
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Anmerkung der Redaktion: In einer Zeit, in der es für fast alles ein Tool gibt – von Data Warehousing über Datenanalyse bis hin zu Business Intelligence – liegt die größte Herausforderung in der Integration all dieser Tools. Genau hier setzt Data Fabric an. Erfahren Sie in diesem Artikel mehr über Data Fabric, seine wichtigsten Funktionen und wie Sie damit beginnen können.
Was wäre, wenn es ein Team gäbe, das aus Spielern wie Michael Jordan, LeBron James, Magic Johnson, Larry Bird, Shaquille O'Neal, Kobe Bryant usw. bestünde? Schon der Gedanke daran klingt sehr aufregend, nicht wahr?
Stellen Sie sich nun dasselbe für Ihr Datenmanagement vor: Was wäre, wenn Sie Data Lake, Datenanalyse, KI und Visualisierungen kombinieren könnten? Genau das ermöglicht Microsoft Fabric . Wir werden die wichtigsten Akteure und ihre jeweiligen Beiträge genauer betrachten.
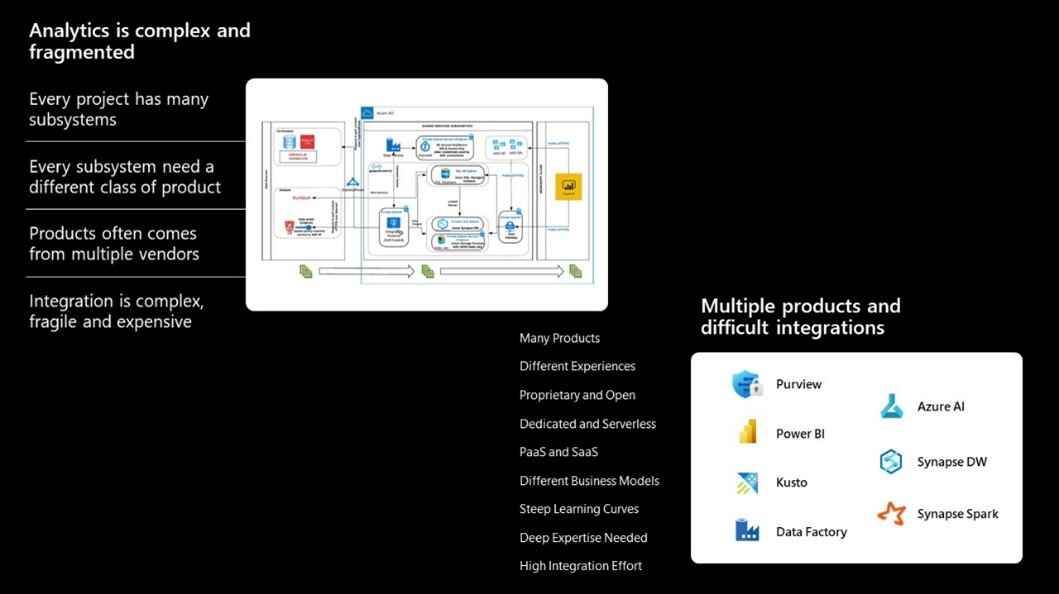
Es müssen nicht nur mehrere Plattformen für eine Reihe von Aktivitäten wie Data Warehousing, Transformation, Analyse und Visualisierung verwendet werden – sondern die komplexen Integrationen und Verbindungen zwischen ihnen erhöhen die Schwierigkeit zusätzlich.
Da Unternehmen zunehmend die Bedeutung von Daten erkennen und 91 % der Führungskräfte über verstärkte Investitionen in Daten und Analysen berichten¹, wird die Komplexität von Datenmanagement und -integration weiter zunehmen. Wie lässt sich dies vereinfachen?
Hier kommt Microsoft Fabric ins Spiel.
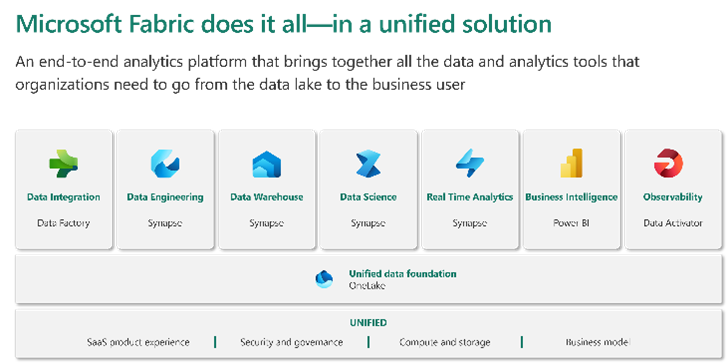
Microsoft definiert Fabric als eine All-in-One-Analyselösung für Unternehmen, die alles von der Datenmigration über Data Science und Echtzeitanalysen bis hin zu Business Intelligence abdeckt.
Satya Nadella zufolge ist es die beste Plattforminnovation seit der Einführung des SQL-Servers. Auch wenn es wohl noch zu früh ist, um das zu beurteilen, kann man es als dringend benötigten Eingriff in die zunehmende Komplexität der Integration betrachten.
Das ist nicht völlig neu. Für Kuroko no Basket-Fans ist es, als würde man das Team der Generation der Wunder (Vorpal Swords) gründen. Jedenfalls geht es darum, den erwarteten Geschäftswert zu erschließen und mit weniger Aufwand mehr zu erreichen, indem Ihre hybriden und Multi-Cloud-Datenlandschaften für schnellere, vernetzte Analysen zusammengeführt werden. Hier einige Vorteile der Nutzung von Microsoft Fabric als Ihr Datenökosystem:
100% SaaS-basiert
Die Idee hinter SaaS ist, Prozesse zu vereinfachen und Nutzern zugänglicher zu machen, die sich nicht um Hardware, Infrastruktur oder Administration kümmern müssen. Laut einer Gartner-Studie werden bis 2026 75 % der Unternehmen ein digitales Transformationsmodell einführen, das auf der Cloud als grundlegender Plattform basiert. Vereinfacht ausgedrückt: Microsoft Fabric wird so einfach zu nutzen sein wie die Einrichtung eines Power BI-Arbeitsbereichs.
Seezentriert
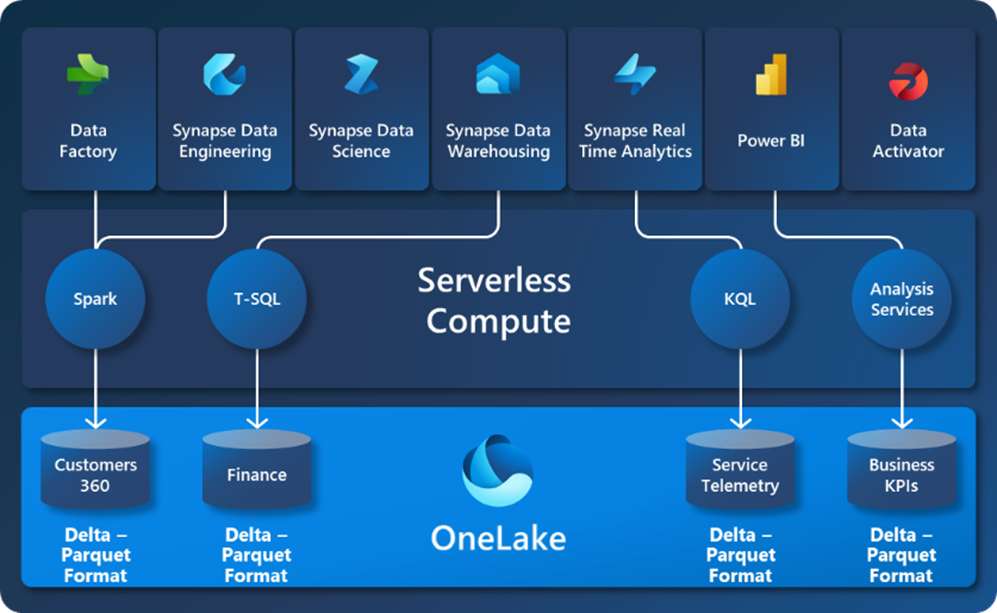
OneLake ist das Herzstück von Microsoft Fabric. Es dient als zentrales Repository für die Daten und Workloads von Fabric. Als Multi-Cloud-Data-Lake speichert es Daten aus Data Warehouses und anderen Data Lakes im einheitlichen Delta-Parquet-Format. Dadurch lassen sich alle Serverless-Compute-Engines innerhalb von Microsoft Fabric optimieren, und externe Ressourcen können Daten in einem leicht lesbaren Format in OneLake schreiben.
Die einfachste und gängigste Erklärung: OneLake ist das OneDrive für Ihre Unternehmensdaten. Sobald Daten im OneLake gespeichert sind, können alle Systeme direkt darauf zugreifen, ohne dass ein Import/Export erforderlich ist. Sie werden automatisch für die Auffindbarkeit, MIP-Labels, Datenherkunft, PII-Scans, Freigabe, Governance und Compliance indexiert.
Kostenreduzierung
Einige Gründe für den sprunghaften Anstieg der Kosten in der Enterprise-Cloud sind Rechenkosten, Datentransfer, Abrufkosten, Integrationskosten, Wartungskosten usw.
Mit One Lake und Data Fabric können Sie die Verschwendung von Rechenressourcen und den Integrationsaufwand erheblich reduzieren, da mehrere Anbieter über ein einziges Fenster verfügbar sind und die Rechenkapazität einfach von einer anderen Arbeitslast genutzt werden kann.
Sie können außerdem den Datenverkehr auf Ihrer Plattform reduzieren und dadurch Kosten senken sowie Ihre Datenorchestrierung vereinfachen. Da die Lösung SaaS-basiert ist, müssen Sie sich auch keine Gedanken um Datenintegration und -wartung machen.
Nutzer in allen Bereichen befähigen
Microsoft Fabric ist tief in Microsoft 365 integriert und ermöglicht Nutzern den Zugriff auf Daten in Echtzeit und von einem zentralen Ort aus. Darüber hinaus verfügt jede Rolle über personalisierte Analysetools, mit denen sie selbstständig Echtzeit-Einblicke gewinnen kann.
Mit einem Hub-and-Spoke-Datennetzansatz, der Arbeitsbereiche und Artefakte überblickt, können Sie Daten gemeinsam analysieren, kombinieren und transformieren, ohne dass Daten verschoben werden müssen.
Low-Code- und Profi-Entwickler
Neben der Möglichkeit, Code mit minimalem bis gar keinem Aufwand zu erstellen, bietet die Fabric-Umgebung Entwicklern einen echten Mehrwert. Spark-basierte Funktionen in VS Code, die Git-Integration und Notebooks mit verbesserten Kollaborationsfunktionen sind eine hervorragende Ergänzung. Im Vergleich zu Synapse, wo dies etwa 3 bis 4 Minuten dauert, benötigt Fabric für die Nutzung der Spark-Infrastruktur nur etwa 20 bis 30 Sekunden.
Die Idee hinter Low-Code ist, Endnutzer bei ihren Analysen zu unterstützen, ohne dass Synapse-/Spark-Entwickler benötigt werden . Das ist eine Win-Win-Situation: Entwickler können sich auf Daten, Programmierung und Administration konzentrieren, während Fachanwender ihre Analysen durchführen können.
KI-gestützt
Da Azure Open AI auf allen Ebenen in Microsoft Fabric integriert ist, können Benutzer die Leistungsfähigkeit generativer KI- Techniken überall dort nutzen, wo sie benötigt werden. Mit Azure Copilot können Benutzer Modelle für maschinelles Lernen und Datenpipelines erstellen, Code generieren und Ergebnisse in natürlicher Sprache visualisieren. Copilot kann beispielsweise Wörter in Datenflüsse und Datenpipelines umwandeln, um Benutzern die Integration von Daten aus beliebigen Quellen zu erleichtern. Benutzern, die Code schreiben, kann Copilot automatisch Code und ganze Funktionen in Echtzeit im Editor vorschlagen.
Nahtlose Integration
Fabric bietet ein einheitliches, zentrales Datenrepository (basierend auf ADLS Gen 2) mit Daten aus verschiedenen Quellen und Plattformen. Daten aus ADLS Gen 2, AWS S3 und Google Storage (demnächst verfügbar) lassen sich über eine Virtualisierungsfunktion namens „Shortcuts“ direkt verknüpfen.
Es lässt sich nicht nur in Data Lakes und Data Warehouses integrieren, sondern auch nahtlos in Microsoft 365-Anwendungen wie Excel, PowerPoint, Teams, Outlook usw. sowie in Analyseplattformen wie Power BI.
Da die gesamte Architektur und die Daten auf Microsoft-Sicherheit basieren und Governance somit selbstverständlich ist, gehen wir darauf nicht näher ein. Nachdem Sie nun die Vorteile von Microsoft Fabric kennen, betrachten wir die einzelnen Komponenten genauer und wie diese zusammen mit Fabric eine einheitliche Plattform bilden.
Schon vor Microsoft Fabric konnten Sie Datentransformation und -analyse mit verschiedenen Microsoft-Anwendungen durchführen, wie z. B. Datenintegration mit Data Factory, Datenverarbeitung mit Spark, Data Warehousing mit Synapse DW, Echtzeitanalysen mit Kusto, Data Science mit Azure ML und Business Intelligence mit Power BI.
Das Besondere an Fabric ist jedoch, dass man all dies erreichen und zusätzlich Observability hinzufügen kann, indem man drei etablierte Tools nutzt: Data Factory, Synapse und Power BI – kombiniert mit einem neuen Tool: Data Activator. Um bei unserer Basketball-Analogie zu bleiben: Wir bilden das „Dream Team“.
Azure Data Factory: Für eine moderne, codefreie und autonome ETL-Datenintegration wird Data Factory verwendet, um Daten aus verschiedenen Datenquellen wie Datenbanken, Data Warehouses, Data Lakes, Data Lakehouses, Echtzeitdaten usw. zu erfassen, aufzubereiten und zu transformieren. Dies geschieht in der Regel mit zwei primären Data-Factory-Implementierungen auf hoher Ebene: Datenflüssen (zur Nutzung von mehr als 300 Transformationen) und Datenpipelines (zur Nutzung der standardmäßig verfügbaren umfangreichen Datenorchestrierungsfunktionen).
Azure Synapse: Microsoft Fabric nutzt die Synapse-Umgebung für Data Engineering, Data Warehousing, Data Science und Echtzeitanalysen. Data Engineers können so Daten transformieren und Analysen mit Spark in Kombination mit einem SQL-basierten Data Warehouse durchführen, das Rechenleistung und Speicher vollständig trennt und somit die unabhängige Skalierung beider Komponenten ermöglicht. Echtzeit-Beobachtungsdaten liegen primär im JSON- oder Textformat mit dynamischen Schemas und der Kusto Query Language (KQL) vor. Im Bereich Data Science können Sie direkt von der Problemidentifizierung über die Datenaufbereitung mit Apache Spark und Python bis hin zur Erstellung massiv skalierbarer Machine-Learning-Pipelines mit SynapseML beginnen.
Power BI: Power BI ist allgemein bekannt . Bereits 2016 verzeichnete das Unternehmen über 5 Millionen Nutzer – mittlerweile dürfte diese Zahl exponentiell gestiegen sein. Mit Power BI können Anwender einen zentralen Datenhub für das gesamte Unternehmen aufbauen und skalieren, der mit aussagekräftigen Visualisierungen und Analysen ausgestattet ist. Sie können Daten verstehen, Berichte erstellen und Erkenntnisse mithilfe einer intuitiven Sprache austauschen sowie Verbindungen zwischen verschiedenen Microsoft 365-Apps herstellen.
Der Mehrwert von Copilot: Nutzer beschreiben einfach die gewünschten Visualisierungen und Erkenntnisse, und Copilot erledigt den Rest. Sie können Berichte in Sekundenschnelle erstellen und anpassen, DAX-Berechnungen generieren und bearbeiten, zusammenfassende Texte erstellen und Fragen zu ihren Daten stellen – alles in natürlicher Sprache.
Data Activator: Für die Echtzeit-Streamverarbeitung durch ein Erkennungssystem, das Ihr Team automatisch mit relevanten Informationen benachrichtigt. Data Activator (derzeit nur in der Vorschauphase) bietet Echtzeit-Datenüberwachung zur Koordination menschlicher und automatisierter Aktionen. So können Sie beispielsweise konfigurierbare Alarmbedingungen festlegen, die automatisch Reaktionen in Systemen wie Teams, Outlook usw. auslösen – alles ohne Programmierung. 
Bis 2026 werden 70 % der Unternehmen, die Observability erfolgreich einsetzen, kürzere Reaktionszeiten bei der Entscheidungsfindung erreichen und sich so Wettbewerbsvorteile sichern. Daher bietet sich eine große Chance, ausgereiftere Daten- und Analysefähigkeiten innerhalb und zwischen Ihrem Unternehmen aufzubauen.
Quelle: Top Strategic Technology Trends
Nachdem Sie all dies gelesen haben, mag Ihnen eine Frage in den Sinn kommen: Wenn all dies bereits vorher existierte (mit Ausnahme von Data Activator), wie unterscheidet sich Microsoft Fabric dann von bestehenden Plattformen wie Azure Synapse oder Data Factory?
Um das genauer zu erläutern, müssen wir über zwei Dinge sprechen: Erstens, wie sich das von Synapse unterscheidet, und zweitens, welche wichtige Rolle OneLake dabei spielt.
Weiterentwicklung von Azure Synapse
Anstatt beides getrennt zu betrachten, sollte Microsoft Fabric als Nachfolger von Synapse gesehen werden (genau wie Synapse der Nachfolger von SQL Data Warehouse war) .
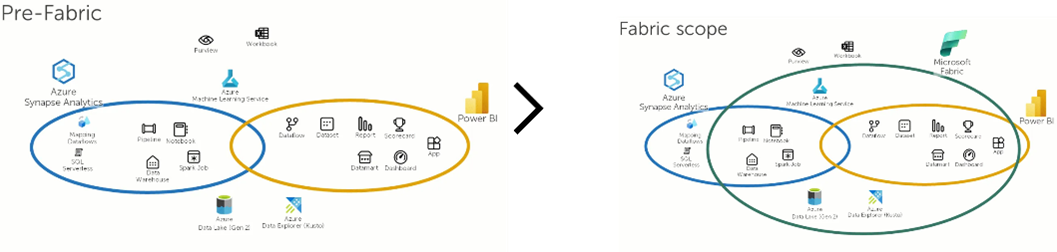
Hier ein direkter Vergleich der Funktionen von Synapse und Fabric:
| Vorhandene Synapsenfunktion | Stoffmerkmale |
|---|
| SQL Serverless | SQL-Endpunkt |
| SQL Dedicated (SQL Data Warehouse) | Lager |
| Apache Spark Pools | Managed Spark Pools |
| Apache Spark Notebooks | Notizbuch |
| Apache Spark Jobs | Spark Job Definition |
| Daten-Explorer (KQL-Skripte) | KQL-Abfragesatz |
| Data Explorer-Datenbank | KQL-Datenbank |
| Synapse Link | Noch nicht in Stoff erhältlich. |
| Synapse Studio | Wurde durch eine neue Power BI-basierte Benutzeroberfläche ersetzt. |
| Git-Integration | Git-Integration |
| ML / MLOps | Datenwissenschaft |
| Abbildung von Datenflüssen | Wird von Fabric nicht unterstützt. |
| Pipelines | Datenpipelines |
Wir haben erst vor Kurzem über OneLake gesprochen, aber wir wollten die Bedeutung hervorheben und darauf hinweisen, dass diese scheinbar kleine Änderung tatsächlich das Rückgrat von Microsoft Fabric (und Microsoft Purview) bildet.
Zu den wichtigsten Merkmalen gehören:
- Alle Daten sind in einem intuitiven hierarchischen Namensraum organisiert.
- Alle Workloads speichern ihre Daten automatisch in den OneLake-Workspace-Ordnern.
- Die Daten werden automatisch indiziert.
- Die Daten werden in einem einzigen gemeinsamen Format gespeichert – Delta Parquet –, für dessen Verwendung alle serverlosen Engines optimiert wurden.
- Sobald die Daten im Datensee gespeichert sind, können alle Engines direkt darauf zugreifen, ohne dass ein Import/Export erforderlich ist.
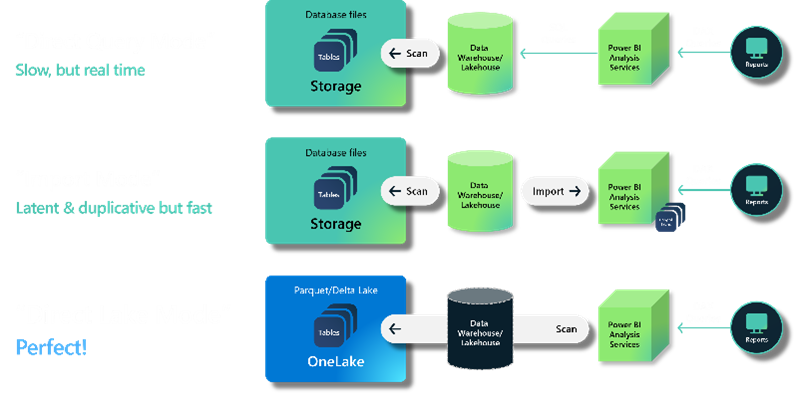
Quelle: Microsoft
Kurz gesagt, Sie können die Integrationsprobleme zwischen Anwendungen beseitigen und einen Data Lake erhalten, der alle Informationen enthält. Das Teilen von Daten in OneLake ist so einfach wie das Teilen von Dateien in OneDrive, wodurch die Notwendigkeit der Datenredundanz entfällt. Sollten benutzerdefinierte Daten oder Anwendungen benötigt werden, können diese dank der Unterstützung branchenüblicher APIs direkt aufgerufen werden.
Nun zur letzten Frage.
Wo soll ich anfangen?
Mit Power BI können Sie Microsoft Fabric ganz einfach 60 Tage lang kostenlos testen. In dieser Vorschauversion erhalten Sie Zugriff auf alle Fabric-Funktionen und -Funktionen mit bis zu 1 TB OneLake-Speicher. Weitere Informationen finden Sie hier. Oder schreiben Sie uns einfach eine Nachricht – wir helfen Ihnen gerne bei der Einrichtung Ihres Fabric-Prozesses und führen Sie durch alle Funktionen.
Zusammenfassung: Eine All-in-One-Analyselösung mit SaaS-Basis
Microsoft Fabric vereint Data Factory, Synapse Analytics, Data Explorer und Power BI zu einer einheitlichen Cloud-Umgebung. Die offene und kontrollierte Data-Lakehouse-Plattform bietet eine kosteneffiziente und leistungsoptimierte Lösung für Business-Intelligence-, Machine-Learning- und KI-Workloads jeder Größenordnung. Sie bildet die Grundlage für die Migration und Modernisierung bestehender Analyselösungen, seien es Data Appliances oder traditionelle Data Warehouses.
1. Gibt es ein direktes Upgrade/einen direkten Konnektor für den Wechsel von Synapse zu Fabric?
Nein, es gibt keinen direkten Upgrade-Pfad und keine Konnektoren, die Ihre Daten automatisch migrieren können. Um Ihre Synapse-Workloads auf Fabric zu übertragen, müssen Sie den Code manuell migrieren und anpassen. Dies umfasst unter anderem Notebooks, SQL-Skripte und Pipelines, damit diese ausgeführt werden können.
2. Wie handhabt Microsoft Fabric die Datenintegration aus mehreren Quellen?
Microsoft Fabric ermöglicht die nahtlose Integration verschiedenster Datenquellen, darunter Datenbanken, Data Lakes, Cloud-Dienste und sogar Echtzeit-Streaming-Daten, indem alle Daten in OneLake im Delta-Parquet-Format gespeichert werden. Dadurch können Benutzer und Anwendungen von einem zentralen Ort aus auf Daten zugreifen, wodurch der Import und Export entfällt.
3. Ist der Wechsel zu Microsoft Fabric für Azure Data-Kunden zwingend erforderlich?
Nein, Microsoft Fabric ist für Kunden mit einer bestehenden Azure-Datendienstinfrastruktur nicht zwingend erforderlich. Kunden können ihre bestehende Datenarchitektur und ihre Dienste zwar zu Microsoft Fabric migrieren – angesichts der Kostenvorteile und der gebotenen Effizienz ist ein Upgrade oder zumindest die Nutzung der Preview jedoch eine sinnvolle Option.