
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Weltweit sehen sich Organisationen täglich mit immer größeren Herausforderungen im Datenmanagement konfrontiert. Seit den Anfängen der Datennutzung in den 1980er-Jahren hat sich vieles verändert, insbesondere mit dem Aufkommen des Cloud Computing, das die Art und Weise, wie Daten genutzt, verarbeitet und verstanden werden, grundlegend verändert hat.
Heutzutage werden sekündlich riesige Datenmengen generiert; die Suche nach geeigneten Speicherlösungen für diese enormen Datenmengen ist daher von größter Wichtigkeit. Wenn es um die Datenverwaltung geht, ziehen Datenmanager und -experten den Einsatz von Data Warehouses oder Data Lakes als Speicherort in Betracht.
Was bedeuten diese Begriffe also, wodurch unterscheiden sie sich voneinander und welche Lösung ist die bessere für Ihr Unternehmen?
Hier gehen wir detailliert auf die Gemeinsamkeiten und Unterschiede zwischen Data Warehouses und Data Lakes ein, um einige Fragen für Unternehmen angesichts der Einschränkungen, mit denen sie in Bezug auf ihre Umgebung und ihr Budget konfrontiert sind, zu beantworten.
Ein Data Lake ist ein System oder Repository, in dem Daten unstrukturiert und in ihrem natürlichen/rohen Format gespeichert werden; d. h., sie werden nicht verarbeitet oder analysiert. Ein Data Lake ermöglicht es Unternehmen, große Mengen unterschiedlicher Datensätze zu speichern, ohne zuvor ein Modell erstellen zu müssen.
Es handelt sich in der Regel um einen zentralen Datenspeicher für alle Unternehmensdaten, einschließlich Rohdaten aus dem Quellsystem und transformierter Daten, die für Aufgaben wie Berichterstellung, Visualisierung, fortgeschrittene Analysen und maschinelles Lernen verwendet werden.
Man kann sich einen Data Lake wie ein großes Gewässer vorstellen, beispielsweise einen See in seinem natürlichen Zustand. Der Data Lake entsteht durch den Zufluss von Daten aus verschiedenen Quellen, und anschließend können verschiedene Nutzer auf den Data Lake zugreifen, ihn untersuchen und Stichproben entnehmen.
Ein Data Lake kann strukturierte Daten aus relationalen Datenbanken (Zeilen und Spalten), semistrukturierte Daten (CSV, Logs, XML, JSON), unstrukturierte Daten (E-Mails, Dokumente, PDFs) und Binärdaten (Bilder, Audio, Video) enthalten. Er ist besonders nützlich, wenn Datenmanager nach Möglichkeiten suchen, Daten aus verschiedenen Quellen in unterschiedlichen Formaten zu erfassen und zu speichern. In vielen Fällen gelten Data Lakes als kosteneffektiv und werden zur Speicherung von Daten für explorative Analysen eingesetzt.
Ein Data Warehouse hingegen führt all Ihre Daten zusammen und speichert sie organisiert und strukturiert. Es hilft, Daten an einem Ort zu konsolidieren, um daraus wertvolle Geschäftseinblicke zu gewinnen, die wiederum für bessere Geschäftsentscheidungen genutzt werden können – kurz gesagt, es hilft Ihnen, aus Ihren Daten einen Mehrwert zu generieren.
Sobald der Verwendungszweck der Daten identifiziert wurde, werden sie in ein Data Warehouse geladen, wodurch Unternehmen Einblicke durch analytische Dashboards, operative Berichte und/oder fortgeschrittene Analysen gewinnen können.
Data Warehousing verbessert schlichtweg die Qualität der Business Intelligence , sodass Führungskräfte Geschäftsentscheidungen nicht mehr auf der Grundlage begrenzter Daten oder ihres Bauchgefühls treffen müssen.
Da alle Arten von Daten an einem Ort gespeichert werden, ermöglichen Data Warehouses Unternehmen, schnell fundierte Entscheidungen zu wichtigen Initiativen zu treffen.
In letzter Zeit hat die Diskussion um Data Warehouses und Data Lakes zugenommen. Man versucht, die jeweiligen Vorteile zu verstehen und auch, wie beide im Unternehmensumfeld zusammenwirken können. Es geht nicht darum, sie gegeneinander auszuspielen, sondern vielmehr darum zu verstehen, wie sie zusammenarbeiten können.
LESEEMPFEHLUNG: DATA LAKES VS. DATA WAREHOUSE! WAS SIND DIE UNTERSCHIEDE?
Datenquellen: Datenquellen sind die Orte, an denen die Originaldaten – eine Vielzahl interner und externer Quellen – gespeichert sind. Dies können operative Datenquellen wie ERP- und CRM-Systeme usw. sein, aber auch Social-Media-Daten wie Website-Zugriffe, Beliebtheit von Inhalten usw., Daten von Drittanbietern wie demografische Daten, Umfragen, Volkszählungsdaten usw. oder auch unstrukturierte Daten wie Bilder, Videos usw.
Rohdaten/Landing Layer: Daten werden aus verschiedenen Quellsystemen extrahiert und im Rohdatenformat im Landing Layer des Data Lakes gespeichert. Der Landing Layer kennzeichnet die Daten für das jeweilige Quellsystem.
Standardisierungsschicht: Da Daten in unterschiedlichen Formaten vorliegen (relational, JSON, Binär usw.), müssen sie in das Zeilen- und/oder Spaltenformat standardisiert werden. Diese Schicht transformiert die Daten und wendet Geschäftslogik an.
Kuratierte Ebene: Diese Ebene wird gemäß den Geschäftsanforderungen erstellt und kann Data Marts für Reporting und Analysen enthalten. Je nachdem, wer auf die kuratierte Ebene zugreift, kann sie auch denormalisierte Daten für Data Scientists bereitstellen.
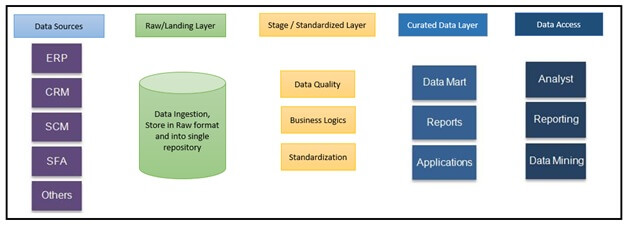
Im Gegensatz zu Data Warehouses folgt ein Data Lake dem ELT-Ansatz (Extract, Load, Transform). So funktioniert es:
Datenextraktion und -ladung: Die Extraktion der Quelldaten umfasst Datenextraktionsroutinen, die die Daten lesen und in einem bestimmten Format in einen Zielbereich übertragen. Der Datenextraktionsprozess ist in folgende Schritte unterteilt:
- Daten aus den Systemen lesen – Verbindung zu verschiedenen Systemen über Konnektoren oder API-Aufrufe herstellen, um auf die Daten zuzugreifen;
- Eingehende Quelldaten kennzeichnen – Eingehende Daten aus verschiedenen Quellsystemen werden gekennzeichnet, damit in Zukunft darauf verwiesen werden kann.
Datentransformation: Dies umfasst Datenbereinigung, Datenstandardisierung, Geschäftslogik usw.
Die Qualität (Perfektion, Gültigkeit und Genauigkeit) der Daten sollte quantifiziert und fundiert werden, damit die Entscheidungsträger die Zuverlässigkeit der Daten beurteilen und erst dann entscheiden können, welche Maßnahmen zu ergreifen sind.
Die aus verschiedenen Quellen stammenden Daten können in unterschiedlichen Formaten vorliegen, die in ein standardisiertes Tabellenformat mit Zeilen und Spalten umgewandelt werden, z. B. durch Konvertierung von JSON-Daten in Tabellen. Die Geschäftslogik wird entsprechend den Anforderungen angewendet. Die Daten werden in einer verwalteten Schicht gespeichert, von der aus sie für alle Beteiligten gemäß den Anforderungen zugänglich sind.
Stellen Sie sich die Datenarchitektur wie einen Shepherd's Pie oder eine Lasagne vor – mit mehreren Schichten. Jede Schicht spielt eine Rolle: Sie wandelt Rohdaten in wertvolle Daten um, die für Analysen und Business Intelligence genutzt werden können. Damit Rohdaten wertvoll werden, müssen sie geschichtet, sortiert, strukturiert und bereinigt werden. Erst dann gelangen die relevantesten Daten an die Spitze. Ein Data Warehouse ermöglicht genau diesen Prozess.
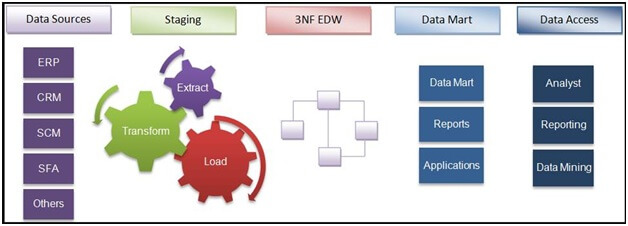
Datenquellen: Datenquellen sind die Orte, an denen die Originaldaten – verschiedene interne und externe Quellen – gespeichert sind. Dies können operative Datenquellen wie ERP- und CRM-Systeme, Social-Media-Daten wie Website-Zugriffe, Beliebtheit von Inhalten usw., Daten von Drittanbietern wie demografische Daten, Umfragen, Volkszählungsdaten usw. oder auch unstrukturierte Daten wie Bilder, Videos usw. sein.
Staging-Schicht: Daten müssen aus verschiedenen Quellsystemen extrahiert und anschließend in die Staging-Schicht übertragen werden. In EDW ist dies die Truncate Load Staging-Schicht, in der inkrementelle Daten aus dem Quellsystem extrahiert werden.
Transformation: Daten müssen gemäß Datenmodell und Geschäftslogik transformiert werden. Es ist wichtig zu beachten, dass die Transformationsschichten je nach System und Anforderung variieren können.
Laden: Die transformierten Daten müssen anschließend gemäß den Best Practices und Anforderungen in das EDW geladen werden.
Data Marts: Data Marts werden auf Basis von EDW erstellt, um den Berichtsanforderungen gerecht zu werden und eine erstklassige Performance beim Reporting zu erzielen.
Die besten Vorgehensweisen oder Entscheidungen, die für Data Warehouses getroffen werden sollten:
- Besitzen Sie ein Datenmodell?
- Erstelle ein Datenflussdiagramm
- Entscheiden Sie sich für zeitvariable Eigenschaften oder Attribute.
- Wenden Sie einen anerkannten Standard für die Data-Warehouse-Architektur gemäß den Anforderungen an, z. B. 3NF, Sternmodellierung usw.
- Erwägen Sie die Einführung einer agilen Data-Warehouse-Methodik.
Data-Warehouses folgen dem ETL-Verfahren (Extrahieren, Transformieren, Laden). So funktioniert es:
1) Datenextraktion: Die Extraktion der Quelldaten umfasst Datenextraktionsroutinen, die die Daten lesen, diese in ein Zwischenschema konvertieren und in einen temporären Arbeitsbereich verschieben, in dem die Daten in Zwischenschemas verwaltet werden. Der Datenextraktionsprozess ist in folgende Schritte unterteilt:
- Daten aus den Systemen lesen – Verbindung zu verschiedenen Systemen über Konnektoren oder API-Aufrufe herstellen, um auf die Daten zuzugreifen
- Die Ermittlung von Änderungen zur Identifizierung neuer Daten, d. h. der in das Data Warehouse zu ladenden Daten, reduziert die zu migrierende Datenmenge erheblich. Modifizierte Datenerfassungstechniken lassen sich in zwei Kategorien einteilen: statische und inkrementelle. Statische Datenerfassung bedeutet in der Regel die Erstellung einer Momentaufnahme der Daten zu einem bestimmten Zeitpunkt. In manchen Fällen kann der vollständige Datensatz wiederhergestellt werden, wahrscheinlich wird jedoch nur eine Teilmenge verwendet. Inkrementelle Datenerfassung hingegen ist ein zeitabhängiges Modell zur Erfassung von Änderungen an Betriebssystemen. Diese Technik eignet sich am besten, wenn die Datenänderung in einem bestimmten Zeitraum deutlich geringer ist als die Größe des Datensatzes. Drei verschiedene Techniken können angewendet werden: Erfassung, triggerbasierte Erfassung und Transaktionsprotokollerfassung.
- Der Generalisierungsschlüssel ist eine Schlüsselverwaltungsanwendung, die implementiert werden muss. Operative Eingabeschalter müssen in der Regel vor der Aufzeichnung umstrukturiert werden. Nur sehr selten bleibt ein Eingabeschlüssel beim Lesen in der Betriebsumgebung und beim Schreiben in die Data-Warehouse-Umgebung unverändert. In einfachen Fällen wird der Schlüsselstruktur ein Zeitelement hinzugefügt. In komplexen Fällen muss der gesamte Eingabeschlüssel einem neuen Hashing-Prozess unterzogen oder umstrukturiert werden.
- Zusammenführung von Datensätzen aus mehreren Quellen: In den meisten Data Warehouses stammen die Daten aus verschiedenen, unabhängigen Quellsystemen. In solchen Fällen ist die Einrichtung einer Zwischenspeicherumgebung für die Daten erforderlich.
2) Datentransformation: Dies ist einer der wichtigsten Prozesse im ETL-Prozess. Zur Datentransformation gehört auch die Datenbereinigung. Die Qualität (Perfektion, Validität und Genauigkeit) der Data-Warehouse-Daten muss quantifiziert und transparent dargestellt werden, damit Entscheidungsträger die Zuverlässigkeit der Daten beurteilen und erst dann über geeignete Maßnahmen entscheiden können.
Die gebräuchlichsten Arten von Bodendaten sind:
- Dummy-Werte
- Datenmangel
- Mehrzweckfelder
- Inkonsistente Daten
- Wiederverwendung von Primärschlüsseln
- Nicht eindeutige Kennungen
Zu den weiteren Datentransformationen gehören:
- Benennen Sie die Namen nach logischen und nicht nach technischen Kriterien um.
- Zusammenführung zweier Datensätze
- Denormalisierung der Dimensionen
3) Datenladen: Nach der Datentransformation folgt das Laden der Daten auf den Data-Warehouse-Server. Sobald die Daten im EDW vorliegen, werden spezifische Data Marts gemäß den Berichts- oder Geschäftsanforderungen erstellt.
Data Lakes und Data Warehouses sind zwei Seiten derselben Medaille – unterschiedliche Werkzeuge für unterschiedliche Zwecke, je nachdem, was ein Unternehmen erreichen will. Data Lakes speichern alle Daten, während Data Warehouses bereinigte, verarbeitete und strukturierte Daten speichern.
Data Lakes sind kostengünstig und relativ einfach zu verändern, während es schwieriger ist, Änderungen an der Struktur eines Data Warehouse vorzunehmen, einfach aufgrund der Anzahl der damit verbundenen Schichten und Prozesse.
Da Unternehmensdaten immer vielfältiger werden, haben Organisationen letztlich die Möglichkeit, das für sie am besten geeignete Modell auszuwählen, die funktionalen Aspekte von Data Warehouses und Data Lakes zu verstehen und auf ein Modell hinzuarbeiten, das die Vorteile beider Ansätze vereint.
Die rasante Entwicklung, mit der Unternehmen eine datenbasierte Strategie zur Gestaltung ihrer digitalen Transformation verfolgen, basiert auf Datenanalysen. Kompetente Datenmethoden kommen zum Einsatz, um die fehlenden Puzzleteile für Organisationen zu schließen, die mit Einschränkungen, Verzerrungen und Fehlern konfrontiert sind.
Bei der Implementierung von Data Warehouses und Data Lakes besteht jeweils die Möglichkeit, operative, historische und sogar Echtzeitdaten zu transformieren, um die Effizienz zu steigern, die Geschäftsleistung zu verbessern und letztendlich das Kundenerlebnis zu optimieren.
Während viele Organisationen noch immer damit zu kämpfen haben, mit Data Warehouses und Data Lakes zu experimentieren, ist es für Unternehmen mittlerweile eine Standardvoraussetzung, sich an die sich ständig weiterentwickelnde Welt der Datenanalyse anzupassen.
Insgesamt herrscht großer Optimismus hinsichtlich der Analytik in naher Zukunft; wir werden sehen, wie Organisationen aller Art und Größe sie in ihre täglichen Geschäftsabläufe integrieren.
Letztendlich hoffen wir bei Polestar , Organisationen branchenübergreifend die Macht der Daten zugänglich zu machen und ihnen dabei zu helfen, Milliarden von Datenpunkten und Datensätzen zu analysieren, um Echtzeit-Einblicke zu gewinnen und sie in die Lage zu versetzen, wichtige Entscheidungen für das Wachstum ihres Unternehmens zu treffen.
Bleiben Sie bei Ihren Lieblingsthemen auf dem Laufenden.