
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Anmerkung der Redaktion:
In diesem Artikel über Data Lakehouse beantworten wir die entscheidende Frage: Data Warehouse vs. Data Lakehouse vs. Data Lake? Wir geben einen kurzen Überblick über die Entstehung und die Hintergründe dieser Konzepte. Lesen Sie weiter, um die Feinheiten von Data Lakehouse im Vergleich zu Databricks und Fabric zu verstehen!
Sind Sie auch so genervt davon, dass alle über KI der Generation Z reden, obwohl Sie in Wirklichkeit nur das wahre Hindernis dahinter sehen? Die Daten. Der Beweis für das verworrene Datenökosystem ist die aktuelle Landschaft rund um Daten, maschinelles Lernen und KI, die in etwa so aussieht:
 Dankbar an Mattturk & Firstmark für diese hervorragende Recherche
Dankbar an Mattturk & Firstmark für diese hervorragende Recherche Kurz gesagt: Die MAD-Landschaft ist so chaotisch wie die verborgenen Schichten neuronaler Netze.
Aber da 72 % der Top-CEOs (laut IBM) angeben, dass der Wettbewerbsvorteil davon abhängt, wer über die fortschrittlichste generative KI und künstliche Intelligenz verfügt, und maschinelles Lernen für Unternehmen oberste Priorität hat (mehrere Berichte), halten wir es für wichtig, folgende Frage zu stellen: Sind Ihre Daten tatsächlich in der Lage, all dies zu unterstützen?
Um diese Frage zu beantworten, begeben wir uns auf eine Reise in die Vergangenheit der Datengeschichte, um zu sehen, wie sich die Datenbedürfnisse und die Anforderungen an das Datenmanagement entwickelt haben:
- Ära 1.0: Unternehmen wollten Erkenntnisse aus ihren Daten gewinnen und setzten daher Data Warehouses mit Schema-on-Write-Funktionalität ein, um Business Intelligence zu unterstützen. Doch mit der zunehmenden Menge unstrukturierter Datensätze, den Kosten für Spitzenlasten und dem steigenden Bedarf an komplexen Analysen traten Probleme auf. Denn keines der führenden ML-Systeme wie TensorFlow, PyTorch und XGBoost funktioniert optimal auf Data Warehouses. ML-Systeme müssen große Datensätze mithilfe komplexen, nicht-SQL-basierten Codes verarbeiten.
- Ära 2.0: Um das Auslagern von Rohdaten in kostengünstigen und offenen Formaten wie Parquet zu unterstützen und gleichzeitig Systeme zur Verarbeitung von Nicht-SQL-Code zu ermöglichen, traten wir in die Ära der Data Lakes mit Schema-on-Read-Architektur ein. Diese verloren jedoch die umfangreichen Datenverwaltungsfunktionen, die für ACID-Transaktionen, Indizierung usw. erforderlich sind und in Data Warehouses vorhanden waren.
- Ära 3.0: Die Kombination aus Data Lake und Data Warehouse – oder die zweistufige Architektur –, bei der ein Teil der Daten aus dem Data Lake per ETL in ein nachgelagertes Data Warehouse übertragen wird, um dort anschließend Analysen und Business-Intelligence-Anwendungen durchzuführen. Dies unterstützt zwar sowohl BI als auch KI, jedoch können die zusätzlichen ETL-Schritte komplexer sein, die Semantik, die SQL-Dialekte und die unterstützten Datentypen variieren. Zudem steigt die Wahrscheinlichkeit für Fehler und Bugs.
- Ära 4.0: Die aktuelle Ära des Data Lakehouse – die semantische Flexibilität und Speicherung eines Data Lakes mit der Berechnung und Bereitstellung eines Data Warehouse zu kombinieren, d. h. die Reibung zwischen Datennutzung und -erfassung zu beseitigen oder zu verringern.
Data Lakehouse ist eine hybride Datenspeicher- und -verarbeitungsplattform, die das Beste aus traditionellen Data-Lake- und Data-Warehousing-Technologien vereint: kostengünstiger Speicher in einem offenen Format, auf den eine Vielzahl von Systemen zugreifen kann, und leistungsstarke Management- und Optimierungsfunktionen.
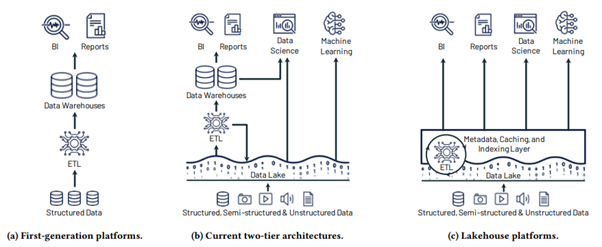 Die Entwicklung von einer zweistufigen Architektur zum Data Lakehouse>
Die Entwicklung von einer zweistufigen Architektur zum Data Lakehouse> Die Lakehouse-Architektur, wie sie beispielsweise bei Databricks und Microsoft Fabric zum Einsatz kommt, zielt darauf ab, die Kosten, den operativen Aufwand und die Komplexität der Datenübertragung für verschiedene Zwecke von Business Intelligence zu Künstlicher Intelligenz zu reduzieren.
Obwohl die Entwicklung von Data Lakehouses mit Uber und Netflix begann, nutzen mittlerweile die meisten Fortune-500-Unternehmen diese Plattform. Drei der wichtigsten Vorteile von Data Lakehouses sind:
- Weniger veraltete Daten: Rund 70-80 % der Analysten verwenden veraltete Daten – da alle Daten an einem Ort und in einem einheitlichen Format gespeichert werden, erhalten Sie mehr Kontrolle über Ihre Daten.
- Einheitliche Plattform für alle Datenanalysen: Data Lakehouses können einen Ort für Business Intelligence, SQL-Analysen und fortgeschrittenere Analysen, einschließlich maschinellem Lernen, bieten, da viele ML-Bibliotheken, wie TensorFlow und Spark MLlib, bereits Data-Lake-Dateiformate wie Parquet lesen können.
- Kostensenkung: Unternehmen können möglicherweise die doppelte Speicherung derselben Daten vermeiden, die häufig bei der Nutzung von Data Warehouse und Data Lake erforderlich ist. Zudem sind kommerzielle Data Warehouses oft auf proprietäre Formate beschränkt, was teuer sein kann – Data Lakehouses hingegen verwenden offene Formate.
Möchten Sie den aktuellen Zustand Ihrer Datenpipelines und Datenmanagementprozesse überprüfen? Vereinbaren Sie ein kostenloses Beratungsgespräch mit unseren Data-Engineering-Experten!
Holen Sie sich Expertenrat zum Datenmanagement Wir haben zwar bereits über alle drei gesprochen und darüber, wie die Entwicklung im Datenmanagement die Notwendigkeit mehrerer Systeme hervorgebracht hat, aber wir werden versuchen, sie so einfach wie möglich zu vergleichen.
Von der wachsenden Notwendigkeit, agil zu bleiben und sich schnell anzupassen – die Notwendigkeit, die Kosten mit dem zunehmenden Bedarf an Datenmanagement in Einklang zu bringen, wird mit dem Data Lakehouse ausgeglichen.
Unterschiede zwischen Data Warehouse, Data Lake und Data Lakehouse
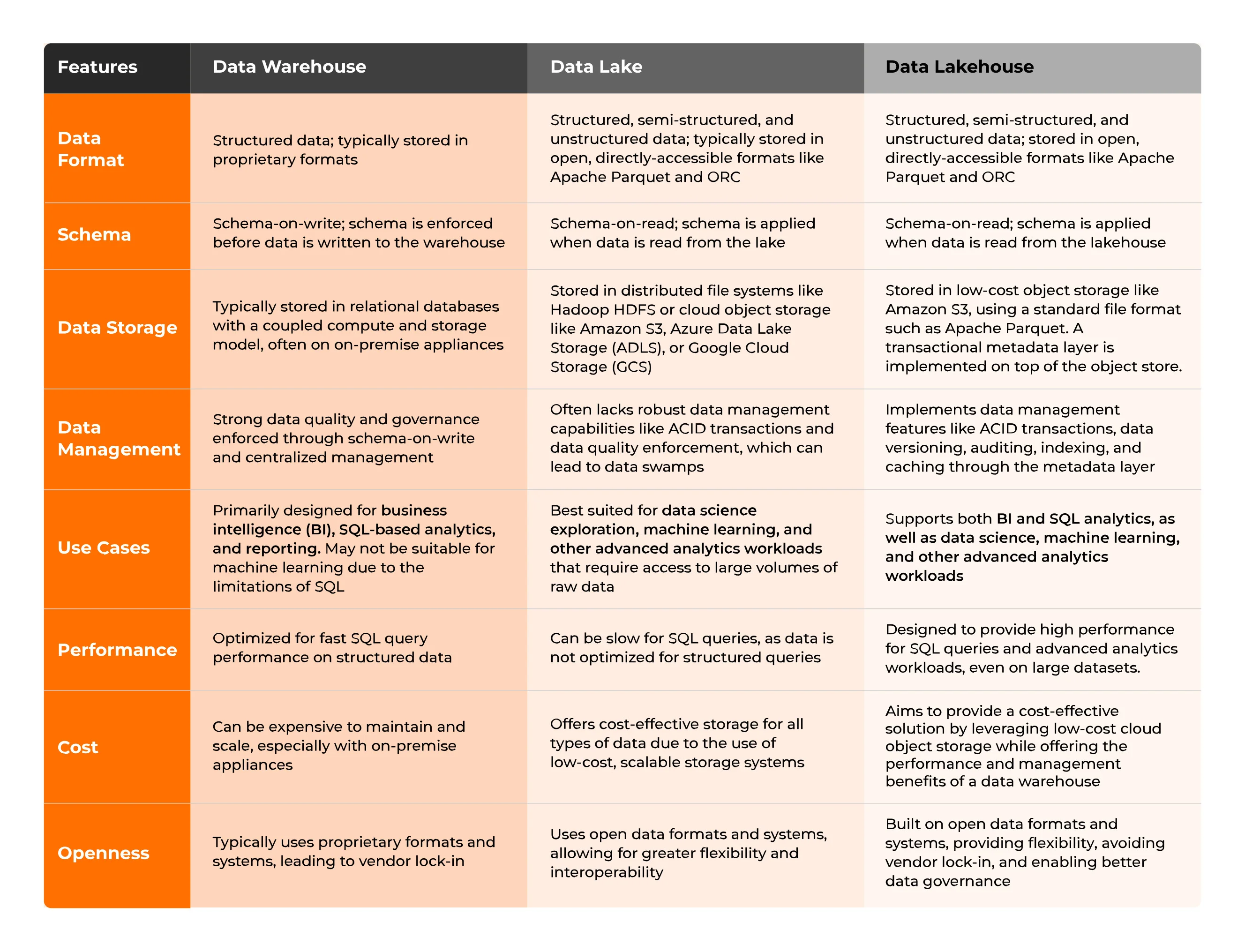 Die Unterschiede werden anhand verschiedener Parameter wie Datenformat, Schema, Offenheit, Leistung usw. aufgezeigt.
Die Unterschiede werden anhand verschiedener Parameter wie Datenformat, Schema, Offenheit, Leistung usw. aufgezeigt. Kurz gesagt: Data Lakehouse speichert Daten in einem ähnlichen Format wie Data Lakes, aber die Transaktionsmetadatenschicht definiert, welche Objekte zu einer Tabellenversion gehören, ähnlich wie bei einem Data Warehouse. Durch die größere Flexibilität der Interoperabilität von Data Lakes und die Unterstützung von ACID-Transaktionen wie bei Data Warehouses vereint Data Lakehouse die Konzepte beider Ansätze.
Der Zweck eines Data Lakehouse dürfte mittlerweile klar sein. Kommen wir also nun zum „Wie“. Eine typische Data-Lakehouse-Architektur besteht aus fünf Schichten:
- Datenerfassungsschicht: Sammelt Daten aus verschiedenen Quellen wie Transaktionsdaten, CRM-Systemen und NoSQL-Datenbanken und wandelt sie in ein speicherbares Format um.
- Speicherschicht: Üblicherweise werden die Daten in einem kostengünstigen Speicherformat gespeichert, also in typischen Cloud-Objektspeichern wie Amazon S3, Azure Data Lake Storage (ADLS) oder Google Cloud Storage (GCS) – in offenen, direkt zugänglichen Formaten wie Apache Parquet und ORC.
- Metadatenschicht: Diese für Data Lakehouse spezifische Schicht befindet sich über dem Data-Lake-Speicher. Sie verwaltet das Tabellenformat und die Dateien und ermöglicht Funktionen wie Schema-Durchsetzung, Datenversionierung, Auditierung usw. Beispiele für Metadatenschichten sind Delta Lake, Apache Hudi und Apache Iceberg.
- API-Schicht: Diese ermöglicht Datenabfragen mit SQL-APIs für traditionelle BI- und SQL-Analysen sowie deklarative DataFrame-APIs für Data-Science- und Machine-Learning-Workloads.
- Datennutzungsschicht: Von BI-Tools für Dashboards, Data Science und Machine Learning für die Datenmodellierung, Echtzeitanwendungen für Streaming-Daten und Datenaustausch zwischen Mitarbeitern – diese Schicht ermöglicht es Benutzern, Daten auf vielfältige Weise zu nutzen und mit ihnen zu interagieren.
 Hervorhebung der 5 Schichten einer Data-Lakehouse-Architektur
Hervorhebung der 5 Schichten einer Data-Lakehouse-Architektur
Mit dem Aufkommen von Microsoft Fabric und One Lake (Azure) hat sich das Data Lakehouse deutlich etabliert. Die „Curated Layer“ (in einer Microsoft Fabric-Architektur) kann bei Bedarf durch ein Data Warehouse ersetzt werden. Das Data Lakehouse lässt sich in Fabric mit den folgenden Optionen sehr einfach erstellen.
Weitere Details zur Azure Data Lakehouse-Architektur und zu den ersten Schritten finden Sie hier .
Databricks' Lakehouse macht es einfach, ETL-Pipelines zu automatisieren und zu orchestrieren. Bisher sind Sie wahrscheinlich schon einmal auf Azure Databricks (das üblicherweise mit Azure Synapse verwendet wird) oder deren Delta Live-Tabellen gestoßen, um die Komplexität von Infrastrukturmanagement, Aufgabenorchestrierung, Fehlerbehandlung usw. zu bewältigen.
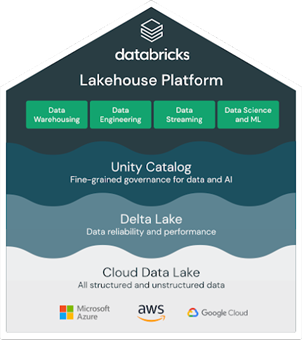 Quelle: Databricks
Quelle: Databricks Es gibt natürlich noch weitere Anbieter auf dem Markt, darunter Amazon Redshift, Google Cloud BigQuery, Salesforce Data Cloud, Apache Hudi und andere. Bei der Auswahl eines Anbieters sollten Sie vor allem folgende Aspekte berücksichtigen: Leistung, Kosten, Datenvielfalt, Skalierbarkeit, Integrationsmöglichkeiten und Governance.
Wir haben die Vorteile eines Data Lakehouse erkannt: Es ist wirtschaftlicher als die zweistufige Architektur, bietet eine vereinfachte Architektur bei der Datenaufbereitung, erhöht die Zuverlässigkeit durch die Reduzierung von Datenqualitätsproblemen und Duplikaten, verbessert die Governance durch Konsolidierung und bietet gleichzeitig eine höhere Skalierbarkeit für die Zukunft.
Da Unternehmen den Wert von Data Lakehouses erkennen, insbesondere im Zeitalter der KI, spielen sie eine zentrale Rolle bei datengestützten Entscheidungen und Innovationen. Die Zukunft von Data Lakehouses sieht vielversprechend aus, und ihre kontinuierliche Weiterentwicklung wird zweifellos die nächste Generation von Datenplattformen prägen – jetzt müssen Sie sie nur noch erfolgreich implementieren.
Sprechen Sie mit unseren Data-Engineering-Experten, um herauszufinden, wo und wie sich dies in Ihre Datenmanagementstrategie einfügt.