
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Low-Code/No-Code-Plattformen beheben Engpässe im Data Engineering, indem sie Integrationen vereinfachen, Transformationen automatisieren und Governance in eine einzige einheitliche Datenarchitektur einbetten.
- Warum haben sich Low-Code/No-Code (LCNC)-Plattformen von Workflow-Buildern zu unternehmenskritischen Dateninfrastrukturen entwickelt?
- Die vier versteckten Kosten, die Dateningenieure tragen, wenn sie auf unverbundene Datenplattformen anstatt auf einheitliche LCNC-Datenengineering-Lösungen setzen.
- Wie man den Transformationsengpass mit visuellen ETL-Pipelines beseitigt, die auf Low-Code/No-Code-Datenverarbeitungslösungen basieren.
- Die Architekturentscheidung, die darüber entscheidet, ob KI-Agenten Ihre Datenarchitektur beschleunigen oder umgehen.
Wenn Sie immer noch darüber nachdenken, mit Low-Code-No-Code-Plattformen (LCNC) zu experimentieren, weil Sie darin einen „aufkommenden Trend“ sehen, dann haben Sie es falsch verstanden.
Noch vor wenigen Jahren nutzten weniger als 25 % der neuen Unternehmensanwendungen Low-Code . Heute ist diese Zahl auf 80 % gestiegen. Was hat sich geändert? Low-Code-Plattformen dienen nicht mehr nur der Workflow-Erstellung. Wir haben uns von der Entwicklung von Codierungspipelines hin zur Orchestrierung intelligenter, selbststeuernder Systeme entwickelt (dank agentenbasierter KI ).
Engpässe im Daten-Engineering sind nichts Neues. Jede neue SaaS-Integration bedeutete wochenlange Entwicklung individueller Konnektoren. Oder Schemaänderungen, die Pipelines ohne Vorwarnung lahmlegten. Fachabteilungen warteten monatelang auf einfache Datentransformationen, weil alles manuelle Programmierung erforderte.
Daher begannen LCNC-Plattformen ursprünglich als Werkzeuge, um Bürgerentwickler mit abteilungsspezifischen Anwendungen auszustatten. Im Laufe der Zeit entwickelten sich einige zu Infrastrukturen auf Unternehmensebene, die komplexe Automatisierung, Datendemokratisierung und mittlerweile sogar KI-gestützte Orchestrierung ermöglichen.
Für Data Engineers hat sich Folgendes geändert: Anstatt für jede API eigene Konnektoren zu entwickeln, konfigurieren Sie vorgefertigte. Anstatt komplexe SQL-Abfragen für Standardtransformationen zu schreiben, nutzen Sie visuelle Oberflächen. Anstatt Schemaabweichungen manuell zu überwachen, übernehmen Plattformen dies automatisch. Sie konzentrieren sich auf komplexe Geschäftslogik anstatt auf wiederkehrende Integrationsarbeiten.
Heute sehen wir die Ergebnisse dieser Entwicklung. Dank Low-Code-Entwicklungsplattformen liefern 61 % der Nutzer erfolgreich individuelle Anwendungen termingerecht, im vereinbarten Umfang und innerhalb des Budgets. Low-Code hat zudem das Potenzial, die Softwareentwicklung um bis zu das Zehnfache zu beschleunigen.
Doch die meisten Organisationen übersehen Folgendes: Zu wissen, wohin sich die Branche entwickelt, bedeutet nichts, wenn man nicht weiß, wo man aktuell steht.
Reifegradmodell für Low-Code/No-Code: Wo steht Ihr Unternehmen?
Die meisten Unternehmen lassen sich einer von drei Reifestufen zuordnen:
Die Einsätze sind deshalb so wichtig, weil jede Ebene grundlegend unterschiedliche Strategien, Governance-Modelle und Risikoprofile erfordert.
Weißt du, wo du stehst? Dann ist es Zeit herauszufinden, wohin du gehst.
Starten Sie mit einer Low-Code-Datenverarbeitungsplattform.
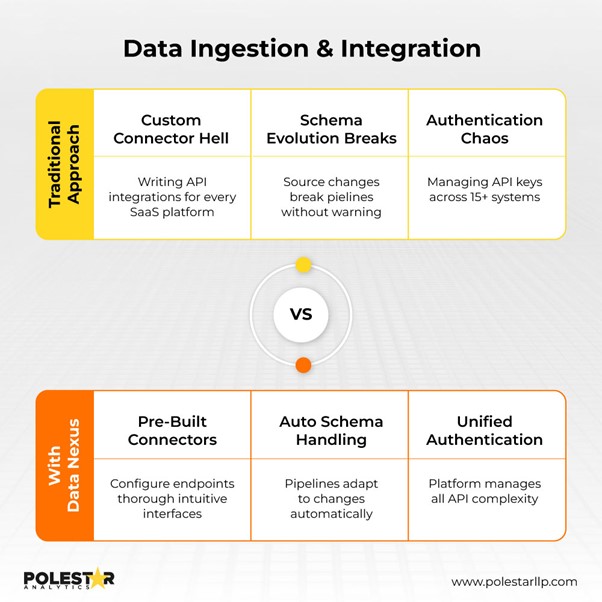
Erste Schritte mit Data Nexus Jeder Data Engineer kennt diese Realität: Was früher ein einfacher ETL-Job aus drei Systemen war, beinhaltet heute die Verwaltung von mehr als 15 APIs, von denen jede unterschiedliche Ratenbegrenzungen, Authentifizierungsschemata und Breaking Changes aufweist.
Hier erfahren Sie, was Sie für diese Komplexität bezahlen:
Die eigentlichen Kosten liegen nicht im SaaS-Abonnement, sondern im Entwicklungsaufwand. Jedes neue Tool erfordert die Entwicklung individueller Konnektoren, die Verwaltung des OAuth-Ablaufs und die kontinuierliche Überwachung von Schemaabweichungen. Der Wartungsaufwand für Ihre Pipeline steigt exponentiell, während Ihre Teamgröße gleich bleibt.
Technischer Realitätscheck:
- API-Ratenbegrenzungen: Die meisten SaaS-Plattformen beschränken die Anzahl der Anfragen auf 100–1000 pro Minute.
- Schema-Drift-Häufigkeit: APIs ändern sich innerhalb weniger Monate und führen so zu fehlerhaften Schemas.
- Authentifizierungsaufwand: Die Verwaltung von OAuth-Tokens verlängert die Entwicklungszeit (abhängig von der Komplexität des Projekts).
- Komplexität der Fehlerbehandlung: Benutzerdefinierte Konnektoren benötigen allein für die Wiederholungslogik über 200 Codezeilen.
Die Kosten technischer Schulden häufen sich schneller an, als man sie abbauen kann.
Data Nexus beseitigt diesen Integrationsaufwand. Mit Nexus verbinden Sie sich ohne individuelle Entwicklung mit beliebigen Systemen (Cloud-Datenbanken, ERP-Systemen, Flatfiles, APIs, Data Warehouses). Die Plattform bietet vorkonfigurierte Verbindungen, die Authentifizierung, Ratenbegrenzung und Schema-Weiterentwicklung automatisch übernehmen.
Hier der Zeitunterschied: Die Entwicklung von Code und Framework beschleunigt den Prozess um 70 % . Das bedeutet, dass bei der Aufgabenauswahl einfache Konfigurationen komplexe Integrationsentwicklung ersetzen. So können Sie sich auf die Datentransformationslogik konzentrieren, anstatt sich mit Verbindungsaufwand zu befassen.
Wo Transformation stattfindet, gibt es zwangsläufig einen Engpass. Und bei der Datentransformation kann es sich um eine simple Geschäftsfrage handeln wie: „Wie viel zahlen wir unseren Mitarbeitern in verschiedenen Städten?“ Drei Monate später kämpft man immer noch mit inkonsistenten Schemata und doppelten Datensätzen.
Was wie eine einfache Abfrage aussieht, entwickelt sich zu einem systemübergreifenden Integrationsprojekt – mit Schemaabgleich, Datendeduplizierung oder Qualitätsprüfung. Jede dieser Aufgaben erfordert Fachkenntnisse und einen erheblichen Entwicklungsaufwand.
Hier stößt die traditionelle Datenverarbeitung an ihre Grenzen:
- Unzählige SQL- und PySpark-Codes werden geschrieben, um Sonderfälle zu behandeln und Datensätze zu deduplizieren.
- Erstellung komplexer Zuordnungstabellen zum Abgleich heterogener Daten.
- Ein Neuanfang, wenn sich die geschäftlichen Bedürfnisse unweigerlich ändern.
LCNC-Plattformen lösen dieses Problem anders. Drag-and-Drop-Transformationen handhaben Standardoperationen wie Joins, Deduplizierung und Aggregation als Konfigurationsoptionen. Sie wenden Geschäftslogik über einfache Spaltenbedingungen an, ohne Code schreiben zu müssen. So können Sie Ihre Zeit für komplexe Geschäftslogik anstatt für wiederkehrende Datenaufbereitung verwenden .
PS: Benötigt fast 50-70 % der Zeit im Vergleich zur manuellen Bedienung.

Sie haben den Transformationsengpass gelöst und können nun die Frage beantworten: „Wie viel zahlen wir unseren Mitarbeitern in verschiedenen Städten?“ Doch hier liegt das eigentliche Problem: Welche Version von „John Smith“ ist die wahre?
Der Bedarf an analysefähigen oder KI-fähigen Daten ist höher denn je. Mit dem Data Nexus von 1Platform integrieren wir diese Ideologie analysefähiger Daten in einen durchgängigen, auf einer Medaillonarchitektur basierenden Prozess:
- Die Daten behalten in der Bronzeschicht jedes Systems ihr ursprüngliches Format.
- Einheitliche Entitätszuordnungen in der Silberschicht durch automatisierte Abgleichalgorithmen, die keine manuelle Datenverwaltung erfordern.
- Die Gold-Ebene bietet konsistente Ansichten für Analysen und bewahrt gleichzeitig die operativen Datenmodelle, die die Abteilungen tatsächlich verwenden.
Dieser Ansatz trägt dazu bei , die Gesamtsicht der Organisation auf ihre Daten zu vereinheitlichen und gleichzeitig ihre technischen Fähigkeiten zu verbessern.
Low Code, No Code Data Engineering könnte die Lösung sein, die Sie für Ihre Daten suchen!
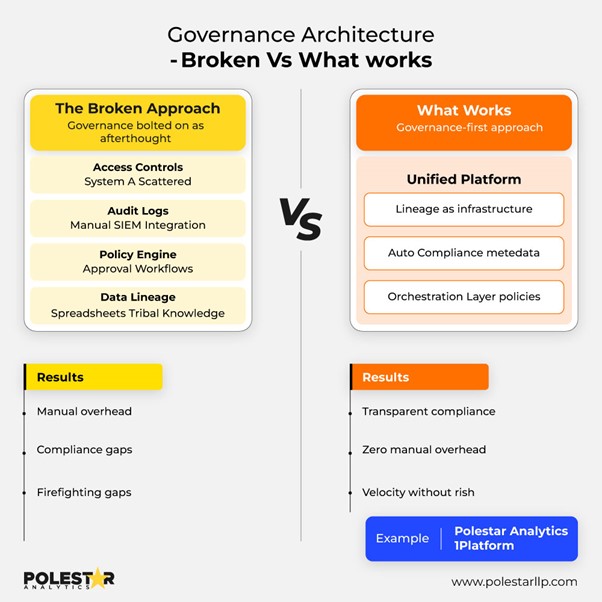
Data Governance macht aus Dateningenieuren Feuerwehrleute. Wenn Auditoren nach der Datenherkunft fragen, müssen sie hektisch Tabellenkalkulationen durchforsten und denjenigen ausfindig machen, der die Datenpipeline erstellt hat. DSGVO-Anfragen bedeuten die manuelle Suche in Dutzenden von Systemen. Fachabteilungen entwickeln inoffizielle Workflows, und die IT wird dann beschuldigt, wenn die Compliance-Abteilung diese entdeckt.
Herkömmliche Tools verteilen die Governance auf verschiedene Systeme. Zugriffskontrollen befinden sich an fünf verschiedenen Stellen. Audit-Logs erfordern eine manuelle Korrelation.
LCNC-Plattformen wie 1Platform zentralisieren dies mit:
- Herkunftsnachweis, der den vollständigen Datenfluss von der Quelle bis zu den Endberichten aufzeigt
- Zugriffskontrollen, die für alle Datenflüsse von einer einzigen Schnittstelle gelten
- Pipeline-Änderungen, die jedes Mal genehmigt werden
- Überwachungs-Dashboards, mit denen Sie den Status von Datenpipelines verfolgen können
Wenn Prüfer Fragen stellen, fragen Sie die Metadaten der Plattform ab, anstatt systemübergreifend Detektiv zu spielen.
Wir haben das Richtige für Ihre Datenverarbeitungsanforderungen gefunden.
Intelligente Plattformen machen Governance zu einem festen Bestandteil Ihrer Engineering-DNA – mit integrierter Herkunftsnachverfolgung, automatisierter Compliance und skalierbaren Zugriffskontrollen.
Entdecken Sie LCNC für Data Engineering Da 93 Prozent der IT-Führungskräfte die Absicht geäußert haben, innerhalb der nächsten zwei Jahre autonome KI-Agenten einzuführen, und fast die Hälfte dies bereits getan hat, ist Ihre Architekturentscheidung wichtiger denn je.
Es gibt nicht nur Datenagenten, die Schemaänderungen erkennen, Pipelines automatisch anpassen und Datenkonflikte ohne menschliches Eingreifen lösen.
Aber Sie benötigen auch saubere Daten, damit die branchenspezifischen Agenten mit maximaler Effizienz arbeiten können.
Ihre Datenanwendungen, KI-Agenten und Analysen müssen also auf einer gemeinsamen Grundlage funktionieren. Nicht nur API-Verbindungen zwischen den Tools – es bedarf einer echten architektonischen Einheit, in der die Daten vom Erfassen über die KI-Verarbeitung bis hin zu automatisierten Aktionen fließen, ohne Systemgrenzen zu überschreiten.
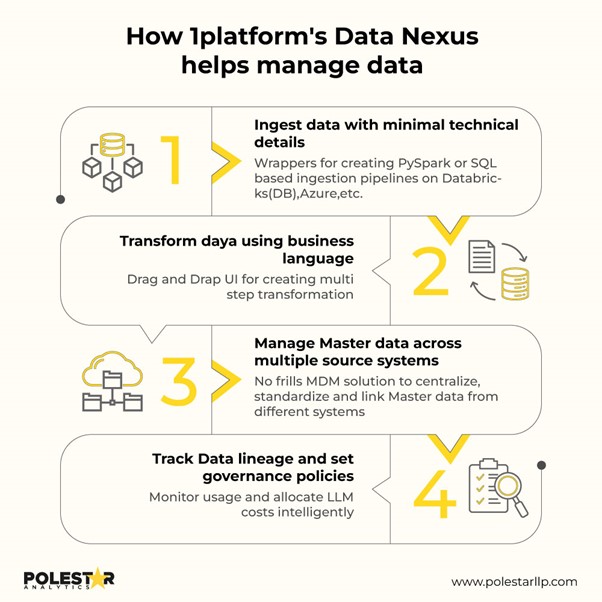 Wie 1Platforms Data Nexus bei der Datenverwaltung hilft
Wie 1Platforms Data Nexus bei der Datenverwaltung hilft Organisationen, die heute Data Nexus und 1Platform nutzen, schaffen die Infrastruktur für den autonomen Betrieb von morgen.
Der Unterschied liegt nicht in der Komplexität – sondern darin, ob Ihre Architektur Ihnen nützt oder schaden. Es geht darum, ob Sie auf einer einzigen Plattform aufbauen oder zehn verwalten.
Die Entscheidung liegt bei Ihnen.
Führungskräfte sollten Entscheidungszeiten, Integrationskomplexität und Entwicklungskapazitäten bewerten. Wenn Teams mehr Zeit mit der Wartung von Prozessen als mit der Gewinnung von Erkenntnissen verbringen, wird LCNC strategisch relevant. Es geht nicht darum, Entwickler zu ersetzen, sondern darum, Ressourcen von repetitiven Integrationsarbeiten auf wertschöpfende Geschäftslogik und KI-gestützte Innovationen umzuverteilen.
Das größte Risiko besteht in der Anhäufung technischer Schulden und der Verlangsamung von Entscheidungsprozessen. Mit dem Wachstum von Datenökosystemen führen unverbundene Tools zu einem exponentiellen Wartungsaufwand. Dies verzögert Erkenntnisse, mindert das Vertrauen in Daten und schwächt KI-Initiativen. Führungskräfte müssen die Einführung von LCNC nicht als reine Werkzeugwahl, sondern als Architekturentscheidung mit Auswirkungen auf die langfristige Skalierbarkeit betrachten.
Führungskräfte sollten Plattformen mit integrierter Governance, Datenherkunft und Zugriffskontrolle priorisieren, anstatt Governance nachträglich einzuführen. Die Entscheidung sollte auf einheitlicher Transparenz über alle Pipelines und Datenflüsse hinweg basieren. Die Integration von Governance in die Architektur gewährleistet, dass Compliance automatisch skaliert und nicht zu einem reaktiven, manuellen Aufwand wird.
CIOs und CDOs sollten der architektonischen Vereinheitlichung Vorrang vor der reinen Benutzerfreundlichkeit einräumen. Die Plattform muss einen durchgängigen Datenfluss – von der Datenerfassung bis zur KI-Aktivierung – innerhalb eines einzigen Ökosystems unterstützen. Die entscheidende Frage ist, ob die Plattform zukünftige agentenbasierte KI-Workflows ermöglicht oder eine weitere, voneinander getrennte Ebene im Daten-Stack schafft.