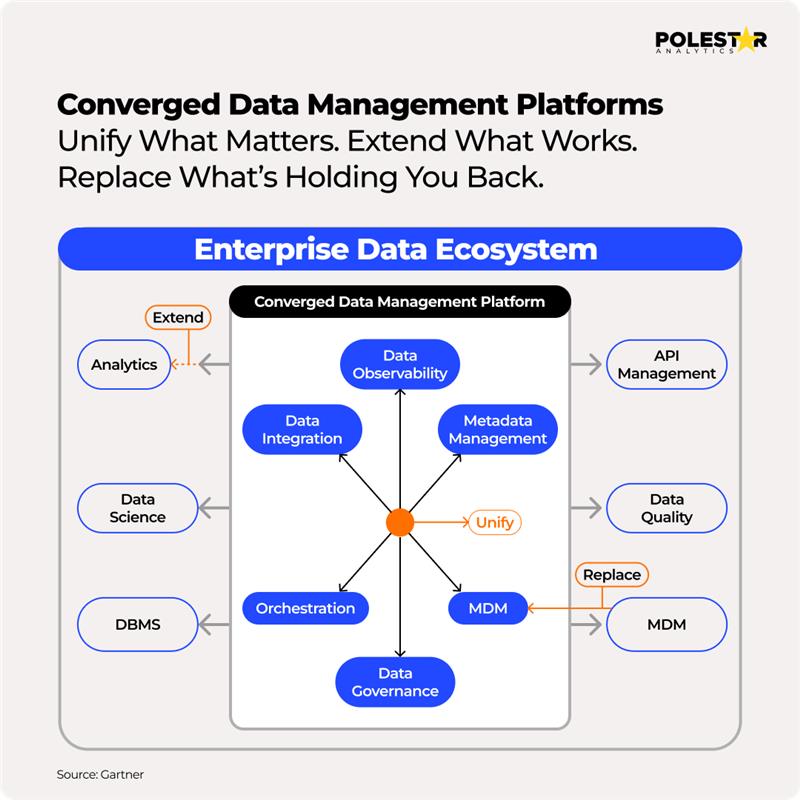
Eine konvergente Datenplattform ist eine einheitliche Dateninfrastruktur. Sie integriert Datenerfassung, -speicherung, -verwaltung, Qualitätskontrollen und -analyse in eine einzige Datenarchitektur. Sie ersetzt zudem voneinander getrennte und toolbasierte Datensysteme.
- End-to-End-Workflow-Koordination: Die Pipeline wurde automatisiert, sodass die Daten nahtlos fließen, ohne dass jedes System innerhalb einer vernetzten Umgebung manuell überwacht werden muss, um einen korrekten Datenfluss zu gewährleisten.
- Reduzierung der Tool-Flut: Durch eine einheitliche Benutzeroberfläche und die Entfernung unterschiedlicher Tools und Anwendungen kann sich der Geschäftsanwender auf die Erreichung seiner Ziele konzentrieren, anstatt mit einer Vielzahl sich überschneidender Anwendungen und Lösungen jonglieren zu müssen.
- Schnellerer Zugang zu verwertbaren Daten: Dank des vollständigen Einblicks in alle im Unternehmen verfügbaren Informationen können schnellere und fundiertere Entscheidungen getroffen werden, und Daten stehen für KI-Initiativen schneller zur Verfügung.
Schicht 1: Governance- und Datenreferenzschicht (Grundlage)
Diese grundlegende Schicht schafft Ihr Datenökosystem als „einzige Datenquelle“ durch:
- Das Metadatenregister ist im Wesentlichen ein Informationsspeicher, der den Benutzern eine Zusammenfassung der Datenquellen, Speicherorte, Inhalte und des Nutzens bietet.
- Das Pipeline-Management dient dazu, zu steuern, wie Komponenten miteinander verbunden werden, um Daten innerhalb des Ökosystems zu übertragen und zu verändern.
- Operative Steuerung: Überwachung, Benachrichtigungen und Fehlerprotokollierung über alle Pipelines hinweg.
Schicht 2: Datenanreicherungsschicht (Intelligenz)
Diese Ebene wandelt Rohdaten in einen nützlichen Nutzen um:
- ML-gestützte Optimierung: Mithilfe von Modellen des maschinellen Lernens und statistischen Berechnungen werden Erkenntnisse, Warnmeldungen und wichtige Indikatoren generiert. Dies trägt zu einer besseren Entscheidungsfindung bei.
- Verbesserungen der Benutzerfreundlichkeit: Änderungen und Verbesserungen der Datenqualität sowie die Hinzufügung von Bedeutung bereiten die Daten für die Verwendung durch menschliche Benutzer und KI-Systeme vor.
Ebene 3: Engagement- und Interaktionsebene (Erlebnis)
Diese oberste Ebene bietet benutzerfreundlichen Zugriff mit:
- Personabasierte Visualisierung: Bietet eine Benutzeroberfläche, die auf Dateningenieure, Datenanalysten und Führungskräfte innerhalb des Unternehmens zugeschnitten ist.
- Semantische Suche: Fragen in natürlicher Sprache, die relevante Datenprodukte anzeigen.
- Self-Service-Analytics: Eine Lösung für Geschäftsanwender, mit der sie Daten analysieren können, ohne auf die kontinuierliche Unterstützung der Informationstechnologie angewiesen zu sein.
- Intelligentere KI durch kontrollierten Zugriff. Es bietet KI-Systemen vollständige Kontexttransparenz, konsistente Semantik und Echtzeitdaten über Datensilos hinweg. Laut einer Gartner-Umfrage entwickeln 61 % der Unternehmen ihr D&A-Betriebsmodell speziell für KI weiter und treiben so die Entwicklung von der Problemerkennung hin zu umsetzbaren Lösungen voran.
- Steigert die betriebliche Effizienz im großen Maßstab: Monitoring, CI/CD und Konnektivität werden in einem Dashboard vereint. Dadurch entfällt die Notwendigkeit individueller Integrationen und Schulungen für verschiedene Tools. Zudem wird die Wertschöpfung durch sichere, proaktive Workflows beschleunigt.
- Strategische Transformation von Datenteams: Datenexperten können dadurch Fehlersuche und Datenabgleich vermeiden. Um Mehrwert für das gesamte Unternehmen zu generieren, können sie sich dann auf KI-Innovationen, Datenprodukte und Geschäftspartnerschaften konzentrieren.
Polestar Analytics' 1Platform beseitigt die Fragmentierung durch die Integration von Azure, AWS, GCP, Databricks und Snowflake in ein einziges, verwaltetes System – Datenverschiebungen sind nicht erforderlich. Technische Teams behalten ihre Flexibilität. Geschäftsanwender nutzen benutzerfreundliche Low-Code-/No-Code-Oberflächen mit integrierter Governance für einheitliche Richtlinien über alle Ökosysteme hinweg.
Mehr dazu im Blog der Converged Data Platform.