
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
- Welche Databricks-Anwendungsfälle für Unternehmen liefern den schnellsten und messbarsten ROI?
- Wie die Architektur der Databricks Data Intelligence Platform Streaming-, Batch- und KI-Workloads innerhalb eines einzigen Stacks verarbeitet.
- Warum Governance (und nicht nur Rechenleistung) der entscheidende Faktor für die meisten Anwendungsfälle von Databricks AI in regulierten Branchen ist
Nur etwa 48 % der KI-Projekte schaffen es vom Prototyp bis zur Serienproduktion.
Nicht etwa, weil die Modelle schlecht wären. Sondern weil die zugrundeliegende Dateninfrastruktur nie für deren Unterstützung ausgelegt war.
Die Databricks Data Intelligence Platform hat sich als bevorzugte Architektur für Unternehmen etabliert, die diese Lücke schließen wollen. Sie ist darauf ausgelegt, das zu leisten, woran fragmentierte Toolchains scheitern: Batch- und Streaming-Verarbeitung in derselben Umgebung, Governance und Rechenleistung auf derselben Plattform sowie KI-Workloads, die auf derselben Datenschicht laufen, die auch den täglichen Betrieb ermöglicht.
Die Plattform liefert jedoch nicht von allein Ergebnisse. Unternehmen, die echten Mehrwert aus Databricks Data Intelligence ziehen, sind diejenigen, die sie mit architektonischer Disziplin implementieren – sie müssen verstehen, für welche Anwendungsfälle sie sich tatsächlich eignet, wie die tatsächlichen Fehlerquellen aussehen und welche Governance-Entscheidungen getroffen werden müssen, bevor auch nur eine einzige Pipeline ausgeführt wird.
Der Zeitpunkt ist kein Zufall. Drei Kräfte wirken gleichzeitig in den Datenorganisationen von Unternehmen zusammen.
- Das Volumen und die Vielfalt der Daten, die Organisationen verarbeiten müssen, haben die Möglichkeiten traditioneller Data-Warehouse-Architekturen überholt.
- Initiativen im Bereich KI und maschinelles Lernen haben sich von experimentellen Projekten zu Prioritäten auf Vorstandsebene entwickelt. Dies erzeugt Druck, eine Infrastruktur aufzubauen, die diese im Produktivbetrieb unterstützen kann.
- Die regulatorische Kontrolle in Bezug auf Datenzugriff, Datenherkunft und die Steuerung von KI-Modellen hat unkontrollierte Datenumgebungen zu einer rechtlichen und reputationsbezogenen Belastung gemacht, nicht nur zu einer technischen Unannehmlichkeit.
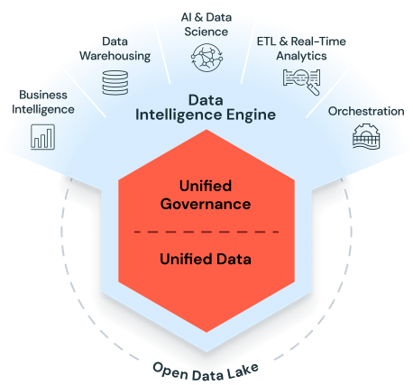 Quelle: Die Databricks-Datenintelligenzplattform
Quelle: Die Databricks-Datenintelligenzplattform Wissen Sie?
Unternehmen, die die Modernisierung verzögern, bleiben nicht stehen – sie fallen hinter Organisationen zurück, die die Vorteile einer einheitlichen Dateninfrastruktur bereits voll ausschöpfen.
Die Architektur der Databricks Data Intelligence Platform begegnet all diesen Herausforderungen mit einer einzigen Technologieplattform. Das Lakehouse-Modell beseitigt die strukturelle Trennung zwischen Data Lakes und Data Warehouses. Unity Catalog ermöglicht die einheitliche Verwaltung von Daten-, Analyse- und KI-Ressourcen. Und die Rechenschicht der Plattform skaliert – bei korrekter Konfiguration – für alle Anwendungsfälle, von der Verarbeitung historischer Datenstapel bis hin zum Millisekunden-Streaming von IoT-Daten. Die folgenden Anwendungsfälle veranschaulichen die Umsetzung in realen Unternehmensumgebungen.
Entdecken Sie die Migrationsmuster, die erfolgreiche Unity Catalog-Bereitstellungen von fehlgeschlagenen unterscheiden!
Die Erfolgsmuster erkennen Wenn von Modernisierung die Rede ist, wird sie fast immer mit einer reinen Umstrukturierung verglichen. Genau da liegt der Fehler.
Der häufigste und unmittelbar wirkungsvollste Anwendungsfall für Databricks in Unternehmen ist die Zusammenführung fragmentierter Dateninfrastrukturen in einem zentralen, verwalteten Data Lake. Die meisten großen Organisationen betreiben nicht nur eine Datenplattform, sondern mehrere: ein veraltetes, lokales Data Warehouse, einen Cloud-Objektspeicher, der als Ad-hoc-Data-Lake dient, eine separate Analyseumgebung und einen isolierten ML-Arbeitsbereich. Jede dieser Plattformen wurde entwickelt, um ein spezifisches Problem zu einem bestimmten Zeitpunkt zu lösen. Zusammen führen sie zu Verzögerungen bei der Berichterstellung, Dateninkonsistenzen und einem Entwicklerteam, das mehr Zeit mit der Wartung als mit der Wertschöpfung verbringt.
Die Architektur der Databricks Data Intelligence Platform löst dieses Problem durch die Medaillonarchitektur – einen geschichteten Ansatz, der Daten strukturiert in:
- Bronze (Rohaufnahme),
- Silber (gereinigt und geprüft),
- und Goldzonen (zusammengefasste, geschäftsbereite Zonen).
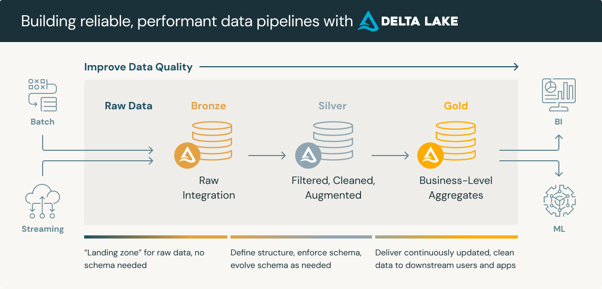 Quelle: Databricks
Quelle: Databricks Delta Lake bildet die Grundlage aller drei Schichten und bietet ACID-Transaktionen, Schema-Durchsetzung und Time-Travel-Funktionen, die herkömmliche Data Lakes nicht bieten können. Das Ergebnis ist eine zentrale Datenquelle, die sowohl operative Berichte als auch KI-Workloads ohne Duplizierung oder zusätzlichen Abgleichaufwand unterstützt.
Der häufigste Fehler in diesem Anwendungsfall liegt im Management der Rechenkosten. Unternehmen, die Databricks zum ersten Mal einsetzen, unterschätzen oft die Kosten, die durch interaktive, universelle Rechencluster entstehen, die ohne automatische Beendigungsrichtlinien betrieben werden. Die Lösung ist architektonischer Natur und nicht reaktiv: Standardisierung auf Jobcluster für automatisierte Workloads, Erzwingung der automatischen Beendigung auf Infrastruktur-als-Code-Ebene mithilfe vonTerraform und die Cluster-Governance von Anfang an als Finanzkontrolle und nicht als Konfigurationsdetail, das erst nach einem Kostenanstieg behoben wird.
Erfahren Sie, was eine vollständige Modernisierung Ihrer Dateninfrastruktur tatsächlich beinhaltet → Migrieren und modernisieren Sie Ihre Dateninfrastruktur
Siehe den Lieferumfang Echtzeit-Streaming ist der Bereich, in dem sich die Architektur der Databricks Data Intelligence Platform am deutlichsten von herkömmlichen Ansätzen abhebt – und in dem sich die Folgen einer fehlerhaften Implementierung am unmittelbarsten bemerkbar machen. Für die Fertigungsindustrie, Logistik, Energieversorgung und alle Branchen, die auf physische Prozesse angewiesen sind, ist die Fähigkeit, auf Daten in Bewegung statt auf ruhende Daten zu reagieren, keine Frage der technischen Präferenz. Es ist der entscheidende Unterschied zwischen der Vermeidung und der Reaktion auf einen Fehler.
Vorausschauende Wartung durch Echtzeit-Datenverarbeitung kann Maschinenstillstandszeiten um 30 bis 50 % reduzieren und die Lebensdauer von Anlagen um 20 bis 40 % verlängern. Der Engpass in den meisten Unternehmen ist nicht die Verfügbarkeit von Sensordaten, sondern die Latenz in der Pipeline!
Die zentrale architektonische Herausforderung bei industriellen IoT-Implementierungen liegt in der Koexistenz grundverschiedener Datentypen: hochfrequente Sensordatenströme im Millisekundenbereich und langsame ERP- oder MES-Batch-Datensätze, die täglich oder stündlich aktualisiert werden. Herkömmliche ETL-Systeme waren für den einen oder anderen Datentyp ausgelegt. Die Databricks Data Intelligence Platform ist darauf ausgelegt, beide gleichzeitig zu verarbeiten – die Art der Implementierung entscheidet jedoch darüber, ob dieses Potenzial ausgeschöpft wird.
Die entscheidende Frage ist die Wahl zwischen manuellem PySpark Structured Streaming und Delta Live Tables (DLT) . Manuelle Streaming-Jobs erfordern, dass Entwickler jeden Fehlermodus explizit definieren und verwalten – Checkpoint-Management, Zustandswiederherstellung, Behandlung von Schemaänderungen. Bei großem Umfang und mehreren gleichzeitig verarbeiteten Sensorfeeds wird dies zu einem fehleranfälligen und kostspieligen Wartungsaufwand. Delta Live Tables verlagert diese Last auf die Plattform selbst. Entwickler definieren den Zielzustand der Daten; DLT kümmert sich automatisch um die Auflösung von Abhängigkeiten, die Fehlerbehandlung, Wiederholungsversuche und das Speichern von Zustands-Checkpoints.
Organisationen, die deklarative Pipeline-Frameworks einsetzen, berichten von einer bis zu 60%igen Reduzierung des Wartungsaufwands für ihre Pipelines im Vergleich zu solchen, die manuell programmierte Streaming-Jobs betreiben. Die dadurch eingesparte Entwicklungszeit ermöglicht schnellere Iterationen auf den darüberliegenden Analyse- und KI-Ebenen.
Das praktische Ergebnis einer gut implementierten DLT-Architektur im industriellen Umfeld ist eine Datenpipeline, die hochfrequente Sensordaten verarbeiten, mit kontextbezogenen ERP-Datensätzen verknüpfen und daraus handlungsrelevante Signale für die vorausschauende Wartung generieren kann – und das alles innerhalb von weniger als einer Minute. Der dadurch ermöglichte operative Wandel ist bedeutend: von reaktiver Störungsbehebung hin zu proaktivem Eingreifen, bevor ein Ausfall eintritt, anstatt erst danach.
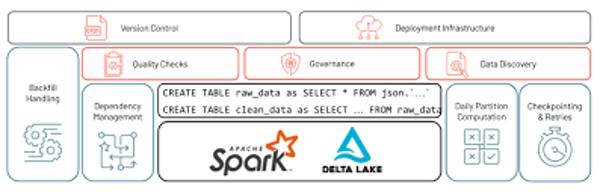 Quelle: Databricks
Quelle: Databricks
Generative KI auf Basis firmeneigener Daten stellt die Kategorie mit dem größten Potenzial und gleichzeitig dem höchsten Risiko unter den KI-Anwendungsfällen von Databricks dar. Das kommerzielle Potenzial ist enorm: Abfragen unstrukturierter Dokumente in natürlicher Sprache, KI-gestützte Compliance-Prüfungen, Vertragsanalysen und Analysten-Co-Piloten, die die SQL-Abhängigkeit für Geschäftsanwender eliminieren. Doch in regulierten Branchen – Finanzdienstleistungen, Pharma, Gesundheitswesen, Versicherungen – führt der Weg vom Prototyp zur Produktion direkt über einen Governance-Checkpoint, auf den die meisten Organisationen nicht vorbereitet sind.
Das Muster ist immer gleich. Ein Unternehmen entwickelt eine technisch ausgereifte generative KI-Anwendung mit der Databricks Data Intelligence Engine – ein umfangreiches Sprachmodell wird anhand firmeneigener Dokumentation feinabgestimmt, und die generische Datenabfrage wird in interne Wissensdatenbanken integriert. Dann stellt der CISO, die Rechtsabteilung oder die Compliance-Abteilung eine einfache Frage: Können Sie uns genau zeigen, mit welchen Daten das Modell trainiert wurde, wer Zugriff darauf hatte und welche Kontrollmechanismen implementiert waren? Ohne eine strukturierte Antwort wird das Projekt gestoppt.
Wussten Sie?
- Laut einer Studie von KPMG sehen 62 % der Unternehmen mangelnde Daten-Governance als größte Herausforderung für KI-Initiativen. (KPMG, 2025)
- Eine IBM-Umfrage aus dem Jahr 2024 ergab, dass nur 24 % der derzeit eingesetzten KI-Projekte von der Organisation gesteuert werden, die sie einsetzt (IBM, 2024).
Die Governance-Lücke ist das entscheidende Hindernis zwischen KI-Experimenten und KI im großen Maßstab.
Die architektonische Lösung ist Unity Catalog – die einheitliche Governance-Ebene von Databricks für Daten-, Analyse- und KI-Ressourcen. Unity Catalog bietet Zugriffskontrollen auf Zeilen- und Spaltenebene, vollständige Datenherkunft von der Rohdatenquelle bis zur Modelleingabe, attributbasierte Zugriffsrichtlinien und eine zentrale Governance-Oberfläche für strukturierte Daten, unstrukturierte Dokumente, ML-Modelle und Notebooks. Wichtig: Unity Catalog kann nicht nachträglich hinzugefügt werden – es muss als erste Produktionsressource bereitgestellt werden, bevor Pipelines erstellt oder Modelle trainiert werden. Die nachträgliche Integration ist deutlich aufwendiger als die von Anfang an geplante Architektur.
Bei all diesen Anwendungsfällen bestimmen drei Architekturprinzipien durchweg, ob eine Databricks-Implementierung einen nachhaltigen Produktionsbetrieb erreicht oder technische Schulden anhäuft.
- Die Governance sollte ab dem ersten Tag berechnet werden, nicht ab dem 60. Tag.
Die Elastizität der Databricks Data Intelligence Platform ist ein Vorteil, wenn sie gezielt eingesetzt wird. Ohne automatische Beendigungsrichtlinien, Clusterstandardisierung und die konsequente Umsetzung von Infrastructure-as-Code von Anfang anwerden die Rechenkosten zur ersten Krise, mit der ein Unternehmen konfrontiert ist – in der Regel innerhalb der ersten zwei Monate.
- Deklarative Pipelines statt manueller Orchestrierung.
Der Wechsel von manuell programmiertem PySpark-Streaming zu Delta Live Tables ist keine Frage der Werkzeugwahl, sondern eine Architekturentscheidung, die die Fehleranfälligkeit verändert. Manuelle Orchestrierung legt die gesamte Verantwortung für die Zuverlässigkeit auf das Entwicklerteam. Deklarative Pipelines hingegen verlagern sie auf die Plattform. Im großen Maßstab führt dieser Unterschied zu kürzeren Wiederherstellungszeiten, geringerer Rufbereitschaft und Pipelines, die im Fehlerfall sanft und nicht katastrophal ausfallen.
- Unity Catalog als Grundlage, nicht als Endprodukt.
Jedes Unternehmen, das Unity Catalog als letzten Schritt einsetzt – nachdem Pipelines betriebsbereit und Modelle trainiert sind –, stößt auf eine erzwungene Funktion, die dessen Priorität zurücksetzt. Governance ist keine nachträglich hinzugefügte Schicht auf einem bestehenden System. Sie ist die Grundlage, die ein funktionierendes System vertrauenswürdig genug für den Produktiveinsatz macht.
Dies sind keine Beobachtungen aus Einzelprojekten. Es handelt sich um Muster, die sich in den Architekturen der Databricks-Datenintelligenzplattform wiederholen, die in großem Umfang, branchenübergreifend und unter realen Produktionsbedingungen entwickelt wurden.
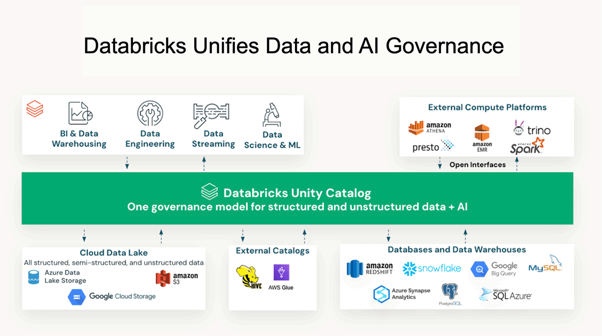 Quelle: Databricks Unity Catalog Governance-Werthebel
Quelle: Databricks Unity Catalog Governance-Werthebel
Die Databricks-Datenintelligenzplattform ist keine Zukunftsmusik. Sie ist eine produktionsreife Architektur, die Unternehmen verschiedenster Branchen bereits heute einsetzen – für die Lakehouse-Konsolidierung, Echtzeit-Streaming und gesteuerte generative KI. Die Anwendungsfälle sind erprobt. Die Ergebnisse sind dokumentiert. Die Fehlerquellen sind gut verstanden.
Unveränderlich bleibt die Umsetzung.
Die Unternehmen, die den größten Nutzen aus Databricks Data Intelligence ziehen, sind selten diejenigen mit den größten Budgets oder den ambitioniertesten KI-Strategien. Sie sind diejenigen, die frühzeitig die richtigen Architekturentscheidungen getroffen haben: Sie haben ihre Rechenkapazität kontrolliert, bevor diese ihr Budget bestimmte, deklarative Pipelines gewählt, bevor die manuelle Orchestrierung zum Problem wurde, und den Unity Catalog bereitgestellt, bevor Compliance-Fragen sie zum Umdenken zwangen.
Wenn Sie bewerten, wo Ihre Organisation im Hinblick auf diese Anwendungsfälle steht – sei es bei der Planung einer ersten Migration, der Stabilisierung einer Streaming-Architektur, die an ihre Grenzen gestoßen ist, oder der Schließung einer Governance-Lücke, die eine KI-Initiative blockiert –, befinden Sie sich an typischen Punkten auf diesem Weg. Die meisten Unternehmen erreichen einen dieser Punkte, bevor sie den richtigen Weg finden.
Die entscheidende Frage ist nicht, ob die Databricks Data Intelligence Platform Ihr Problem lösen kann. In den meisten Fällen kann sie das. Viel wichtiger ist die Frage, ob Ihr aktueller Ansatz – Ihre Architektur, Ihr Governance-Modell, Ihre Implementierungsreihenfolge – dafür ausgelegt ist.
Falls diese Frage noch nicht eindeutig beantwortet ist, lohnt sich ein Gespräch mit jemandem, der bereits Erfahrung mit solchen Entscheidungen in verschiedenen Produktionsumgebungen hat.