
Vat dit blogbericht samen met:
- Welke Databricks-gebruiksscenario's voor bedrijven leveren het snelste en meest meetbare rendement op investering (ROI) op?
- Hoe de architectuur van het Databricks Data Intelligence Platform streaming-, batch- en AI-workloads binnen één stack verwerkt.
- Waarom governance (en niet alleen rekenkracht) de doorslaggevende factor is voor de meeste Databricks AI-toepassingen in gereguleerde sectoren.
Slechts ongeveer 48% van de AI-projecten komt van prototype naar productie.
Niet omdat de modellen slecht zijn, maar omdat de data-infrastructuur die eraan ten grondslag ligt, nooit is ontworpen om ze te ondersteunen.
Het Databricks Data Intelligence Platform is uitgegroeid tot de architectuur bij uitstek voor bedrijven die deze kloof willen dichten. Het is ontworpen om te verwerken wat gefragmenteerde toolchains niet aankunnen: batchverwerking en streaming in dezelfde omgeving, governance en rekenkracht op hetzelfde platform, en AI-workloads die draaien bovenop dezelfde datalaag die de dagelijkse bedrijfsvoering ondersteunt.
Maar het platform levert niet vanzelf resultaten op. De bedrijven die daadwerkelijk waarde halen uit de data-intelligentie van Databricks zijn de bedrijven die het implementeren met een architectonische discipline — door te begrijpen voor welke gebruiksscenario's het echt geschikt is, wat de werkelijke faalscenario's zijn en welke governancebeslissingen genomen moeten worden voordat er ook maar één pipeline wordt uitgevoerd.
De timing is geen toeval. Drie krachten komen gelijktijdig samen binnen organisaties die zich bezighouden met bedrijfsdata.
- De hoeveelheid en verscheidenheid aan gegevens die organisaties moeten verwerken, overstijgt de mogelijkheden van traditionele datawarehouse-architecturen.
- Initiatieven op het gebied van AI en machine learning zijn verschoven van experimenteel naar prioriteit op bestuursniveau. Dit zet druk op de ontwikkeling van een infrastructuur die deze initiatieven in een productieomgeving kan ondersteunen.
- Door de strengere regelgeving rondom data-toegang, herkomst en het beheer van AI-modellen, vormen ongereguleerde dataomgevingen niet langer slechts een technisch ongemak, maar een juridisch en reputatieschadelijk risico.
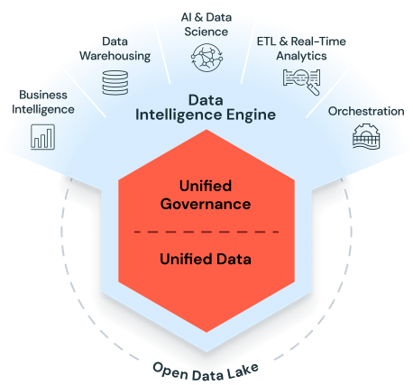 Bron: Het Databricks Data Intelligence Platform
Bron: Het Databricks Data Intelligence Platform Weet je dat?
Ondernemingen die modernisering uitstellen, staan niet stil, maar lopen achter op organisaties die de voordelen van een uniforme data-infrastructuur al volop benutten.
De architectuur van het Databricks Data Intelligence Platform pakt al deze drie uitdagingen aan binnen één enkele stack. Het Lakehouse-model elimineert de structurele scheiding tussen data lakes en data warehouses. Unity Catalog biedt uniform beheer voor data, analyses en AI-assets. En de rekenlaag van het platform – mits correct geconfigureerd – schaalt mee met alles, van historische batchverwerking tot IoT-streaming met millisecondenrespons. De onderstaande use cases illustreren hoe dit eruitziet in de praktijk bij echte bedrijfsproblemen.
Ontdek de migratiepatronen die succesvolle Unity Catalog-implementaties onderscheiden van mislukte!
Bekijk de succespatronen Als mensen het over modernisering hebben, vergelijken ze het bijna altijd met een 'lift-and-shift'-alternatief. Daarin slaan ze de plank mis.
De meest voorkomende en direct impactvolle toepassing van Databricks voor bedrijven is het samenvoegen van gefragmenteerde data-infrastructuren tot één centraal, beheerd data lake. De meeste grote organisaties gebruiken niet één dataplatform, maar meerdere: een verouderd on-premises datawarehouse, een cloudgebaseerde objectopslag die als ad-hoc data lake fungeert, een aparte analyseomgeving en een losgekoppelde machine learning-werkruimte. Elk van deze platforms is gebouwd om een specifiek probleem op een specifiek moment op te lossen. Samen zorgen ze voor vertraging in rapportage, inconsistentie in data en een engineeringteam dat meer tijd besteedt aan onderhoud dan aan waardecreatie.
De architectuur van het Databricks Data Intelligence Platform lost dit op door middel van de medaillonarchitectuur : een gelaagde aanpak die gegevens structureert in:
- brons (onbewerkt),
- zilver (gereinigd en gevalideerd),
- en gouden (geaggregeerde, bedrijfsklare) zones.
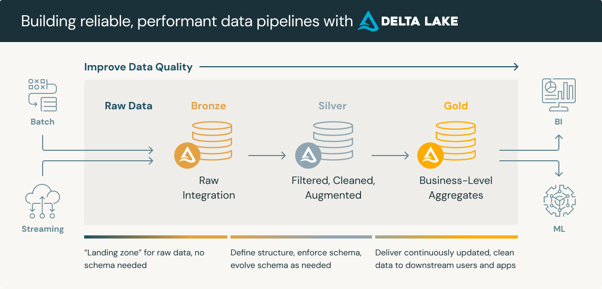 Bron: Databricks
Bron: Databricks Delta Lake bevindt zich onder alle drie de lagen en biedt ACID-transacties, schemahandhaving en time-travel-functionaliteit die traditionele data lakes niet kunnen bieden. Het resultaat is één betrouwbare bron die zowel operationele rapportage als AI-workloads ondersteunt, zonder duplicatie of extra kosten voor reconciliatie.
De meest voorkomende oorzaak van problemen in dit gebruiksscenario is het beheer van de computerkosten. Bedrijven die voor het eerst overstappen op Databricks onderschatten vaak de kosten die ontstaan door interactieve, multifunctionele computerclusters die zonder automatische beëindigingsbeleid blijven draaien. De oplossing is architectonisch, niet reactief: standaardiseer op jobclusters voor geautomatiseerde workloads, dwing automatische beëindiging af op het niveau van de infrastructuur als code met behulp vanTerraform , en behandel clusterbeheer vanaf dag één als een financiële controle in plaats van een configuratiedetail dat pas wordt aangepakt nadat de kosten zijn gestegen.
Ontdek wat een volledige modernisering van uw dataomgeving precies inhoudt → Migreer en moderniseer uw dataomgeving
Bekijk wat er inbegrepen is. Realtime streaming is waar de architectuur van het Databricks Data Intelligence Platform zich het meest zichtbaar onderscheidt van traditionele benaderingen – en waar de gevolgen van een verkeerde implementatie het meest direct voelbaar zijn. Voor de productie, logistiek, nutsbedrijven en elke andere sector die afhankelijk is van fysieke activiteiten, is de mogelijkheid om te reageren op data in beweging in plaats van op data in rust geen technische voorkeur. Het is het verschil tussen het voorkomen van een storing en het reageren op een storing.
Voorspellend onderhoud, mogelijk gemaakt door realtime dataverwerking, kan de stilstandtijd van machines met 30 tot 50% verminderen en de levensduur van apparatuur met 20 tot 40% verlengen. Het knelpunt in de meeste organisaties is niet de beschikbaarheid van sensorgegevens, maar de latentie in de dataverwerking!
De grootste architectonische uitdaging bij industriële IoT-implementaties is het naast elkaar bestaan van fundamenteel verschillende gegevenstypen: hoogfrequente sensorstromen die in milliseconden worden gemeten, en trage ERP- of MES-batchrecords die dagelijks of elk uur worden bijgewerkt. Traditionele ETL-systemen waren ontworpen voor het een of het ander. Het Databricks Data Intelligence Platform is ontworpen om beide tegelijkertijd te verwerken, maar de implementatieaanpak bepaalt of dit potentieel ook daadwerkelijk wordt benut.
Het cruciale beslissingspunt ligt tussen handmatige PySpark structured streaming en Delta Live Tables (DLT) . Handmatige streamingtaken vereisen dat engineers expliciet elke mogelijke fout definiëren en onderhouden – checkpointbeheer, statusherstel, afhandeling van schema-evolutie. Op grote schaal, met meerdere gelijktijdige sensorfeeds, wordt dit een kwetsbare en kostbare onderhoudslast. Delta Live Tables verplaatst deze last naar het platform zelf. Engineers definiëren de gewenste status van de data; DLT beheert automatisch de afhankelijkheidsafhandeling, foutafhandeling, herhaalpogingen en statuscontrole.
Ontdek hoe 1Platform native draait op het Databricks Data Intelligence Platform.
Bekijk het in actie. Organisaties die declaratieve pipeline-frameworks gebruiken, melden een reductie tot wel 60% in de onderhoudskosten van hun pipelines in vergelijking met organisaties die handmatig gecodeerde streamingjobs gebruiken. De gewonnen ontwikkeltijd vertaalt zich direct in snellere iteraties op de daarbovenliggende analyse- en AI-lagen.
Het praktische resultaat van een goed geïmplementeerde DLT-architectuur in industriële omgevingen is een datapipeline die hoogfrequente sensorgegevens kan verwerken, deze kan koppelen aan contextuele ERP-records en bruikbare signalen voor voorspellend onderhoud kan genereren – dit alles binnen een minuut. De operationele verschuiving die dit mogelijk maakt, is aanzienlijk: van reactieve incidentrespons naar proactieve interventie, vóórdat een storing optreedt in plaats van erna.
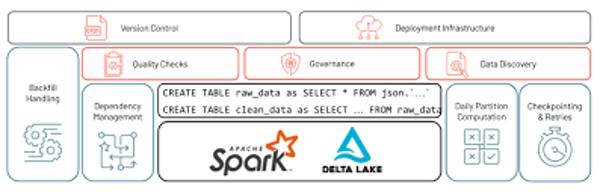 Bron: Databricks
Bron: Databricks Ontdek hoe modernisering veel verder reikt dan de migratiefase → Wat komt er na datamigratie?
Ontdek de volgende fase Generatieve AI op bedrijfseigen data is de categorie met het grootste potentieel en het hoogste risico binnen de AI-toepassingen van Databricks. De commerciële mogelijkheden zijn reëel: het opvragen van ongestructureerde documenten in natuurlijke taal, AI-ondersteunde compliance-controles, contractinformatie en co-piloten voor analisten die de afhankelijkheid van SQL voor zakelijke gebruikers elimineren. Maar in gereguleerde sectoren – financiële dienstverlening, farmaceutische industrie, gezondheidszorg, verzekeringen – loopt het traject van prototype naar productie rechtstreeks via een governance-controlepunt waar de meeste organisaties niet op voorbereid zijn.
Het patroon is consistent. Een bedrijf bouwt een technisch degelijke generatieve AI-applicatie met behulp van de Databricks Data Intelligence Engine – waarbij een groot taalmodel wordt verfijnd op basis van eigen documentatie en retrieval-augmented generatie wordt geïntegreerd met interne kennisdatabases. Vervolgens stelt de CISO, het juridische team of de compliance-afdeling een simpele vraag: kunt u ons precies laten zien op welke data het model is getraind, wie er toegang toe had en welke controles er waren? Zonder een gestructureerd antwoord loopt het project vast.
Wist je dat?
- Uit onderzoek van KPMG blijkt dat 62% van de organisaties een gebrek aan databeheer als de grootste belemmering voor AI-initiatieven beschouwt. (KPMG, 2025)
- Uit een onderzoek van IBM uit 2024 bleek dat slechts 24% van de AI-projecten die momenteel in gebruik zijn, worden beheerd door de organisatie die ze implementeert (IBM, 2024).
De kloof in de governance is het belangrijkste obstakel tussen AI-experimenten en AI op grote schaal.
De architectonische oplossing is Unity Catalog — Databricks' uniforme beheerslaag voor data, analyses en AI-middelen. Unity Catalog biedt toegangscontrole op rij- en kolomniveau, volledige dataherkomst van ruwe bron tot modelinvoer, op attributen gebaseerd toegangsbeleid en één beheerinterface die gestructureerde data, ongestructureerde documenten, ML-modellen en notebooks omvat. Cruciaal is dat het geen toevoeging achteraf is — het moet de eerste productieresource zijn die wordt geprovisioneerd, voordat pipelines worden gebouwd of modellen worden getraind. Achteraf toevoegen is aanzienlijk moeilijker dan het vanaf het begin te ontwerpen.
In al deze gebruiksscenario's bepalen drie architectuurprincipes consequent of een Databricks-implementatie een duurzame productieomgeving bereikt of juist technische schulden opbouwt.
- Bestuurlijke controle begint vanaf dag 1, niet pas op dag 60.
De elasticiteit van het Databricks Data Intelligence Platform is een voordeel als deze bewust wordt beheerd. Zonder beleid voor automatische beëindiging, clusterstandaardisatie en het afdwingen van infrastructuur als code vanaf het begin,worden de rekenkosten de eerste crisis waarmee een onderneming te maken krijgt – meestal binnen de eerste twee maanden.
- Declaratieve pipelines boven handmatige orkestratie.
De overstap van handmatig gecodeerde PySpark-streaming naar Delta Live Tables is geen kwestie van voorkeur voor bepaalde tools, maar een architectonische beslissing die het faaloppervlak verandert. Handmatige orchestratie legt de volledige verantwoordelijkheid voor de betrouwbaarheid bij het engineeringteam. Declaratieve pipelines leggen die verantwoordelijkheid bij het platform. Op grote schaal vertaalt dat verschil zich in een snellere gemiddelde hersteltijd, een lagere werkdruk en pipelines die geleidelijk in plaats van catastrofaal achteruitgaan.
- De Unity-catalogus als basis, niet als einddoel.
Elke onderneming die Unity Catalog als laatste stap implementeert – nadat de pipelines operationeel zijn en de modellen worden getraind – stuit op een dwingende factor die de prioriteit ervan opnieuw instelt. Governance is geen extra laag bovenop een werkend systeem. Het is de basis die een werkend systeem betrouwbaar genoeg maakt om in productie te nemen.
Dit zijn geen observaties uit geïsoleerde projecten. Het zijn patronen die zich herhalen in de data-intelligentieplatformarchitecturen van Databricks, die op grote schaal zijn gebouwd, in verschillende sectoren en onder reële productieomstandigheden.
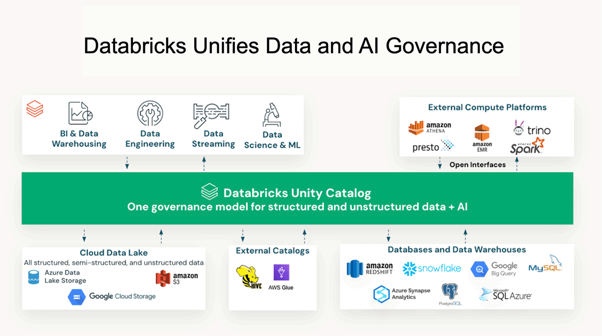 Bron: Waardeverhogende factoren voor governance in de Databricks Unity Catalog
Bron: Waardeverhogende factoren voor governance in de Databricks Unity Catalog
Het Databricks data-intelligentieplatform is geen technologische gok op de toekomst. Het is een productieklare architectuur die bedrijven in diverse sectoren vandaag de dag al gebruiken – voor Lakehouse-consolidatie, realtime streaming en gecontroleerde generatieve AI. De toepassingsmogelijkheden zijn bewezen. De resultaten zijn gedocumenteerd. De faalmechanismen zijn goed bekend.
Wat variabel blijft, is de implementatie.
De bedrijven die het meeste profijt hebben van de data-intelligentie van Databricks zijn zelden de bedrijven met de grootste budgetten of de meest ambitieuze AI-strategieën. Het zijn de bedrijven die vroegtijdig de juiste architectuurkeuzes hebben gemaakt: hun rekenkracht beheerd voordat die hun budget bepaalde, gekozen voor declaratieve pipelines voordat handmatige orchestratie een probleem werd, en Unity Catalog geïmplementeerd voordat een compliance-vraag hen dwong terug te keren naar af.
Als u evalueert waar uw organisatie zich bevindt ten opzichte van deze use cases – of u nu een eerste migratie plant, een streamingarchitectuur probeert te stabiliseren die zijn plafond heeft bereikt, of een governance-kloof probeert te dichten die een AI-initiatief blokkeert – dan zijn dit veelvoorkomende punten in het traject. De meeste bedrijven komen op een van deze punten terecht voordat ze de juiste weg voorwaarts vinden.
De vraag die er echt toe doet, is niet of het Databricks Data Intelligence Platform uw probleem kan oplossen. In de meeste gevallen kan dat wel. De nuttigere vraag is of uw huidige aanpak – uw architectuur, uw governance-model, uw implementatievolgorde – daarop is afgestemd.
Als die vraag nog geen duidelijk antwoord heeft, is het de moeite waard om erover te praten met iemand die deze beslissingen in meerdere productieomgevingen heeft moeten nemen.