
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Anmerkung der Redaktion: Ob Sie als datengetriebenes Unternehmen die perfekte Lösung suchen oder als Branchenbegeisterter nach neuen Erkenntnissen dürsten – begleiten Sie uns auf dieser aufschlussreichen Reise. Wir entschlüsseln die Geheimnisse von AWS, Azure, Snowflake und GCP und ermöglichen Ihnen so, datenbasierte Entscheidungen zu treffen. Machen Sie sich bereit, Ihre Datenmanagementstrategie zu revolutionieren und grenzenlose Möglichkeiten in der sich ständig weiterentwickelnden Welt der Technologie zu erschließen!
Alles wird mit der Cloud und Daten verbunden sein. All dies wird durch Software gesteuert.
Cloud-Technologie verbindet alles, und Daten bilden den Kern dieser Vernetzung. Technologie fungiert als Vermittler, erleichtert den Datenaustausch und ermöglicht die nahtlose Integration verschiedener Geräte und Systeme. Diese Vernetzung revolutioniert die Arbeitsweise von Unternehmen und schafft neue Chancen und Herausforderungen. Inmitten dieser digitalen Transformation ist es entscheidend, die Position des Unternehmens auf der Datenreifekurve zu verstehen.

Der Übergang von einem reaktiven zu einem prädiktiven Ansatz hat maßgeblichen Einfluss auf den Wettbewerbsvorteil großer Unternehmen, insbesondere im Hinblick auf den Reifegrad von Daten und KI. Je höher der Reifegrad, desto erfolgreicher sind sie in der Regel und desto größer ist ihr Vorsprung gegenüber der Konkurrenz. Der Weg zu einem hohen Reifegrad von Daten und KI verläuft in verschiedenen Phasen. Kennen Sie Ihre Position auf der Datenreifekurve?
Die Datenkurvenreise beginnt mit der Bereinigung der Daten aus verschiedenen Datenquellen und führt schließlich zur Datenexploration und prädiktiven Analyse, die bei der automatisierten Entscheidungsfindung hilft, was die letzte Phase darstellt.
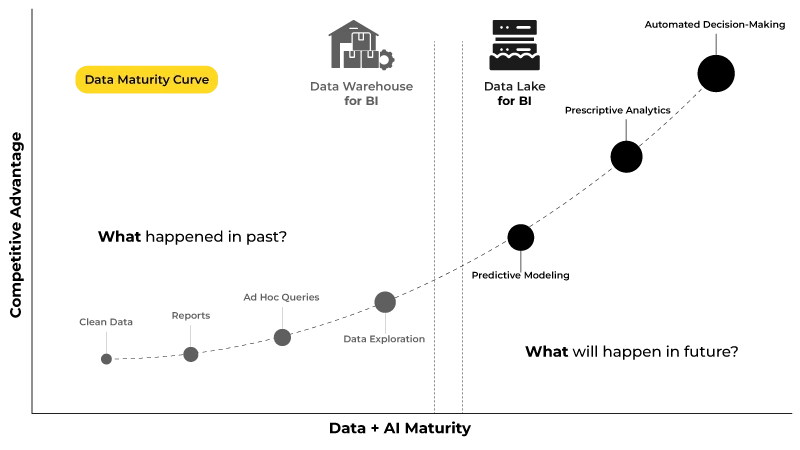
Wie Sie sehen, geht es in den Schritten 1 bis 4 darum, anhand der rückblickenden Daten zu analysieren, was in der Vergangenheit geschehen ist. Diese Phasen nutzen Business-Intelligence-Anwendungsfälle aus dem Data Warehouse , das historische Daten enthält, um wertvolle Erkenntnisse zu gewinnen.
Die Stufen 5 bis 7 basieren jedoch auf KI-Anwendungsfällen aus dem Data Lake , die Unternehmen helfen, die Zukunft anhand von Geschäftsbeschränkungen zu verstehen und vorherzusagen sowie in Echtzeit darauf zu reagieren. Mit fortschreitender Automatisierung von Entscheidungen verschaffen sich Unternehmen einen Wettbewerbsvorteil, der zu exponentiellem Geschäftswachstum führt.
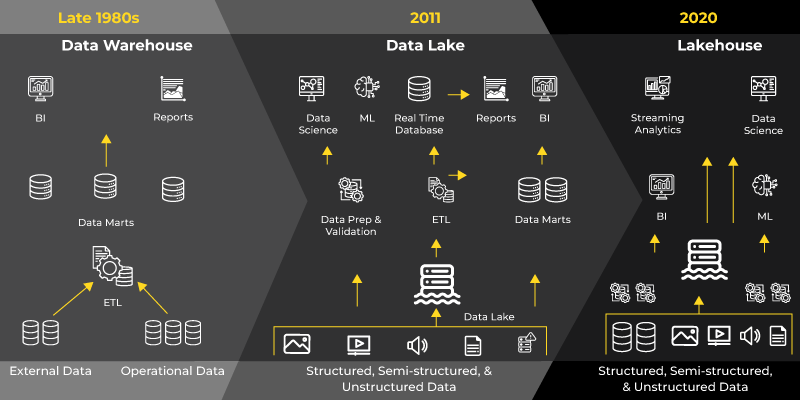
Um BI- und KI-Anwendungsfälle zu kombinieren, erfassen Unternehmen ihre Daten zunächst in einem Data Lake, der speziell für KI-Anwendungsfälle konzipiert ist. Anschließend übertragen sie diese Daten aus dem Data Lake in das Data Warehouse , das für BI-Anwendungsfälle entwickelt wurde. Dieser Prozess ist im folgenden Diagramm dargestellt und veranschaulicht den sequenziellen Datenfluss.
Nachdem wir den Datenreifegradprozess verstanden haben, stellt sich die Frage nach dem Speicherort. Wie Sie vielleicht wissen, werden Daten üblicherweise in Data Warehouses und Data Lakes gespeichert. Jedes dieser Speichersysteme birgt seine eigenen Herausforderungen.
Die Speicherung der Daten auf zwei verschiedenen Plattformen – Data Warehouse und Data Lake – birgt eigene Herausforderungen wie Datenredundanz, Datensynchronisation, Zusammenarbeit, Sicherheit und Governance usw.

Sowohl Data Warehouse als auch Data Lake bieten Vorteile, doch der parallele Betrieb von Systemen beim Übergang von reaktiver zu prädiktiver Analyse führt zu Komplexität, die die Datenverarbeitung verlangsamt. Diese Komplexität birgt drei große Herausforderungen:
1. Unzusammenhängende und doppelte Datensilos – 90-95 % der Daten in Unternehmen sind unstrukturiert und landen in einem Data Lake, da dieser sowohl strukturierte als auch unstrukturierte Daten verarbeitet, während ein Data Warehouse nur strukturierte Daten verarbeitet – wodurch doppelte und nicht synchronisierte Daten entstehen.
2. Inkompatible Sicherheits- und Governance-Modelle – Beide Plattformen bieten unterschiedliche Governance-Modelle an, die nicht miteinander kompatibel sind.
3. Unterschiedliche Daten auf unterschiedlichen Plattformen – Data Warehouses basieren auf BI-Anwendungsfällen, während Data Lakes auf KI-Anwendungsfällen basieren, was zu unterschiedlichen Leistungsmerkmalen führt.
Nachdem wir alle Herausforderungen des Betriebs auf zwei verschiedenen Plattformen gesehen haben, was wäre, wenn Unternehmen alles auf einer einzigen Plattform mit einem einheitlichen Sicherheits- und Governance-Modell erledigen könnten?

Für alle Anwendungsfälle von KI, ML, SQL und Streaming ist Data Lakehouse ein neues, offenes Systemdesign, das ähnliche Datenstrukturen und Verwaltungsfunktionen wie in traditionellen Data Warehouses direkt auf dem kosteneffizienten Speicher für Data Lakes integriert.
Durch die Zusammenführung dieser Funktionen in einem einzigen System können Datenteams ihre Abläufe beschleunigen, da sie nicht mehr auf mehrere Systeme zugreifen müssen, um Daten zu nutzen. Zudem wird sichergestellt, dass die Teams Zugriff auf die umfassendsten und aktuellsten Daten für ihre nutzerzentrierten Anwendungsfälle in den Bereichen Data Science, Machine Learning und Business Analytics haben.
Wir haben einem Unterhaltungselektronikriesen geholfen, sein Lagermanagement zu optimieren und so eine unübertroffene Effizienz und Rentabilität zu erzielen.
Betrachten wir die wichtigsten Akteure im Bereich Cloud-Datenspeicherung. Zu den führenden Anbietern zählen Amazon Web Services (AWS), Microsoft Azure, Google Cloud und Snowflake . Obwohl auch IBM und Oracle eigene Lösungen anbieten, konzentrieren wir uns zunächst auf die vier größten Anbieter, da deren Angebote im Wesentlichen ähnlich funktionieren.
Amazon Web Services (AWS) entstand 2006 als Ausgründung der umfangreichen Rechenzentrumsinfrastruktur von Amazon. Google Cloud , der bedeutendste Konkurrent, trat im April 2008 auf den Markt, gefolgt von Microsoft Azure im Oktober 2008. Snowflake, der jüngste Anbieter, wurde 2012 gegründet. Auf den ersten Blick scheint AWS hinsichtlich seiner Langlebigkeit im Vorteil zu sein.
Diese anfängliche Dominanz hielt jedoch nicht an. Microsoft reagierte schnell auf die Konkurrenz eines branchenfremden Rivalen: Snowflake . Gegründet von drei Datenspeicherexperten, entwickelte Snowflake seine Dienste rasant weiter und baute sie aus. Anstatt eine komplette Cloud-Plattform zu schaffen, konzentrierte sich Snowflake auf eine intuitive Benutzererfahrung, die sich auf jeder gängigen Cloud-Plattform implementieren ließ. So wurden die technischen Komplexitäten abstrahiert, die Integration und Skalierbarkeit oft behindern. Google Cloud benötigte zwar etwas Zeit, um zusätzliche Dienste zu entwickeln und anzubieten, erweiterte aber parallel zum Ausbau der eigenen Produkte auch die Cloud-Dienste.
Beim Marktanteil liegt Amazon mit 33 % vorn, gefolgt von Azure mit 21 % und Google mit 8 %. Der verbleibende Marktanteil verteilt sich auf die übrigen Wettbewerber. Amazons deutlicher Vorsprung ist daher keine Überraschung. Im Folgenden vergleichen wir die Funktionen der einzelnen Anbieter detailliert und analysieren ihre Unterschiede.
Lasst uns mit dem Vergleichsspiel beginnen!
Nachdem wir uns einen Überblick über die aktuelle Marktposition dieser vier Hauptakteure in der Cloud-Branche verschafft haben, wollen wir nun auch die Unterschiede in ihren vielfältigen Angeboten untersuchen.
1. Microsoft Azure
| PREISE | MERKMALE | NACHTEIL |
|---|
| Azure unterteilt seine Dienste in Rechen- und Speicherkosten. Bei einer Pausierung des Dienstes fallen für den Kunden lediglich Speicherkosten an. Es werden keine Vorabkosten und keine Kündigungsgebühren erhoben. | - Azure Storage – Entwickelt für die Verarbeitung großer Mengen strukturierter und unstrukturierter Daten.
- Azure Databricks – eine auf Apache Spark basierende Analyseplattform, die in Azure Data Lake Storage integriert ist. Sie ermöglicht skalierbare Datenverarbeitung, Analysen, Datenaufbereitung, maschinelles Lernen und Echtzeit-Streaming.
- Azure Synapse – Es vereint Data Warehousing, Big Data und Integration. Es ermöglicht die Datenerfassung, -aufbereitung, -exploration und analytische Abfragen von strukturierten und unstrukturierten Daten.
- Azure Data Factory – Automatisiert Datenworkflows über verschiedene Quellen hinweg. Erfasst, transformiert und lädt Daten in eine Lakehouse-Architektur.
- Azure HDInsight – Vollständig verwalteter Cloud-Dienst mit Hadoop, Spark, Hive, HBase und mehr. Vereinfacht die Verarbeitung und Analyse großer Datensätze.
| - Komplexität - Verwaltung mehrerer Dienste und Konfigurationen in AWS für ein Lakehouse mit begrenzter Cloud-Computing-Erfahrung.
- Arbeitsintensiv und zeitaufwändig – Es braucht Zeit, die Komplexität zu erlernen, da plattformspezifisches Fachwissen erforderlich ist.
|
2. Schneeflocke
| PREISE | MERKMALE | NACHTEIL |
|---|
| Eine gestaffelte Preisstrategie, die individuell auf Bedürfnisse und Präferenzen zugeschnitten ist, bietet Preispläne für Vorabverträge und bedarfsgerechte Nutzung. Rechenleistung und Speicherplatz werden getrennt abgerechnet, wobei die Rechenleistung sekundengenau berechnet wird. | - Einheitliche Plattform : Snowflake ist cloudunabhängig und unterstützt mehrere Cloud-Anbieter wie AWS, Azure und Google Cloud. Software-as-a-Service (SaaS): Snowflake ist ein vollständig verwalteter Dienst, bei dem Infrastruktur, Wartung und Software-Updates von Snowflake übernommen werden.
- Datenrepository unbegrenzter Größe: Es kann große Datenmengen speichern und verwalten, ohne dass man sich Gedanken über Speicherbeschränkungen oder Kapazitätsgrenzen machen muss.
- Gemischte Datentypen : Snowflake unterstützt strukturierte, semistrukturierte und unstrukturierte Daten. Es kann verschiedene Datenformate verarbeiten, darunter JSON, Avro, Parquet und mehr, sodass Unternehmen innerhalb der Plattform mit unterschiedlichen Datentypen arbeiten können.
- Mehrere Verarbeitungssprachen : Snowflake unterstützt SQL, Python, Java und R für die Datenverarbeitung.
- Zugriff auf Quelldaten ohne vorherige Datenerfassung : Snowflake macht die Erstellung eines Dateninventars oder aufwendige Datenerfassungsprozesse überflüssig. Benutzer können direkt von ihren Quellspeicherorten auf Daten zugreifen und diese abfragen.
| - Einschränkungen bei der Datenübertragung : Massen-Uploads und die Migration von Daten können mühsam sein und viel Zeit in Anspruch nehmen.
- Begrenzte native Datentransformation : Snowflake konzentriert sich primär auf Datenspeicherung und -analyse, und seine nativen Datentransformationsfunktionen sind möglicherweise nicht so umfassend wie die von spezialisierten ETL/ELT-Tools.
- Komplexität für Echtzeit-Streaming : Snowflakes Stärke liegt in der Stapelverarbeitung und -analyse, aber es ist möglicherweise nicht so gut für Echtzeit-Streaming-Anwendungsfälle geeignet.
|
3. Amazon Web Services (AWS)
| PREISE | MERKMALE | NACHTEIL |
|---|
| AWS bietet mit seinem kostenlosen Tarif einen kostengünstigen Einstieg, der es Nutzern ermöglicht, Machbarkeitsstudien ohne Kosten zu erstellen. Die wahren Kosten von AWS-Produkten werden jedoch erst deutlich, wenn sie in Produktionsumgebungen eingesetzt werden. | - AWS Glue : Ein verwalteter ETL-Service, der die Datenaufbereitung für die Analyse optimiert. Er automatisiert die Datenermittlung, Katalogisierung und Schemaableitung und beschleunigt so den Prozess.
- Amazon Athena : Es handelt sich um einen interaktiven Abfragedienst, der es Organisationen ermöglicht, Daten direkt aus Amazon S3 mithilfe von Standard-SQL-Abfragen zu analysieren.
- Amazon Redshift : Ein vollständig verwalteter Data-Warehouse-Service, der leistungsstarke Analysen und Skalierbarkeit bietet. Er ermöglicht die schnelle Ausführung von Abfragen auf großen Datensätzen und unterstützt fortgeschrittene Analysen durch die Integration mit AWS Machine Learning und anderen Analysetools.
- Amazon Kinesis : Amazon Kinesis ist ein vollständig verwalteter Streaming-Datendienst, der es Unternehmen ermöglicht, Streaming-Daten in Echtzeit zu erfassen, zu verarbeiten und zu analysieren.
- AWS Glue Data Catalog : Ein zentralisiertes Metadaten-Repository, das Metadateninformationen über Datenbestände in der Lakehouse-Architektur speichert und organisiert.
| - Komplexität der Serviceauswahl: AWS bietet eine große Auswahl an Diensten, was die Auswahl der richtigen Dienste für eine Lakehouse-Architektur zu einer Herausforderung macht.
- Mögliche Kostenüberschreitungen: AWS bietet zwar kostengünstige Lösungen, doch eine unzureichende Ressourcenverwaltung oder eine Unterschätzung des Datenspeicher- und -verarbeitungsbedarfs können zu unerwarteten Kostenüberschreitungen führen. Unternehmen müssen die Ressourcennutzung sorgfältig überwachen und optimieren, um übermäßige Ausgaben zu vermeiden.
|
4. Google Cloud Platform (GCP)
| PREISE | MERKMALE | NACHTEIL |
|---|
| Das Pay-as-you-go-Modell bedeutet, dass Unternehmen nur für die tatsächlich verbrauchten Ressourcen zahlen. Die Abrechnung erfolgt auf Basis der Nutzungsdauer und der verbrauchten Ressourcenmenge. | - BigQuery: Google Cloud BigQuery ist ein serverloses Data Warehouse, das schnelle und skalierbare Analysen ermöglicht. Es erlaubt die Echtzeitabfrage großer Datensätze mit hoher Leistung und unterstützt sowohl strukturierte als auch semistrukturierte Daten.
- BigTable: Google Cloud BigTable ist ein NoSQL-Datenbankdienst, der für die Verarbeitung riesiger Mengen strukturierter und semistrukturierter Daten entwickelt wurde.
- Dataproc: Google Cloud Dataproc ist ein verwalteter Apache Hadoop- und Spark-Dienst, der die Bereitstellung und Verwaltung von Big-Data-Verarbeitungsframeworks vereinfacht.
- Pub/Sub: Google Cloud Pub/Sub ist ein Messaging-Dienst, der die asynchrone Kommunikation zwischen Anwendungen und Komponenten in einer Lakehouse-Architektur ermöglicht.
- AutoML: Google Cloud AutoML ist eine Suite von Machine-Learning-Tools, mit denen Unternehmen benutzerdefinierte Machine-Learning-Modelle erstellen können, ohne über umfassende Kenntnisse in Data Science oder Programmierung zu verfügen.
| - Eingeschränkter Support für Unternehmen: Im Vergleich zu anderen Cloud-Anbietern verfügt GCP möglicherweise über relativ weniger Ressourcen für den Support auf Unternehmensebene.
- Weniger ausgereifte Dienste: In manchen Bereichen sind die Dienste von GCP im Vergleich zu denen der Konkurrenz möglicherweise weniger ausgereift. Obwohl GCP seine Dienste kontinuierlich erweitert und verbessert, kann es vorkommen, dass bestimmte Funktionen oder Funktionalitäten nicht so umfassend oder vollständig entwickelt sind, wie gewünscht.
|
Bei der Auswahl der idealen Lakehouse-Plattform müssen Unternehmen die jeweiligen Merkmale jeder Option sorgfältig abwägen. Diese umfassende Analyse ermöglicht ihnen eine fundierte Entscheidung, die ihren spezifischen Bedürfnissen und Anforderungen entspricht.
| Merkmale | AWS | Azurblau | Schneeflocke | GCP |
|---|
| Architektur | AWS Glue ist ein vollständig verwalteter ETL-Service (Extrahieren, Transformieren, Laden). Er bietet automatisierte Funktionen zur Datenermittlung, Katalogisierung und Schemaableitung. | Azure Synapse vereint Data-Warehousing-, Big-Data- und Datenintegrationsfunktionen. Es ermöglicht die Datenerfassung, -aufbereitung und -exploration sowie die Ausführung analytischer Abfragen. | Es kombiniert die traditionelle gemeinsame Festplattennutzung mit der Shared-Nothing-Datenbankarchitektur. Snowflake besteht aus Datenbankspeicher, Abfrageverarbeitung und Cloud-Diensten. | Google BigQuery bietet ein serverloses Data Warehouse für die schnelle und skalierbare Analyse strukturierter und semistrukturierter Daten. |
| Integration | Dienste wie AWS Data Pipeline und AWS AppSync erleichtern die Datenintegration und ermöglichen Datenstreaming und -synchronisierung in Echtzeit. | Azure Data Factory hilft bei der Orchestrierung und Automatisierung von Datenworkflows über verschiedene Quellen und Ziele hinweg. Es unterstützt die Datenerfassung, -transformation und das Laden in eine Lakehouse-Architektur. | Es bietet native Konnektoren und Integrationen und unterstützt gängige Datenintegrationstools wie Apache Kafka, Apache NiFi und weitere. Außerdem bietet es Integrationen mit Datenverarbeitungsplattformen wie Fivetran, Matillion und Talend etc. | Cloud Data Fusion bietet eine visuelle Oberfläche zum Erstellen von Datenintegrationspipelines. BigQuery für Data Warehousing und Cloud Pub/Sub für Echtzeit-Messaging und Streaming-Datenintegration. |
| Sicherheit | Sowohl der Benutzer als auch AWS sind für die Datensicherheit verantwortlich. | Azure nutzt Zugriffsmanagement, Informationssicherheit, Bedrohungsschutz, Netzwerksicherheit und Datenschutz für die Datensicherheit. Es verfügt außerdem über mehr als 90 Konformitätszertifikate. | Snowflake erfüllt zahlreiche Datenschutzstandards und hat durch die Verschlüsselung aller Daten und Dateien ein kontrolliertes Zugriffsmanagement und Datensicherheit implementiert. | Google Cloud Identity and Access Management (IAM) für eine feingranulare Zugriffskontrolle, Cloud Security Command Center für eine zentrale Sicherheitsüberwachung und Cloud Key Management Service (KMS) für die Verwaltung von Verschlüsselungsschlüsseln. |
| Datensicherung und -wiederherstellung | Amazon S3 (Simple Storage Service) dient der Datenspeicherung und -sicherung, Amazon Glacier der Langzeitarchivierung. AWS Backup bietet eine zentrale Backup-Management-Lösung. | Azure Backup automatisiert die Datensicherung von virtuellen Maschinen, Datenbanken und Dateien und gewährleistet so die langfristige Aufbewahrung und einfache Datenwiederherstellung. Azure Site Recovery repliziert Anwendungen und virtuelle Maschinen und sichert dadurch einen unterbrechungsfreien Betrieb und ein schnelles Failover. | Snowflake bietet keine herkömmlichen Backup- und Wiederherstellungsmechanismen, da es auf seiner integrierten Datenreplikations- und Speicherarchitektur basiert. | Google Cloud Storage für Datenspeicherung und -sicherung sowie Cloud Snapshot Manager für die Verwaltung und Planung von Datensicherungen. |
| Sicherheit | Sowohl der Benutzer als auch AWS sind für die Datensicherheit verantwortlich. | Azure nutzt Zugriffsmanagement, Informationssicherheit, Bedrohungsschutz, Netzwerksicherheit und Datenschutz für die Datensicherheit. Es verfügt außerdem über mehr als 90 Konformitätszertifikate. | Snowflake erfüllt zahlreiche Datenschutzstandards und hat durch die Verschlüsselung aller Daten und Dateien ein kontrolliertes Zugriffsmanagement und Datensicherheit implementiert. | Google Cloud Identity and Access Management (IAM) für eine feingranulare Zugriffskontrolle, Cloud Security Command Center für eine zentrale Sicherheitsüberwachung und Cloud Key Management Service (KMS) für die Verwaltung von Verschlüsselungsschlüsseln. |
| Eignung des Unternehmens | AWS ist bekannt für sein umfangreiches Serviceportfolio und seine ausgereiften Cloud-Angebote. Es eignet sich für Unternehmen mit vielfältigen Workloads und Anwendungen. | Eine kostengünstige Data-Warehouse-Lösung, die keine Kompromisse bei der Leistung eingeht und sich daher hervorragend für Unternehmen eignet, die stark auf Microsoft-Technologien angewiesen sind. | Snowflake eignet sich perfekt für Unternehmen, die eine skalierbare und vollständig verwaltete Lösung mit integrierter Leistungsoptimierung benötigen. | Es ist besonders attraktiv für Organisationen, die sich auf datengetriebene Erkenntnisse und KI-Anwendungen konzentrieren, da es die Integration mit gängigen Google-Technologien wie BigQuery und TensorFlow bietet. |
Letztendlich geht es bei der Entscheidung darum, das richtige Gleichgewicht zwischen unverzichtbaren Funktionen, Skalierbarkeitspotenzial und persönlichen Präferenzen zu finden. Durch sorgfältiges Abwägen dieser Faktoren können Unternehmen eine fundierte Entscheidung treffen und so das volle Potenzial einer Lakehouse-Plattform ausschöpfen.
Unser Angebot für Data Warehouses umfasst Strategie & Beratung, DWH-Entwicklung, DWH-Optimierung und vieles mehr.
Herzlichen Glückwunsch, dass Sie sich die Zeit genommen haben, dieses Thema gründlich zu erkunden. Wir hoffen, dass Sie nun die Unterschiede zwischen AWS, Snowflake, Azure und Google Cloud gut kennen. Damit können Sie fundierte Entscheidungen treffen, die den Erfolg Ihres Unternehmens fördern und Ihnen ermöglichen, das Potenzial Ihrer Daten optimal zu nutzen.
Wenn Sie sich aber noch nicht sicher sind, welches Data Lakehouse am besten zu Ihrem Unternehmen passt, lassen Sie sich von den Experten von Polestar Analytics beraten, um herauszufinden, welches Data Lakehouse am besten zu Ihrer Organisation passt.
Nehmen Sie Kontakt mit unserem Team auf und lassen Sie sich kostenlos zu Ihren Anforderungen im Bereich Data Warehousing beraten.