
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Anmerkung der Redaktion: Die Daten liegen vor. Die Frage im Jahr 2026 ist, ob die zugrundeliegende Infrastruktur darauf ausgelegt ist, auf diese Daten zu reagieren – oder sie lediglich zu erfassen. Die Technologie ist ausgereift. Die Architekturen haben sich angeglichen. Jetzt geht es darum, sie im großen Maßstab nutzbar zu machen.
Die Datenanalysetrends, die 2026 prägen werden, drehen sich nicht um neue Tools oder größere Modelle – vielmehr geht es darum, wofür Datenteams heute verantwortlich sind und welche Kosten entstehen, wenn sie Fehler machen. Dieser Artikel richtet sich an Data Engineers, Analytics Architects und CDOs, die aktuell Infrastrukturentscheidungen treffen.
Nahezu jedes große Unternehmen behauptet heute, datengetrieben zu sein. Doch nur 37,8 % der Fortune-1000-Unternehmen sind es tatsächlich – trotz durchschnittlicher jährlicher Ausgaben von 250 Millionen US-Dollar für Datenprojekte. Diese Diskrepanz besteht seit Jahren. Was sich im Jahr 2026 ändert, sind die Kosten.
Als die Analyseinfrastruktur lediglich die Berichterstellung unterstützen musste, bedeutete eine fehlerhafte Datenpipeline ein fehlerhaftes Dashboard. Behebbar. Sichtbar. Eingrenzbar. Doch mit dem Übergang der KI vom Pilotprojekt zum Produktiveinsatz löst dieselbe Infrastruktur nun automatisch Entscheidungen aus – und fehlerhafte Daten führen nicht mehr nur zu einem fehlerhaften Bericht. Sie führen zu einer fehlerhaften Aktion, in Echtzeit und in großem Umfang.
Mehr als die Hälfte hat erhebliche Ressourcen verschwendet, indem sie Modelle mit Daten trainiert haben, denen sie nicht hätten vertrauen sollen.
Die Organisationen, die die Kluft vergrößern, sind nicht diejenigen mit den besten Modellen oder den größten Teams. Es sind diejenigen, die die Datenarchitektur als strategische Entscheidung behandelt haben – und nicht als Voraussetzung für die strategische Entscheidung.
Der globale Markt für Analytik wird Prognosen zufolge von 104 Milliarden US-Dollar im Jahr 2026 auf 496 Milliarden US-Dollar im Jahr 2034 wachsen. Wer von diesem Wert profitiert, wird bereits jetzt durch die getroffenen Infrastrukturentscheidungen bestimmt. Hier sind die sechs entscheidenden Faktoren, die die erfolgreichen Unternehmen auszeichnen.
Jahrzehntelang basierte die Datenanalyse auf einem Pull-Prinzip. Jemand formulierte eine Frage, öffnete ein Tool, und das System lieferte eine Antwort. Die Erkenntnisse waren nur so gut wie die gestellte Frage – was bedeutete, dass ganze Signalkategorien unbemerkt blieben, einfach weil niemand daran dachte, danach zu suchen.
Agentenbasierte Analytik bricht mit diesem Vertrag. Anstatt auf Anfragen zu warten, überwachen diese Systeme kontinuierlich – sie erkennen Anomalien, bevor sie zu Problemen werden, erklären die Zahlen in verständlicher Sprache und reagieren, sofern Schwellenwerte dies zulassen, direkt. Der Mensch bleibt zwar in den Prozess eingebunden, jedoch nur noch auf der Entscheidungsebene, nicht mehr auf der Datenabfrageebene.
So funktionieren KI-Agenten -
Die treibende Kraft dahinter ist nicht ein einzelner Faktor. Große Sprachmodelle (LLMs) ermöglichen es Agenten, unstrukturierte Kontexte zu analysieren. Kleinere, spezialisierte Modelle (SLMs) machen diese Analyse auch in großem Umfang wirtschaftlich. Gemeinsam erzeugen sie etwas, was traditionelle regelbasierte Automatisierung nie leisten konnte: adaptive Urteilsfähigkeit. Plattformen wie 1Platform integrieren dies bereits nativ in BI-Tools über ihre Nutzungsschicht. Agentenanalysen sind somit kein separates System mehr, sondern ein Standardverhalten der Plattformen, die Teams bereits nutzen.

Gartner prognostiziert, dass bis Ende 2026 40 % der Unternehmensanwendungen aufgabenspezifische KI-Agenten integrieren werden, gegenüber weniger als 5 % im Jahr 2025.
Für Analysten bedeutet das in der Praxis Folgendes: weniger Zeitaufwand für die Datenbeschaffung, mehr Zeit für deren Interpretation. Die Rolle wird nicht kleiner – sie verlagert sich in den vorgelagerten Prozess.
Herkömmliche Analyseprozesse haben ein Richtungsproblem. Daten fließen nur in eine Richtung – Erfassung, Transformation, Modellierung, Bereitstellung. Eine Erkenntnis landet in einem Dashboard, ein Mensch reagiert darauf, und was danach geschieht, verschwindet einfach. Das Ergebnis kehrt nie in das Modell zurück. Die nächste Vorhersage basiert auf denselben historischen Daten und berücksichtigt nicht, was die letzte Entscheidung tatsächlich bewirkt hat.
Die Entscheidungsfindung im geschlossenen Regelkreis gibt die Richtung vor. Jede Entscheidung wird zu einem eigenständigen Datenereignis – erfasst, kategorisiert und als Trainingssignal zurückgeführt. Das Modell lernt aus seinen eigenen Handlungen, nicht nur aus den Daten vor der Entscheidung. Die Genauigkeit steigert sich kontinuierlich. Der Datenfluss wird nicht mehr einseitig.
TL;DR
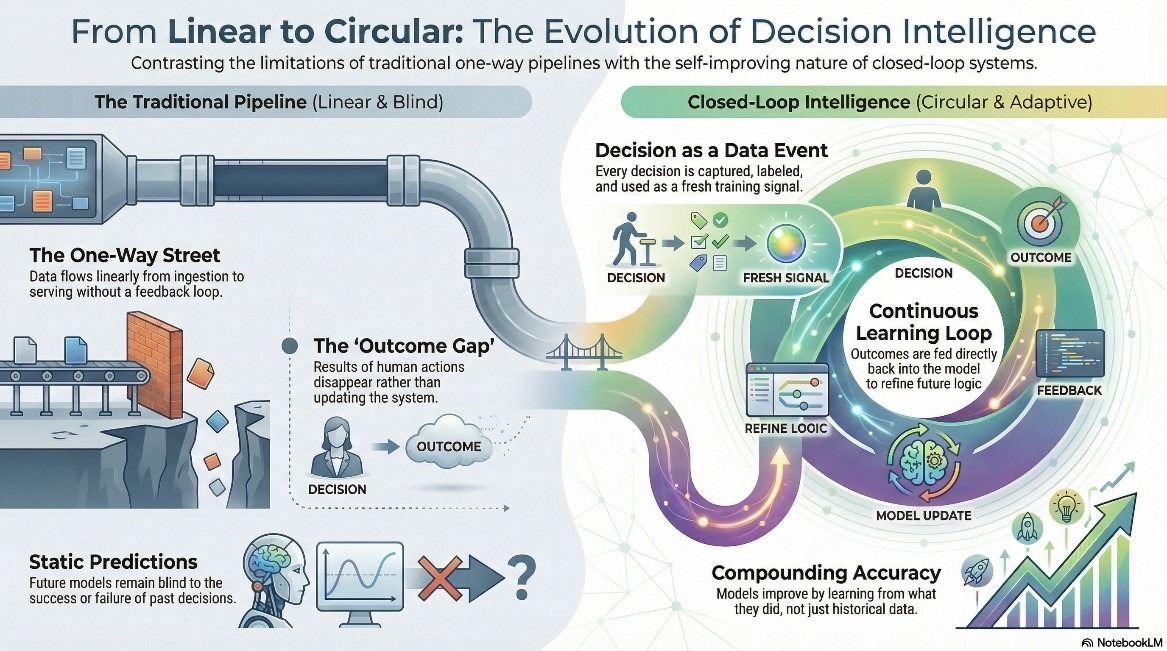
Für Datenteams entsteht dadurch eine neue Kategorie der Infrastrukturverantwortung. Ergebnisdaten sind nun eine eigenständige Größe – sie müssen wie jede Produktionsquelle modelliert, verwaltet und überwacht werden. Das klingt zunächst einfach, bis der Feedback-Mechanismus unbemerkt ausfällt. Ergebnisdaten treffen verspätet ein. Sie treffen falsch beschriftet ein. Manchmal treffen sie gar nicht ein. Jedes dieser Probleme führt zu Modellabweichungen, die deutlich schwieriger zu erkennen sind als ein fehlerhafter Datenerfassungsprozess – und 89 % der Verantwortlichen im Datenbereich, die KI produktiv einsetzen, haben bereits irreführende Ergebnisse aufgrund genau solcher Fehler in der vorgelagerten Infrastruktur erlebt.
Hier setzt die Architektur von 1Platform an und macht den geschlossenen Regelkreis nicht nur theoretisch, sondern operativ nutzbar. Data Nexus verwaltet den gesamten Datenbestand inklusive Ergebnissignalen, während Agenthood AI Entscheidungen innerhalb definierter Schwellenwerte trifft und jede Aktion und jedes Ergebnis in die Pipeline zurückschreibt. Abweichungen werden erkennbar. Entscheidungen werden nachvollziehbar. Der Feedback-Kreislauf wird als Infrastruktur behandelt – denn genau das ist er.
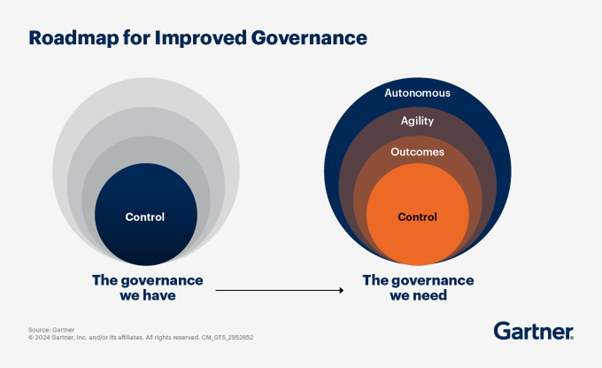
Die Datenverantwortung verlagert sich von der zentralen Entwicklung hin zu den Fachabteilungen – und die Architektur zieht endlich nach. Das Lakehouse vereinheitlichte Speicher und Rechenleistung. Was es nicht vereinheitlichen konnte, war die Datenverantwortung. Mit dem Wachstum von Organisationen ist der eigentliche Engpass nicht die Architektur, sondern das Governance-Vakuum, das entsteht, wenn Dutzende von Fachteams Daten ohne klare Verantwortlichkeit produzieren.
Das Data Mesh knüpft an das Lakehouse an. Anstatt alles auf einer zentralen Plattform eines einzelnen Teams zu bündeln, verteilt das Mesh die Zuständigkeit auf Domänenteams unter föderierter Governance. Das Lakehouse dient dabei als technische Basis, Delta Lake, Apache Iceberg und Apache Hudi ermöglichen die herstellerübergreifende Interoperabilität, und das Mesh bildet das darüberliegende Betriebsmodell. Datenverträge zwischen Produzenten und Konsumenten etablieren sich als praktischer Durchsetzungsmechanismus und machen SLAs von angestrebten Zielen zu operativen Verpflichtungen.
Der Markt für Data Meshes spiegelt wider, wie ernst Unternehmen dieses Thema nehmen: 1,5 Milliarden US-Dollar im Jahr 2024, mit Kurs auf 3,5 Milliarden US-Dollar bis 2030. Wenn Fachteams ihre Daten besitzen und dafür verantwortlich gemacht werden, werden KI-Modelle mit saubereren Eingabedaten trainiert, funktionsübergreifende Anfragen landen nicht mehr in der Entwicklungswarteschlange, und das Unternehmen erhält Antworten, die die tatsächlichen Gegebenheiten widerspiegeln.
Doch nur 18 % der Unternehmen verfügen über die nötige Governance-Reife, um dies erfolgreich umzusetzen, und 62 % nennen Governance weiterhin als größtes Hindernis für die KI-Einführung . Die Lücke liegt selten in der Architektur – vielmehr darin, ob Observability von Anfang an integriert ist und ob die Verantwortung für SLAs tatsächlich an die Fachteams übertragen wird. Eine föderierte Verantwortung ohne Konvergenzschicht tauscht lediglich einen Engpass gegen einen anderen. 1Platform schließt diese Lücke, indem es Datenmanagement, Entscheidungsintelligenz und agentenbasierte Ausführung in einer einzigen Governance-Schicht vereint, sodass verteilte Verantwortung die Analyseerfahrung nicht fragmentiert.
Harmonisierung von Data Mesh und DDH für einen globalen Marktführer im Bereich alkoholischer Getränke
SLMs sind nicht generalisierbar – das ist der Sinn der Sache. Die Feinabstimmung proprietärer Arbeitsabläufe wie Finanzabstimmung, klinische Dokumentation oder Ausnahmebehandlung in der Lieferkette erfordert umfangreiche, annotierte und domänenspezifische Trainingsdaten. Daten aus der Praxis liefern diese selten. Grenzfälle sind strukturell unterrepräsentiert, regulatorische Vorgaben schränken die für das Training nutzbaren Daten ein, und die Annotation im großen Maßstab ist teuer und zeitaufwendig.
Synthetische Daten sind die technische Lösung. Damit ist nun Folgendes möglich:
- Generieren Sie die Grenzfälle, die niemals in den Produktionsprotokollen erscheinen.
- Erstellen Sie gesetzeskonforme Trainingssets, ohne personenbezogene Daten zu berühren.
- Beschriftung in großem Umfang ohne menschliche Annotatoren.
Grand View Research prognostiziert für den Markt für KI-Trainingsdatensätze ein Volumen von 3,2 Milliarden US-Dollar im Jahr 2025, das bis 2033 auf 16,3 Milliarden US-Dollar anwachsen soll – wobei synthetische Daten mit einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von 30,5 % das am schnellsten wachsende Segment darstellen. Gartner geht davon aus, dass synthetische Daten bis 2030 reale Daten als primäre Quelle für KI-Trainingsdaten ablösen werden.
Für Datenteams eröffnet sich hier eine neue Verantwortungsebene. Synthetische Datenpipelines erfordern eine Validierung der Datenverteilung – generierte Daten, die die Varianz in der realen Welt nicht widerspiegeln, führen zu Modellen, die zwar die Evaluierung bestehen, aber im Produktivbetrieb unbemerkt versagen. Schemaabdeckung, Klassenbalance und Abweichungen zwischen synthetischen und realen Verteilungen müssen erfasst und überwacht werden. Die Qualitätsanforderungen sind dieselben wie bei jeder Produktionsdatenquelle. Der Unterschied besteht darin, dass das Datenteam nun nicht nur die Daten verwaltet, sondern auch die Daten generiert.
Organisationen, die dies richtig machen, behandeln die Generierung synthetischer Daten als eine erstklassige Ingenieurpraxis – versioniert, getestet, kontrolliert – und nicht als einen Vorverarbeitungsschritt, den jemand vor dem Modelltraining durchführt.
Aktualität, Schema, Volumen, Verteilung, Herkunft – entwickelt für BI-Dashboards. In agentengesteuerten Pipelines, in denen Daten autonome Entscheidungen steuern, muss die Beobachtbarkeit über traditionelle Standards hinausgehen.
Das Problem liegt in der vorgelagerten Datenverarbeitung. Salesforce berichtet, dass 89 % der führenden Unternehmen im Bereich Datenanalyse mit KI im Produktiveinsatz irreführende Ergebnisse erlebt haben. Die meisten Fehler entstehen nicht im Modell selbst, sondern in den Trainingsdaten. Dazu gehören Abweichungen zwischen Trainings- und Bereitstellungsdaten, Schemaänderungen, die zwar die Validierung bestehen, aber nachfolgende Logik beeinträchtigen, und verspätete Ergebnisdaten, die den Feedback-Loop stören.
Der 2026-Stack ergänzt die klassischen Observability-Ansätze um folgende Punkte: Überwachung der Feature-Verteilung zwischen Trainings- und Bereitstellungsumgebungen, Durchsetzung von Datenverträgen an den Schnittstellen zwischen Produzent und Konsument sowie Observability der Ergebnisdaten zur Schließung des Feedback-Kreislaufs. Teams, die lediglich die Modellschicht instrumentieren, behandeln nur die Symptome. Die Ursache liegt weiter oben.
Ein Modell kann präzise sein und dennoch unsteuerbar. Es gibt keine Rückschlüsse auf die Trainingsdaten. Die Entwicklung der Merkmale wird nicht dokumentiert. Es gibt keine Möglichkeit, Aufsichtsbehörden, Wirtschaftsprüfern oder Geschäftspartnern zu erklären, warum das System ein bestimmtes Ergebnis liefert. Im Jahr 2026 ist das keine Compliance-Lücke mehr – es ist ein Implementierungshindernis.
Der Wandel in den Datenteams besteht darin, dass die Governance in den Build-Prozess vorgelagert wird. Datenverträge werden definiert, bevor Pipelines live gehen, und nicht erst nach einem Fehler verhandelt. Qualitäts-SLAs werden vom datenproduzierenden Domänenteam verantwortet, nicht von einer zentralen Stelle, die sie im Nachhinein prüft. Trainingsdaten werden genauso versioniert und dokumentiert wie Produktionscode – denn wenn ein Modell nicht korrekt funktioniert, lautet die erste Frage immer: Mit welchen Daten wurde es trainiert?
 Gartner
Gartner Der EU-Gesetzentwurf zur künstlichen Intelligenz, der ab August 2026 gilt, formalisiert, was führende Datenteams bereits als Standard betrachten: Die Nachverfolgbarkeit der Datenherkunft von der Rohdatenquelle bis zum Modelloutput ist eine erstklassige Ingenieursleistung. Organisationen, die diesem Ansatz voraus sind, betreiben keinen zusätzlichen Verwaltungsaufwand – sie haben die Nachverfolgbarkeit lediglich vorgezogen und in die Architektur- und Pipeline-Planung integriert, wo sie nur einen Bruchteil der Kosten einer späteren Nachrüstung verursacht.
Die meisten Datenteams im Jahr 2026 stehen vor der Entscheidung, ob sie ihre KI-Investitionen entweder maximieren oder zunichtemachen. Der Unterschied liegt nicht im Budget oder in den Talenten. Entscheidend ist, ob die Dateninfrastruktur – die Pipelines, die Verträge, die Feedbackschleifen, die Governance – für autonome Entscheidungsfindung oder lediglich für das Reporting konzipiert wurde.
Die Prognosen von Gartner geben die Richtung klar vor. Bis 2028 wird der fragmentierte Datenmanagement-Markt zu einem einzigen Ökosystem rund um Data Fabric und GenAI konvergieren. Bis 2027 wird KI, die in Data-Engineering-Tools integriert ist, den manuellen Aufwand um 60 % reduzieren. Bis 2026 wird natürliche Sprache zur dominierenden Schnittstelle für die Datennutzung. Die Infrastruktur wird nicht mehr um KI herum aufgebaut, sondern von ihr neu gestaltet.
Die führenden Unternehmen leisten nicht mehr. Sie haben bereits früher die richtige Grundlage geschaffen. 1Platform von Polestar Analytics vereint Datenmanagement, Entscheidungsanalyse und operative Umsetzung in einer einzigen, kontrollierten Ebene – so wird die Diskrepanz zwischen den Aussagen der Daten und deren Nutzung durch das Unternehmen nicht länger zu einem Architekturproblem.