wir bahnbrechende Erkenntnisse darüber, wie KI-gestützte Technologien herkömmliche Datenpraktiken revolutionieren und so den Weg zu beispielloser Effizienz und Präzision ebnen.
Es ist unbestreitbar, dass künstliche Intelligenz (KI) und generative künstliche Intelligenz (GenAI) im Mittelpunkt der Diskussionen über die Frage stehen, wie man mit weniger Ressourcen mehr erreichen kann. Dies gilt insbesondere, da Unternehmen weiterhin mit begrenzten Budgets, Fachkräftemangel und der Notwendigkeit, den sich ständig ändernden Kundenerwartungen gerecht zu werden, zu kämpfen haben. Kommt Ihnen das bekannt vor?
Einer Umfrage von KPMG zufolge glauben 77 % der Führungskräfte, dass GenAI von allen neuen Technologien den größten Einfluss auf ihr Geschäft haben wird . Darüber hinaus planen 71 % dieser Führungskräfte, ihre erste GenAI-Lösung innerhalb der nächsten zwei Jahre zu implementieren.
Angesichts solcher Statistiken stehen CIOs im Zentrum der Begeisterung und des Drucks, die mit der Einführung von GenAI einhergehen. Gleichzeitig sind sie mit Fragen wie „Was bedeutet das für mein Unternehmen?“ und „Welche Risiken muss ich berücksichtigen?“ konfrontiert. Eine der wichtigsten Herausforderungen ist wohl: „Wie kann ich mich im Informationsdschungel rund um KI zurechtfinden und meine Data-Engineering-Teams zum Erfolg führen?“

Quelle: Decube
Heute sind 80 bis 90 % der generierten Daten unstrukturiert, und der Wettbewerb um die besten Daten ist so intensiv wie nie zuvor. Das bedeutet, dass Data Engineers zunehmend unter Druck stehen, zuverlässige Datenpipelines aufzubauen und zu pflegen, um ihren Stakeholdern wertvolle Erkenntnisse zu liefern – was mitunter frustrierend sein kann. Generative KI birgt jedoch das Potenzial, das Kräfteverhältnis zugunsten von Kreativität und Inspiration zu verändern.
Kommen wir also ohne Umschweife zu diesem Blog, in dem wir die Möglichkeiten der generativen KI zur Umgestaltung der Datenverarbeitungslandschaft beleuchten werden.
Data Engineering ist das Rückgrat der modernen datengetriebenen Welt. Es umfasst die Extraktion, Transformation und das Laden (ETL) von Daten aus verschiedenen Quellen in nutzbare Formate für die Analyse.
Traditionell war dieser Prozess arbeitsintensiv, fehleranfällig und zeitaufwändig. Da zudem das Datenvolumen und die Datenkomplexität exponentiell zunehmen, sind die Herausforderungen für Dateningenieure noch größer geworden.
Generative KI, insbesondere Modelle wie GPT-3 und GPT-4, hat eine neue Ära im Bereich Data Engineering eingeläutet. Diese LLM-Modelle werden mit riesigen Mengen an Textdaten trainiert, wodurch sie menschenähnliche Texte generieren können und sich daher hervorragend für Aufgaben im Bereich des natürlichen Sprachverstehens und der Textgenerierung eignen.
| Datenerweiterung: Durch den Einsatz von Gen AI lassen sich synthetische Daten erzeugen, die bestehende Datensätze ergänzen. Dateningenieure können diese synthetischen Datensätze nutzen, um Modelle des maschinellen Lernens zu trainieren und zu verbessern und so deren Leistung und Generalisierungsfähigkeit zu steigern. | Automatisierte Datengenerierung: Generative KI-Modelle wie GPT-3 können menschenähnliche Texte erzeugen und erleichtern so Dateningenieuren die Erstellung von Dokumentationen, Berichten und sogar Code-Snippets. Dies spart im Datenverarbeitungsprozess entscheidend Zeit und Aufwand. | Datenmodellierung und Schemaerstellung: Generative KI-Modelle können bei der automatischen Generierung von Datenmodellen und Schemata helfen. Dies reduziert den manuellen Aufwand bei der Definition von Datenstrukturen und -beziehungen und optimiert den Datenverarbeitungsprozess. | Verarbeitung natürlicher Sprache (NLP): Sie ermöglicht Schnittstellen in natürlicher Sprache, über die Dateningenieure mit Datensystemen mithilfe von Befehlen in einfacher Sprache interagieren können. Dies vereinfacht die Datenabfrage und den Datenabruf und macht Daten auch für technisch nicht versierte Anwender zugänglicher. |
ETL (Extrahieren, Transformieren, Laden) ist ein grundlegender Prozess im Data Engineering, der das Extrahieren von Daten aus Quellsystemen, deren Transformation in ein nutzbares Format und das Laden in ein Ziel-Data-Warehouse oder eine Datenbank umfasst. Generative KI revolutioniert ETL auf folgende Weise:
Automatisierte Codegenerierung: Generative KI-Modelle können ETL-Code, wie SQL-Abfragen oder Python-Skripte, generieren, um Datenextraktions- und -transformationsaufgaben durchzuführen. Diese Automatisierung reduziert den Zeit- und Arbeitsaufwand für die Entwicklung von ETL-Pipelines erheblich.
Unterstützung bei der Datentransformation: Sie kann Dateningenieure bei der Entwicklung von Logiken für die Datentransformation unterstützen. Durch die Bereitstellung von Beschreibungen oder Beispielen der gewünschten Transformationen kann generative KI Code-Snippets oder Transformationsregeln generieren und so den ETL-Prozess vereinfachen.
Verbesserte Datenqualität: Es kann auch während des ETL-Prozesses Datenqualitätsprobleme erkennen und beheben. Beispielsweise kann es Code generieren, um Daten zu bereinigen und zu standardisieren, wodurch Fehler reduziert und eine hohe Datenqualität sichergestellt wird.
Skalierbarkeit und Effizienz: Mit Gen AI können Dateningenieure skalierbare ETL-Pipelines erstellen, die sich an wechselnde Datenquellen und Anforderungen anpassen. Diese Flexibilität verbessert die Effizienz der Datenverarbeitung und gewährleistet die zeitnahe Bereitstellung von Erkenntnissen.
Dieser kontinuierliche Verbesserungsprozess gewährleistet somit, dass sich die Datenpipelines weiterentwickeln und sich an veränderte Datenanforderungen und Geschäftsbedürfnisse anpassen.
Erfahren Sie, wie Polestar einem Flughafenkonzessionär geholfen hat, das Datenmanagement mit QlikView zu optimieren – die Datengenauigkeit zu verbessern und sage und schreibe 2,4 Millionen Dollar an Betriebskosten einzusparen!
Tauchen Sie jetzt in diese Erfolgsgeschichte ein! Unternehmen können ihr optimales Potenzial durch den richtigen Technologiemix entfalten. Hier stellen wir verschiedene Aufgaben vor, bei denen KI in unterschiedliche Aspekte ihrer Arbeit integriert werden kann:

1. Datenmanagement
Qualitätssicherung der Daten: Gen AI kann bei der Automatisierung von Datenqualitätsprüfungen helfen und Probleme wie fehlende Werte, Duplikate und Inkonsistenzen kennzeichnen.
Datenkatalogisierung: Sie kann bei der automatischen Katalogisierung und Indizierung von Datenbeständen helfen und es Dateningenieuren erleichtern, Daten zu finden und darauf zuzugreifen.
2. Entwicklung der Datenpipeline
Pipeline-Orchestrierung: Sie kann die Orchestrierung von Datenpipelines automatisieren und so eine reibungslose Ausführung von Daten-Workflows gewährleisten.
Die automatische Skalierung hilft dabei, Ressourcen je nach Arbeitslastbedarf automatisch nach oben oder unten zu skalieren und so die Ressourcennutzung zu optimieren.
3. Modernisierung der Datenarchitektur
Data Lakehouse Design: Gen AI kann Sie bei der Konzeption moderner Data Lakehouses unterstützen, die Data Warehousing und Data Lakes kombinieren und so Datenspeicherung und -zugriff optimieren.
Architekturempfehlungen: Es kann Empfehlungen für architektonische Verbesserungen geben, wie z. B. die Einführung cloudnativer Lösungen oder Microservices.
4. ETL & Datentransformation:
Codegenerierung: Gen AI kann ETL-Code basierend auf den Anforderungen an die Datentransformation generieren, wodurch der Bedarf an manueller Codierung reduziert wird.
Datenmapping: Es kann dabei helfen, Datenquellen automatisch Zielschemata zuzuordnen und so Datentransformationsprozesse zu optimieren.
5. Daten-Governance und Compliance:
Datenherkunftsverfolgung: Gen AI kann die Datenherkunftsverfolgung automatisieren, um sicherzustellen, dass Datenbewegungen und -transformationen den Richtlinien zur Datenverwaltung entsprechen.
Sicherheitsauditierung: Es kann automatisierte Sicherheitsaudits durchführen, potenzielle Schwachstellen identifizieren und die Einhaltung der Datenschutzbestimmungen sicherstellen.
Allerdings ist der Einsatz von Gen-AI-Tools in Verbindung mit menschlicher Expertise unerlässlich, um sicherzustellen, dass die Automatisierung mit den Geschäftszielen und den regulatorischen Anforderungen übereinstimmt.

Quelle: Google
Obwohl generative KI das Potenzial hat, viele Aspekte der Datenverarbeitung zu automatisieren, ist es unerlässlich zu erkennen, dass menschliche Eingaben und manuelle Eingriffe in verschiedenen Szenarien weiterhin notwendig sind:
Komplexe Anforderungen: Generative Modelle benötigen unter Umständen Unterstützung bei komplizierten oder mehrdeutigen Anforderungen. Data Engineering umfasst häufig komplexe Geschäftsregeln, Datentransformationen und Datenintegrationsaufgaben, deren präzise Definition menschliches Fachwissen erfordern kann.
Domänenspezifität: Viele Aufgaben im Bereich Data Engineering sind stark domänenspezifisch. Generative KI-Modelle benötigen unter Umständen mehr Domänenwissen, um Code oder Schemata zu generieren, die spezifischen Branchenstandards oder Best Practices entsprechen. Daher ist die menschliche Überprüfung unerlässlich, um die von diesen Modellen generierten Ergebnisse zu prüfen und zu validieren, insbesondere bei kritischen Data-Engineering-Aufgaben.
Einschränkungen bei der Eingabeaufforderung: Generative KI-Modelle verfügen oft nicht über das nötige Kontextverständnis und können fehlerhaften oder unvollständigen Code generieren, wenn die Eingabeaufforderung mehrdeutig oder schlecht strukturiert ist. Dateningenieure müssen daher unbedingt klare und kontextreiche Eingabeaufforderungen bereitstellen, um sicherzustellen, dass der generierte Code ihren Intentionen entspricht.
Datenschutz und Datensicherheit: Bei der Datenverarbeitung wird häufig mit sensiblen und vertraulichen Daten gearbeitet. Generative KI-Modelle müssen sorgfältig kontrolliert werden, um zu vermeiden, dass Code oder Dokumentation generiert wird, die sensible Informationen offenlegt.
Qualitätssicherung: Menschliche Aufsicht ist für die Qualitätssicherung unerlässlich. Obwohl generative KI bestimmte Aufgaben automatisieren kann, müssen Dateningenieure den generierten Code, die Modelle und die Dokumentation überprüfen und validieren, um Genauigkeit und Zuverlässigkeit zu gewährleisten.
Unvorhergesehene Szenarien: Im Data Engineering stößt man häufig auf unerwartete Szenarien oder Datenanomalien, die generative Modelle möglicherweise nicht abdecken. Menschliches Eingreifen ist entscheidend für den effektiven Umgang mit solchen Situationen.
Bevor wir zum Schluss kommen, wollen wir uns einige Anwendungsfälle von generativer KI ansehen, die immer beliebter werden, und selbst Anbieter von Datenprodukten konzentrieren ihre Bemühungen darauf, Funktionen wie die folgenden zu implementieren:
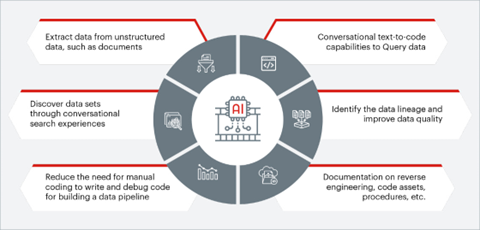
Unternehmen, die die Synergie zwischen generativer KI und Data Engineering effektiv nutzen, werden sich im datengetriebenen Umfeld einen Wettbewerbsvorteil sichern. Die Zukunft verspricht spannende Möglichkeiten für alle, die das Potenzial von KI ausschöpfen und gleichzeitig höchste Standards in Bezug auf Datenqualität und ethische Nutzung gewährleisten. Kontaktieren Sie uns noch heute, um mehr über unsere Data-Engineering-Dienstleistungen zu erfahren.