 Kshitij GuptaDatenstratege
Kshitij GuptaDatenstratege
Melden Sie sich an, um die neuesten Einblicke und Updates zu Technologie, KI & Datenanalyse, Data Science und Innovationen von Polestar Analytics zu erhalten.
Die meisten Data-Engineering-Teams in Unternehmen scheitern nicht an fehlenden Werkzeugen. Sie scheitern vielmehr, weil die in den letzten zehn Jahren angesammelten Werkzeuge nie für die Zusammenarbeit konzipiert wurden.
Ein Data Warehouse für Reporting. Ein Data Lake für Skalierung. Eine separate ML-Umgebung. Eine Streaming-Schicht, die hinzugefügt wurde, als die Batch-Verarbeitung nicht mehr ausreichte. Jede dieser Entscheidungen war zum damaligen Zeitpunkt sinnvoll. Die daraus entstandene Architektur ist es nicht mehr.
Wissen Sie?
- Mangelhafte Datenqualität kostet Unternehmen durchschnittlich 12,9 Millionen Dollar pro Jahr.
- Unternehmen, die separate Lake- und Warehouse-Umgebungen betreiben, geben bis zu 30 % ihres gesamten Budgets für die Dateninfrastruktur für redundante Datenbewegung und -speicherung aus – bevor sie überhaupt eine einzige Erkenntnis gewinnen können.
Databricks Lakehouse ersetzt die fragmentierte Architektur durch eine einzige offene Plattform. Dieser Blogbeitrag erläutert die spezifischen Herausforderungen im Bereich Data Engineering, die die Databricks-Lakehouse-Architektur löst – und wie diese Lösung funktioniert.
~ Bablu Chakraborty, Senior Vice President – Capability, Polestar Analytics
Bevor wir uns mit einzelnen Herausforderungen befassen, ist es wichtig, genau zu definieren, was die Databricks Lakehouse-Plattform eigentlich ist – denn diese Definition prägt jede nachfolgende Implementierungsentscheidung.
Das Databricks Data Lakehouse ist kein Data Warehouse mit zusätzlichen Data-Lake-Funktionen und auch kein Data Lake mit nachträglich hinzugefügter Data-Lake-Governance. Es handelt sich um eine einzige offene Plattform, die die Transaktionssicherheit, die Schema-Durchsetzung und die Abfrageleistung eines Data Warehouse bietet und gleichzeitig die Skalierbarkeit, Offenheit und ML-Kompatibilität eines Data Lakes beibehält. Die Lakehouse-Architektur auf Databricks basiert auf offenen Tabellenformaten – Delta Lake und Apache Iceberg – wodurch eine Anbieterbindung auf der Speicherebene vermieden wird und jede Compute-Engine, die offene Standards unterstützt, auf dieselben Tabellen zugreifen kann.
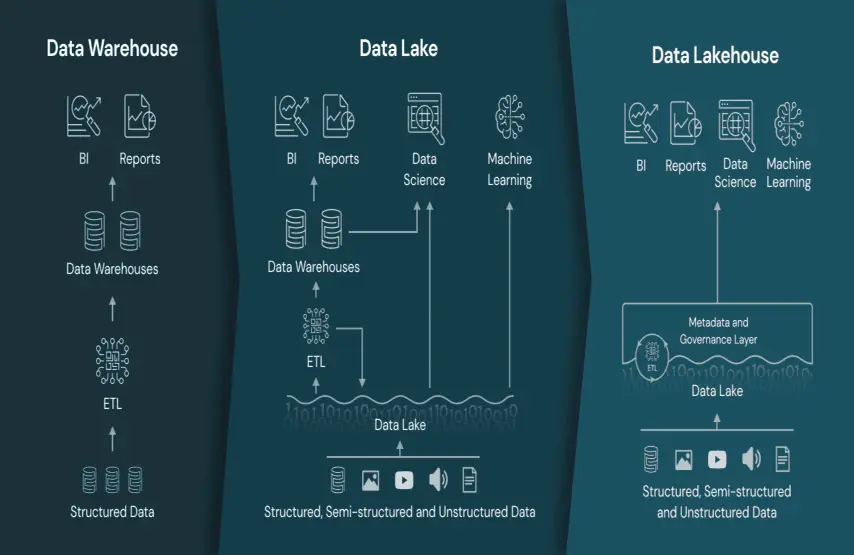
Wenn Data Warehouse und Data Lake als separate Systeme koexistieren, werden dieselben Daten zweimal erfasst, transformiert und geprüft – von unterschiedlichen Teams, was zu unterschiedlichen Ergebnissen führt. Jede neue Datenquelle vervielfacht diesen Aufwand. Es handelt sich um ein strukturelles Problem, nicht um ein Problem der Datenqualität.
Die Lakehouse Databricks-Architektur beseitigt dieses Problem von vornherein. Eine einzige offene Plattform – basierend auf Delta Lake und der Medallion-Architektur – unterstützt BI-, Streaming- und KI-Workloads auf denselben zugrunde liegenden Daten ohne Verschiebung oder Replikation.
Die Daten durchlaufen die Pipeline-Schichten einmal:
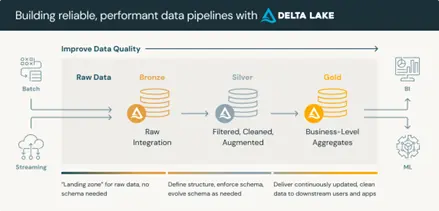
Eine Datenaufnahmepipeline. Eine Transformationslogik. Eine Version der Metrik.
Durch die Eliminierung redundanter Pipelines wird die Fehleranfälligkeit reduziert und die Fehlersuche deutlich vereinfacht. Tritt bei einer Geschäftsprozessanalyse eine Metrikabweichung auf, muss nur noch eine Pipeline untersucht und eine Transformationslogik geprüft werden – nicht mehr drei. Diese Reduzierung der Diagnosekomplexität ist der Punkt, an dem sich die Entwicklungsstunden in produktiven Lakehouse-Umgebungen am zuverlässigsten amortisieren.
Organisationen, die geschichtete Datenarchitekturen mit klar definierten Qualitätssicherungszonen implementieren, berichten von einer dreifachen Verbesserung der Zuverlässigkeit ihrer Datenpipelines im Vergleich zu Organisationen, die flache, unstrukturierte Lake-Architekturen verwenden.
Herkömmliche Data Lakes bieten keine Transaktionsgarantien. Gleichzeitige Schreibvorgänge führen zu unvollständigen Aktualisierungen. Fehlgeschlagene Prozesse hinterlassen Tabellen in undefinierten Zuständen. Schemaänderungen werden unbemerkt weitergegeben und beeinträchtigen nachfolgende Analysen. In regulierten Branchen stellt das Fehlen einer nachvollziehbaren Datenhistorie nicht nur eine technische Unannehmlichkeit, sondern auch ein Compliance-Risiko dar.
Delta Lake löst das Transaktionsproblem auf Ebene des Speicherformats. Jeder Schreibvorgang wird entweder vollständig abgeschlossen oder gar nicht ausgeführt – keine Teilzustände, keine stillen Datenbeschädigungen. Die Schemaerzwingung verhindert, dass Änderungen aus vorgelagerten Systemen ohne explizite Validierung in analytische Datensätze übernommen werden. Die Time-Travel-Funktion ermöglicht es Entwicklern, jede frühere Version einer Tabelle abzufragen oder wiederherzustellen – was früher Stunden dauerte, dauert jetzt nur noch Minuten.
Apache Iceberg erweitert diese Garantien durch eine offene Spezifikation auf Multi-Engine-Umgebungen und gewährleistet so, dass unabhängig davon, welche Compute Engine die Tabelle liest oder schreibt, dieselben Transaktionseigenschaften gelten.
Delta Lake löst das Transaktionsproblem auf Ebene des Speicherformats. Jeder Schreibvorgang wird entweder vollständig abgeschlossen oder gar nicht ausgeführt – keine Teilzustände, keine stillen Datenbeschädigungen. Die Schemaerzwingung verhindert, dass Änderungen aus vorgelagerten Systemen ohne explizite Validierung in analytische Datensätze übernommen werden. Die Time-Travel-Funktion ermöglicht es Entwicklern, jede frühere Version einer Tabelle abzufragen oder wiederherzustellen – was früher Stunden dauerte, dauert jetzt nur noch Minuten.
Apache Iceberg erweitert diese Garantien durch eine offene Spezifikation auf Multi-Engine-Umgebungen und gewährleistet so, dass unabhängig davon, welche Compute Engine die Tabelle liest oder schreibt, dieselben Transaktionseigenschaften gelten.
Bis 2026 werden 60 % der Organisationen, die ihre Daten nicht auf der Speicherebene kontrollieren, mindestens einen schwerwiegenden Compliance-Vorfall im Zusammenhang mit KI- oder Analyseergebnissen erleben.“
Wenn für ein Compliance-Audit die Dokumentation der Datenherkunft erforderlich ist oder eine KI-Initiative einer CISO-Governance-Prüfung unterzogen wird, liefern die Time-Travel- und Lineage-Funktionen der Databricks Data Lakehouse-Architektur strukturierte, abfragefähige Nachweise, die manuelle Dokumentationsprozesse nicht erbringen können. Die Auditvorbereitungszeit verkürzt sich von Tagen auf Stunden – nicht weil sich der Prozess geändert hat, sondern weil die Nachweise in jedem Schritt automatisch erfasst wurden.
In fragmentierten Architekturen wird Governance in jeder Umgebung separat angewendet – Data-Warehouse-Berechtigungen in einem System, Data-Lake-Kontrollen in einem anderen, ML-Zugriffe werden unabhängig verwaltet. Die Datenherkunft lässt sich innerhalb von Umgebungen nachvollziehen, nicht umgebungsübergreifend. Wenn eine KI-Initiative im Rahmen einer CISO-Prüfung gefragt wird, mit welchen Daten das Modell trainiert wurde, wer Zugriff darauf hatte und welche Kontrollen implementiert waren, kann eine unkontrollierte Architektur diese Fragen nicht beantworten. Projekte werden gestoppt.
72 % der Unternehmensführer äußern Bedenken hinsichtlich der Vertrauenswürdigkeit von KI-Ergebnissen. Die Governance-Lücke ist kein Randaspekt – sie stellt das zentrale Hindernis zwischen KI-Experimenten und dem großflächigen Einsatz von KI dar.
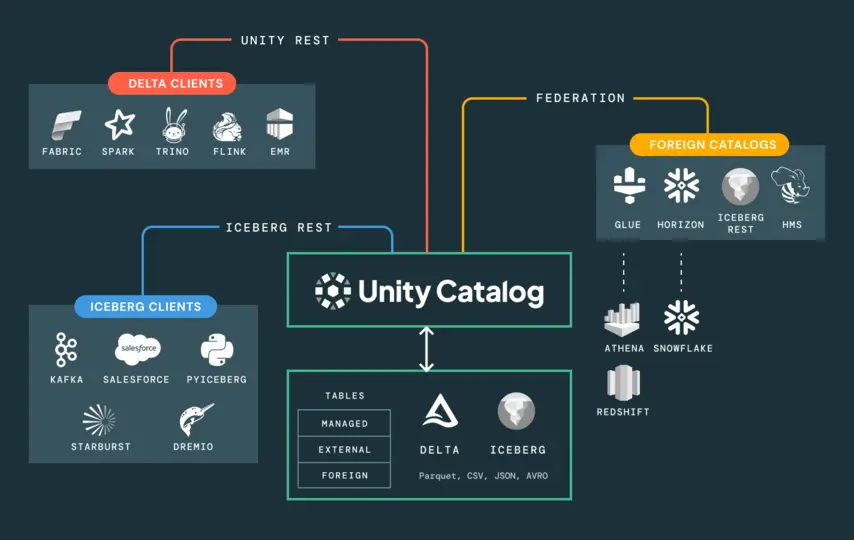
Unity Catalog bietet eine zentrale Verwaltungsebene für die gesamte Lakehouse-Plattform – Daten, Analysen, ML-Modelle, Notebooks und Dashboards werden in einem Metastore mit einheitlichen Zugriffsrichtlinien verwaltet. Die Steuerung auf Zeilen- und Spaltenebene erfolgt mittels standardisiertem ANSI-SQL. Die durchgängige Datenherkunft verfolgt jede Transformation von den Rohdaten über alle Pipeline-Ebenen bis hin zum finalen Modell oder Bericht – in einem abfragefähigen Graphen.
Der Unity Catalog muss bereitgestellt werden, bevor Pipelines erstellt und Modelle trainiert werden. Die nachträgliche Integration von Governance in ein laufendes System ist deutlich teurer – sowohl hinsichtlich Entwicklungszeit als auch des Vertrauens der Stakeholder – als eine von Anfang an korrekte Architektur.
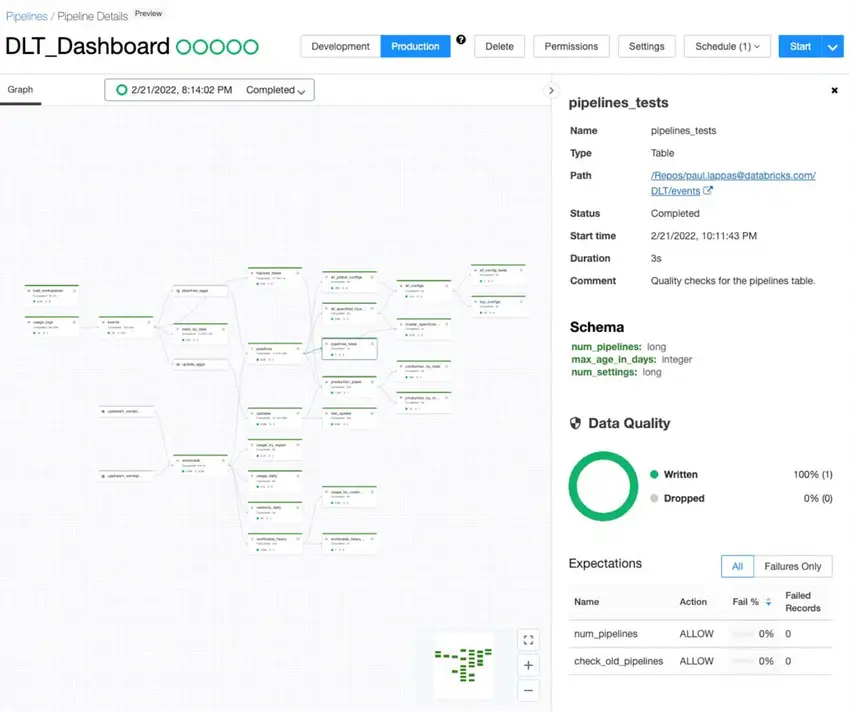
Manuell programmierte Streaming-Pipelines erfordern von den Entwicklern die explizite Pflege jedes Fehlermodus – Checkpoint-Management, Zustandswiederherstellung, Schemaentwicklung, Wiederholungslogik. Bei großem Umfang wird dies zu einer Wartungsbelastung, die die für die Entwicklung neuer Lösungen benötigten Kapazitäten bindet. Pipeline-Fehler sind keine Ausnahmefälle. Sie sind wiederkehrende Ereignisse, auf denen die Rufbereitschaft basiert.
Delta Live Tables (DLT) kehrt das Pipeline-Entwicklungsmodell von imperativ zu deklarativ um. Entwickler definieren, wie die Daten aussehen sollen und welche Qualitätsstandards sie erfüllen müssen. DLT verwaltet Abhängigkeitsauflösung, automatische Skalierung, Fehlerbehandlung, Wiederholungslogik und die Durchsetzung der Datenqualität automatisch – durch konfigurierbare Erwartungen, die bei Qualitätsverletzungen warnen, die Verarbeitung unter Quarantäne stellen oder stoppen.
Databricks Workflows erweitert dies auf die mehrstufige Orchestrierung: die Planung komplexer Pipelines, die Notebooks, DLT-Aufgaben und ML-Modelle kombinieren, mit integrierten Reparatur- und Wiederholungsfunktionen, die an der Stelle des Fehlers fortfahren, anstatt von Grund auf neu zu beginnen.
Die manuelle Clusterverwaltung führt zu einem anhaltenden Kosten- und Overhead-Problem. Bei einer Dimensionierung für Spitzenlasten zahlt man für ungenutzte Rechenleistung außerhalb der Spitzenzeiten. Bei einer Dimensionierung für durchschnittliche Lasten kommt es in Spitzenzeiten zu Auftragsstaus. Manuelle Optimierungen – VACUUM, OPTIMIZE, Partitionsanpassungen – sind zeitaufwändig und führen zu inkonsistenten Ergebnissen je nach Workload-Typ.
Serverloses Computing auf der Databricks Lakehouse-Plattform abstrahiert die Infrastrukturverwaltung vollständig. Rechenleistung wird sofort bereitgestellt, sobald eine Arbeitslast startet, und wieder freigegeben, sobald sie abgeschlossen ist – ohne Clusterkonfiguration, ohne Verwaltung ungenutzter Ressourcen und ohne Kaltstartverzögerungen. Die Sicherheitsarchitektur trennt die Steuerungsebene von der Datenebene und gewährleistet so, dass Kundendaten im eigenen Cloud-Konto des Kunden verbleiben und sowohl im Ruhezustand als auch während der Übertragung verschlüsselt sind – unabhängig davon, ob die Bereitstellung als AWS Data Lakehouse oder Azure Databricks Lakehouse erfolgt.
Die prädiktive Optimierung schließt den manuellen Optimierungskreislauf: KI-gestützte Algorithmen analysieren kontinuierlich Abfragemuster und führen Hintergrundwartungsarbeiten – VACUUM, OPTIMIZE – nur dann durch, wenn die Leistungsanalyse eine signifikante Verbesserung anzeigt. Manuelle Optimierung wird durch automatisierte, ROI-gerechtfertigte Wartung ersetzt.
Wissen Sie?
Die Databricks Lakehouse-Plattform mit strukturierter Rechengovernance erzielte über drei Jahre einen ROI von 247 % bei einer Amortisationszeit von unter sieben Monaten!
Niedrigere Gesamtbetriebskosten, schnellere Workload-Ausführung und konstant hohe Abfrageleistung ohne manuelle Optimierung. Die Entwicklungskapazitäten werden von der Infrastrukturverwaltung auf die Pipeline-Entwicklung umgelenkt – eine Arbeit, deren Wert sich im Laufe der Zeit immer weiter steigert!
Die Reihenfolge der Implementierungsentscheidungen entscheidet darüber, ob die Databricks Lakehouse-Architektur Vorteile bringt oder neue technische Schulden anhäuft. Stellen Sie zuerst den Unity Catalog bereit. Implementieren Sie die Rechengovernance, bevor die Workloads skaliert werden. Nutzen Sie Delta Live Tables, bevor die manuelle Orchestrierung zum Risikofaktor für Ihre Rufbereitschaft wird. Diese Entscheidungen lassen sich nachträglich schwerer umsetzen als von Anfang an richtig zu treffen – und die Kosten für Fehlentscheidungen machen sich schnell in Cloud-Rechnungen, Compliance-Prüfungen und der Demotivation der Entwickler bemerkbar.
Genau hier liegt der entscheidende Vorteil unserer Erfahrung mit diesen Entscheidungen in verschiedenen Produktionsumgebungen. Polestar Analytics hat Lakehouse-Architekturen für Logistik, Fertigung und Finanzdienstleistungen entwickelt – mit Unity Catalog Governance-Frameworks, DLT-Pipeline-Architekturen und Rechenrichtlinien, die sich unter realem Produktionsdruck bewähren. Wir beraten nicht aus der Ferne. Wir haben diese Entscheidungen unter Zeitdruck, im laufenden Betrieb und mit realen Risiken getroffen.
Wenn Ihre Organisation die Databricks Lakehouse-Plattform zum ersten Mal evaluiert oder versucht, mehr aus einer bestehenden Implementierung herauszuholen, die ihre architektonischen Versprechen nicht erfüllt hat, ist der richtige Ausgangspunkt ein Gespräch darüber, wo Ihre Architektur aktuell steht und welche Abfolge angesichts Ihres Datenbestands, Ihres Teams und Ihrer KI-Roadmap sinnvoll ist.
Über den Autor
Datenstratege
Die meisten Daten beantworten Fragen. Die richtigen Daten ändern die Richtung.
Verwandter Blog
 Ali Kidwai
Ali Kidwai