
Summarize this blog post with:
Databricks Unity Catalog migrations don’t fail at scale because of access controls. They fail when teams migrate schemas, permissions, and users—without migrating domains, metadata, and operating models.
Databricks Unity Catalog crossed 1 million+ monthly SKD downloads . Adoption clearly isn't the problem. What happens after adoption is.
Most organizations migrate to Unity Catalog treating it like Hive Metastore with better permissions. Spoiler alert – It isn’t. Unity Catalog isn't Hive Metastore 2.0.
Hive Metastore was a metadata store with workspace-scoped access controls. Unity Catalog is fundamentally different— it's an account-centric, identity-driven governance platform that decouples data governance from compute infrastructure. That distinction matters more than most teams realize until migrations start breaking.
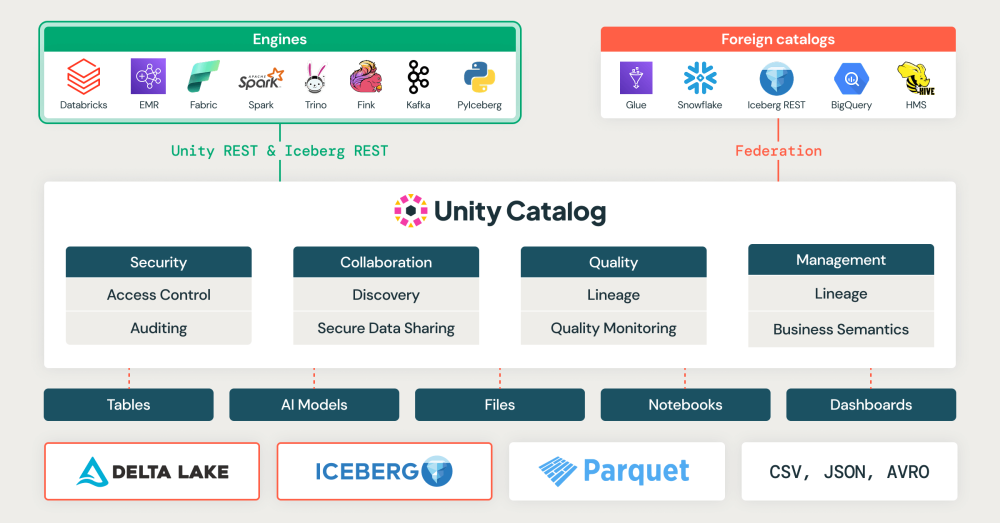 Source: Databricks
Source: Databricks
Unity Catalog's recognition comes from its governance capabilities—lineage tracking, auditing, tagging, and discoverability. But here's what we're seeing consistently: teams implement access controls and call it "governance complete." They focus entirely on who can access what, then wonder why analysts still struggle to find data, why adoption stays flat, why governance feels like a blocker rather than an enabler.
The missing piece is almost always the same—metadata treated as an afterthought rather than a migration requirement. Standardized table and column descriptions. Consistent tagging for sensitivity, business domain, and data type. Lineage validated and exposed post-migration. Without these, you've built a permission system. With them, you've built a governance platform people actually use.
Here's what keeps breaking—and what actually works.
Most teams sync databases 1:1 from HMS to UC—run migration tools, copy schemas, repoint notebooks, update connection strings. The assumption: UC is an upgraded Hive Metastore, so database structures should transfer directly. They don't. As Fred Aboud, Solutions Architect at Databricks, said in recent conversation with Polestar Analytics:
That user_analytics database with raw events, cleaned dimensions, and business aggregates all mixed together? In HMS, workspace-scoped permissions made this tolerable. In UC, it fragments—every access decision now requires explicit account-level grants, and what worked for five engineers doesn't scale across three business units.
One pattern that works consistently: shifting from database-centric to domain-oriented migration. Instead of finance_raw, finance_clean, finance_reporting as separate schemas, create one finance catalog structured by data maturity:
finance/
Raw/ ←Ingestion only, engineering access
Curated / ← Validated data, engineering + analytics
Business/ ←Aggregated, broad read access .
When someone needs finance data, they request access to the finance catalog and automatically inherit appropriate schema-level permissions. One domain owner approves access, period.
Execute incrementally: migrate finance first, validate access permissions and performance, confirm downstream dependencies work, then move to product.
| ✓ Success Patterns |
| 📊 Domain-Oriented Migration
|
- Finance catalog (not finance_raw + finance_clean + finance_reporting)
- Bronze/Silver/Gold within each catalog
- One domain owner, clear accountability
- Migrate incrementally, validate at each step
|
| 📈 OUTCOME
|
| 📉 Reduced migration friction |
- Clear ownership and governance
- Higher platform adoption
- Fewer post-migration surprises
|
But domain structure alone doesn't solve the permission chaos that inevitably follows. Even with perfect catalog organization, teams hit the identity wall...
Here's the reactive pattern we see constantly: migrate tables first, tune permissions based on who complains. Seems pragmatic—why over-engineer before understanding actual usage patterns?
Unity Catalog's architecture makes this untenable. Unity Catalog eliminated workspace-scoped permissions entirely. Access is now account-level and identity-driven. The cluster doesn't grant permissions—the user running the query or the service principal running the job needs explicit grants.
When this isn't designed upfront, the sequence is always the same — dashboards break, engineers lose access to data they previously owned, broad grants get issued to unblock work quickly. When security then asks "who can access customer PII?", nobody can answer without querying the system and manually reconstructing the access graph. That's what a permission model built from firefighting looks like.
Design the access model before migrating data. Map personas to groups upfront — analysts get SELECT on gold schemas, engineers get full access to raw/curated, data scientists get dedicated experimental catalogs. Grant at catalog and schema levels, not table-by-table. Schema-level grants apply automatically to new tables created within that schema.
Configure service principals before migration, not after. Production pipelines run as service principals, not user accounts. Discovering this post-migration means fixing jobs in production.
|
✓ Success Patterns
|
|
📊 Access-First Design
|
- Map personas before migration
- Grant at catalog/schema level
- Configure service principals upfront
- Standardize patterns across domains
|
| 📈 OUTCOME
|
| 📉 Reduced Unity Catalog operational overhead |
- Auditable and scalable governance
- Predictable access behavior — access becomes intentional, not accidental
|
Even with access sorted, there's a scaling problem most teams miss until it's too late. And it stems from one seductive UC capability...
Unity Catalog supports column-level access control. Teams discover this and immediately manage permissions at maximum granularity — marketing sees campaign_id but not email, finance sees revenue but not customer_name. Every table gets custom rules. It feels like thorough governance. It isn't.
The complexity tax compounds fast:
- Exponential overhead — 300 tables under individual configurations means every new use case needs a bespoke grant, never an inherited role.
- The visibility gap — answering "who can access customer PII?" means auditing dozens of fragmented grants across disconnected tables. Security reviews take weeks.
- The real irony — the more granular the model, the less auditable it becomes. The opposite of what governance is supposed to deliver.
Hierarchical by default, granular by exception. Catalogs map to business domains. Schemas map to data maturity. Tables inherit automatically. Per the Databricks blog: "Catalogs often mirror organizational units or software development lifecycle scopes." Governance complexity now scales with your business, not your metadata.
Reserve table or column-level grants for highly sensitive PII or regulated datasets requiring a specific audit trail. Each exception needs documented justification and periodic review. A high number of exceptions signals your hierarchical model needs redesign — not that your security is thorough.
Databricks documentation explains: "Catalogs are used to organize your data assets and are typically used as the top level in your data isolation scheme. Catalogs often mirror organizational units or software development lifecycle scopes."
This means managing access at significantly fewer levels instead of hundreds of individual table configurations. Governance complexity scales with business domains, not table count.
|
✓ Success Patterns
|
|
📊 Hierarchical by Default
|
- Catalogs = Business domains
- Schemas = Data maturity (Bronze/Silver/Gold)
- Tables inherit automatically
- Exceptions: Highly sensitive or regulated datasets only, with clear justification
|
| 📈 OUTCOME
|
| 📉 Reduced Unity Catalog operational overhead |
- Simpler governance model
- Scalable and auditable access control
- Reduced Unity Catalog operational burden, strong control without unnecessary complexity
|
You can get domain structure right. You can design access perfectly. You can keep permissions hierarchical. And still break trust with a single oversight—one that hits downstream consumers hardest.
The migration finishes. All tables exist in Unity Catalog, permissions configured, governance validated. Then BI dashboards go dark. Reports that ran for years fail. Python scripts can't find tables. ETL breaks.
And all because of one reason: HMS used two-part names (database.table), UC requires three-part names (catalog.schema.table) for every tool, script, pipeline, and integration that touches your data is affected.
Treat consumer compatibility as a first-class requirement. Map all consumers before migration — BI tools, reports, scripts, integrations. Create an abstraction layer with views in HMS locations redirecting to UC tables. Consumers keep working while teams migrate underneath them. Migrate BI tools in parallel with data, not after. Different tools have different migration paths — validate early, don't assume uniformity.
|
✓ Success Patterns
|
|
📊 Consumer-First Migration
|
- Map all consumers before migration
- Deploy abstraction layer (Hive Metastore views)
- Migrate BI tools in parallel with data
- Monitor and deprecate only after proven stability
|
| 📈 OUTCOME
|
| 🛡️ Zero or minimal disruption to consumers |
- Preserved analyst confidence
- Controlled transition to Unity Catalog governance
- Faster adoption with lower risk
|
Managing 10 Catalogs is Hard. Try Managing a Global Data Mesh.
With the mesh context A global alcobev leader implemented data mesh architecture with Unity Catalog, harmonizing governance across 15+ business domains and regional regulatory requirements—hierarchical permissions were the only approach that could scale.
See the full approach with Unity Catalog
The platform ships. Technically, everything works. Then the real failure begins.
Engineers request access patterns that no longer exist. Analysts hit permission errors and revert to workarounds. When compute isn’t UC-compatible, the non-UC cluster becomes the path of least resistance. Every workaround normalizes bypassing governance. A governance platform people route around is just expensive infrastructure.
The root cause is always the same — UC doesn’t just change how data is accessed, it changes who owns access decisions, who approves requests, and who is accountable when something breaks. Deploying the platform without redesigning those workflows guarantees the failure mode above.
Treat governance as operating model evolution, not software deployment.
- Before migration: define who approves access requests per domain, establish RACI ownership for each catalog and schema, standardize access request workflows, and validate compute readiness — clusters, job identities, access modes — before data moves.
- During migration: run targeted enablement for engineers, analysts, and platform teams in parallel. Not as an afterthought.
- After migration: invest in continuous enablement as teams encounter new patterns and edge cases.
Compute preparation and change management aren't sequential steps that happen after migration. They're prerequisites that determine whether the migration actually sticks.
|
✓ Success Patterns
|
|
📊 Operating Model Transformation
|
- Define clear governance operating models
- Establish ownership using RACI frameworks
- Standardize access request workflows
- Run targeted enablement for all personas
|
| 📈 OUTCOME
|
| 🤝 Governance is adopted ( not avoided) |
- Reduced friction between teams
- Consistent and auditable controls
- Governance becomes an enabler (not a blocker)
|
Each pattern builds on the last. Domain structure makes identity design obvious. Identity design makes hierarchical permissions manageable. Get one wrong and it compounds downstream. Get one right and the next becomes easier.
The platform is the easy part. How your organization thinks about ownership, accountability, and enablement is where migrations actually succeed or fail.
The enterprises getting this right don't do it alone — and as a Databricks Select Partner, that's exactly the work we do at Polestar Analytics.
Because Unity is indeed strength — especially when technical precision meets organizational readiness.
PS -
So You've Migrated—Now What?
Migration gets your data into Unity Catalog. What you build next determines whether you've got a governance platform or just an expensive permission system.
See What actually comes after migration.
Until next time!