
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Anmerkung der Redaktion: Da sich der Bereich der Cloud-Data-Warehouses stetig weiterentwickelt, sind Innovationen und Veränderungen zu erwarten. In diesem Blogbeitrag haben wir die transformativen Möglichkeiten der besten Cloud-Data-Warehouse-Lösungen – Amazon Redshift, Google BigQuery, Snowflake und der Azure Data Platform – genauer untersucht. Diese Technologien bilden die Grundlage für cloudbasiertes Data Warehousing und bieten jeweils einzigartige Stärken und Funktionen für unterschiedlichste Geschäftsanforderungen.
Einführung
Daten sind heutzutage die wichtigste Ressource in jedem Unternehmen. Ein genereller Paradigmenwechsel in der Geschäftswelt hat im Laufe der Jahre die Bedeutung von Speicherung und Rechenleistung für die Steigerung von Umfang und Intensität der Geschäftsprozesse deutlich gemacht.
Wenn wir über Speicherung sprechen, ist uns allen das Data-Warehousing-Konzept bekannt, das Unternehmen die Möglichkeit bietet, Daten zu analysieren und zu zerlegen, um wertvolle Erkenntnisse daraus zu gewinnen und so präzise und kluge Geschäftsentscheidungen treffen zu können.
Ein Data Warehouse dient zudem als zentrales Repository für alle Daten, die ein Unternehmen über verschiedene interne und externe Quellen sammelt. Es unterstützt die Berichterstellung und Datenanalyse.
Da das Data Warehouse Daten aus verschiedenen Quellen und Medien bezieht, darunter relationale Datenbanken, NoSQL-Datenbanken und APIs von Drittanbietern, ist der Anteil mehrdeutiger Daten außerordentlich hoch. Daher müssen alle gesammelten Daten zu einem einzigen, konsistenten Datensatz zusammengeführt und optimiert werden, um schnelle Lösungen für kritische Datenbankabfragen zu ermöglichen.
Ein moderner Ansatz für die Cloud-Migrationsstrategie: Die 6 Rs
Früher waren Data Warehouses nur als On-Premise-Lösungen verfügbar, die meist anwendungsbasiert waren, was die Erweiterung von Data Warehouses erschwerte.
Um den Bedürfnissen des Marktes gerecht zu werden, stellen wir Ihnen hier einige der leistungsstärksten Data-Warehouse-Plattformen vor.

Amazon Redshift ist ein Data-Warehouse-Produkt und Teil der umfassenderen Cloud-Computing-Plattform Amazon Web Services . Es handelt sich um eine einfache und kostengünstige Data-Warehouse-Lösung, die alle Benutzerdaten aus den lokalen Data Warehouses und Data Lakes analysiert.
Amazon Redshift bietet eine bis zu zehnmal höhere Performance als herkömmliche Data-Warehouse-Lösungen und nutzt die Leistungsfähigkeit von maschinellem Lernen, massiv paralleler Abfrageausführung und spaltenorientierter Speicherung auf einer Hochleistungsfestplatte. Benutzer können innerhalb weniger Minuten ein neues Data Warehouse einrichten und bereitstellen und Abfragen über Petabytes an Daten im Redshift-Data-Warehouse sowie über Exabytes an Daten in ihrem auf Amazon S3 basierenden Data Lake ausführen.
Betrachten wir nun die Architektur von Amazon Redshift . Dieser Abschnitt erläutert die Komponenten der AWS Redshift-Architektur und gibt Ihnen somit genügend Anhaltspunkte, um zu entscheiden, ob diese für Ihren Anwendungsfall geeignet ist. Nachfolgend finden Sie das Redshift-Architekturdiagramm:
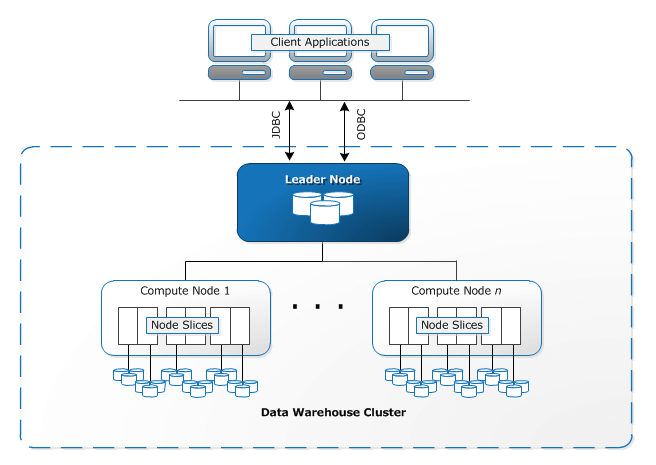
Redshift-Cluster: Redshift nutzt einen Knotencluster als zentrale Infrastrukturkomponente. Ein Cluster besteht üblicherweise aus einem Leader-Knoten und mehreren Compute-Knoten. Gibt es nur einen Compute-Knoten, ist kein zusätzlicher Leader-Knoten vorhanden.
Rechenknoten: Jeder Rechenknoten verfügt über eine eigene CPU, eigenen Arbeitsspeicher und eine eigene Festplatte. Clientanwendungen bemerken die Existenz der Rechenknoten nicht und müssen niemals direkt mit ihnen interagieren.
Leader-Knoten: Der Leader-Knoten ist für die gesamte Kommunikation mit Client-Anwendungen zuständig. Er koordiniert außerdem die Rechenknoten. Auch das Parsen von Abfragen und die Erstellung von Ausführungsplänen fallen in seinen Aufgabenbereich. Nach dem Empfang einer Abfrage erstellt der Leader-Knoten den Ausführungsplan und weist den kompilierten Code den Rechenknoten zu. Jeder Rechenknoten erhält einen Teil der Daten. Die abschließende Aggregation der Ergebnisse erfolgt durch den Leader-Knoten.
Merkmale
Massiv parallel
Amazon Redshift bietet hohe Abfrageleistung für Datensätze von Gigabytes bis Exabytes. Redshift nutzt spaltenorientierte Speicherung, Datenkomprimierung und Zonenzuordnungen, um den E/A-Aufwand für Abfragen zu reduzieren. Die Data-Warehouse-Architektur mit massiv paralleler Verarbeitung (MPP) parallelisiert und verteilt SQL-Operationen, um alle verfügbaren Ressourcen optimal zu nutzen. Die zugrundeliegende Hardware ist für Hochleistungsdatenverarbeitung ausgelegt und verwendet lokal angeschlossenen Speicher, um den Durchsatz zwischen CPUs und Laufwerken zu maximieren, sowie ein Mesh-Netzwerk mit hoher Bandbreite, um den Durchsatz zwischen den Knoten zu optimieren.
Maschinelles Lernen
Amazon Redshift nutzt maschinelles Lernen, um unabhängig von Arbeitslast und gleichzeitiger Nutzung einen hohen Durchsatz zu gewährleisten. Es verwendet ausgefeilte Algorithmen, um die Laufzeiten eingehender Abfragen vorherzusagen und sie der optimalen Warteschlange für eine schnellstmögliche Verarbeitung zuzuweisen. Beispielsweise werden Abfragen wie Dashboards und Berichte mit hohem Parallelitätsbedarf zur sofortigen Verarbeitung an eine Express-Warteschlange weitergeleitet.
Automatisierte Bereitstellung
Amazon Redshift ist einfach einzurichten und zu bedienen. Mit wenigen Klicks in der AWS Management Redshift-Konsole können Sie ein neues Data Warehouse bereitstellen. Die Infrastruktur wird automatisch für die Benutzer provisioniert. Die meisten komplexen Aufgaben, wie Backups und Replikation, werden automatisiert, sodass Sie sich auf Ihre Daten und nicht auf die Administration konzentrieren können. Redshift bietet Optionen, mit denen Sie die Funktionalität an Ihre spezifischen Workloads anpassen können, wann immer Sie die Kontrolle darüber behalten möchten. Neue Funktionen werden transparent bereitgestellt, sodass Sie Upgrades und Patches nicht planen und anwenden müssen.
Fehlertolerant
Amazon Redshift verfügt über zahlreiche Funktionen, die die Zuverlässigkeit Ihres Data-Warehouse-Clusters erhöhen. Redshift überwacht kontinuierlich den Zustand des Clusters, repliziert Daten von ausgefallenen Laufwerken automatisch neu und tauscht Knoten bei Bedarf aus, um Fehlertoleranz zu gewährleisten.
Flexible Abfrage
Amazon Redshift bietet Ihnen die Flexibilität, Abfragen direkt in der Konsole auszuführen oder SQL-Client-Tools, Bibliotheken oder Business-Intelligence-Tools Ihrer Wahl zu verbinden. Der Abfrage-Editor in der AWS-Konsole stellt eine leistungsstarke Oberfläche zur Verfügung, mit der Sie SQL-Abfragen auf Redshift-Clustern ausführen und die Abfrageergebnisse sowie den Ausführungsplan (für Abfragen, die auf Compute-Knoten ausgeführt werden) direkt neben Ihren Abfragen anzeigen können.
Liste einiger zufriedener Amazon Redshift-Kunden
- Jaulen
- Duolingo
- Comcast
- Tagundnachtgleiche
- Dow Jones

Googles BigQuery ist ein Cloud-natives Data Warehouse der Enterprise-Klasse. Es wurde 2010 als Dienst eingeführt und ist seit November 2011 allgemein verfügbar. Seitdem hat sich BigQuery zu einem kostengünstigeren und vollständig verwalteten Data Warehouse entwickelt, das blitzschnelle interaktive und Ad-hoc-Abfragen auf Petabyte-großen Datensätzen ermöglicht. Darüber hinaus lässt sich BigQuery mittlerweile in eine Vielzahl von Diensten der Google Cloud Platform (GCP) und Drittanbieter-Tools integrieren, was seinen Nutzen weiter erhöht.
BigQuery ist serverlos, genauer gesagt ein Data Warehouse als Service . Es müssen weder Server verwaltet noch Datenbanksoftware installiert werden. Der BigQuery-Dienst kümmert sich um die zugrundeliegende Software und Infrastruktur, einschließlich Skalierbarkeit und Hochverfügbarkeit. BigQuery bietet eine benutzerfreundliche Client-Oberfläche, mit der Anwender interaktive Abfragen ausführen können. Zudem verfügt es über integrierte Funktionen für maschinelles Lernen.
Nun ein genauerer Blick auf die Architektur von Google BigQuery.
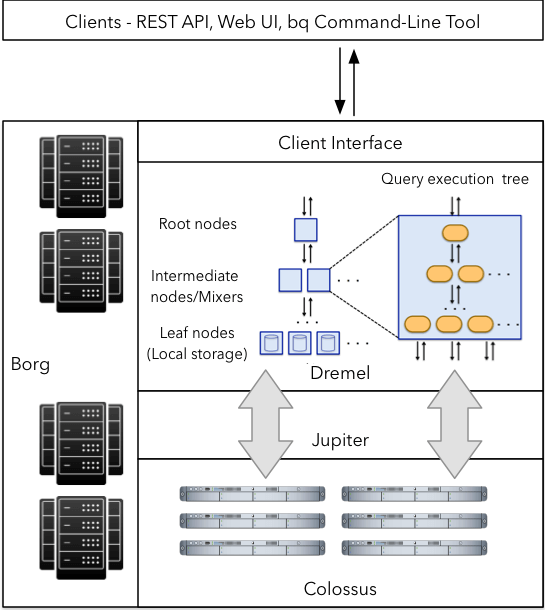
Dremel: Dremel ist die Abfrageausführungs-Engine von BigQuery. Es handelt sich um ein hochskalierbares System, das für die Ausführung von Abfragen auf Petabyte-großen Datensätzen entwickelt wurde. Dremel nutzt eine Kombination aus spaltenorientierten Datenlayouts und Baumarchitektur zur Verarbeitung eingehender Abfrageanfragen. Diese Kombination ermöglicht es Dremel, Billionen von Zeilen in Sekundenschnelle zu verarbeiten. Im Gegensatz zu vielen Datenbankarchitekturen kann Dremel Rechenknoten unabhängig skalieren, um selbst die anspruchsvollsten Abfragen zu bewältigen.
Colossus: Colossus ist das verteilte Dateisystem, das Google für viele seiner Produkte verwendet. In jedem Google-Rechenzentrum betreibt Google einen Cluster von Speichermedien, der Speicherkapazität für die verschiedenen Dienste bereitstellt. Colossus gewährleistet durch geeignete Replikations- und Notfallwiederherstellungsstrategien den Verlust der auf den Laufwerken gespeicherten Daten.
Jupiter-Netzwerk: Das Jupiter-Netzwerk bildet die Brücke zwischen dem Colossus-Speicher und der Dremel-Ausführungs-Engine. Die Netzwerkarchitektur in den Google-Rechenzentren ermöglicht ein beispielloses Maß an bidirektionalem Datenverkehr und damit den Transfer großer Datenmengen zwischen Dremel und Colossus.
Merkmale
BigQuery ML
Dies hilft Experten wie Analysten und Wissenschaftlern, mithilfe von einfachem SQL ML-Modelle auf verschiedenen Datenstrukturen zu erstellen und anzuwenden. Anschließend können die Modelle zur weiteren Vorhersage und für andere Operationen an KI-Plattformen exportiert werden.
BigQuery BI-Engine
Eine der herausragendsten Eigenschaften von BigQuery ist seine Geschwindigkeit. Dank seiner hohen Reaktionsgeschwindigkeit können Nutzer selbst komplexeste Datengruppen in Sekundenschnelle und mit hoher Genauigkeit analysieren. Die BI-Engine von BigQuery ermöglicht zudem die Integration mit verschiedenen Tools wie Data Studio und unterstützt Experten bei vielfältigen Datenanalysen und -explorationen.
Geodatenanalyse mit BigQuery GIS
BigQuery GIS kombiniert die serverlose Architektur von BigQuery mit nativer Unterstützung für Geodatenanalysen und erweitert so Ihre Analyse-Workflows um standortbezogene Informationen. Vereinfachen Sie Ihre Analysen, betrachten Sie Geodaten auf neue Weise und erschließen Sie völlig neue Geschäftsfelder dank der Unterstützung beliebiger Punkte, Polygone, Linien und Mehrfachpolygone in gängigen Geodatenformaten.
Maschinelles Lernen und prädiktive Modellierung mit BigQuery ML
BigQuery ML ermöglicht Datenanalysten und Data Scientists, Machine-Learning-Modelle für riesige, semistrukturierte oder strukturierte Datenmengen direkt in BigQuery mit einfachem SQL zu erstellen und zu operationalisieren – und das in kürzester Zeit. Nutzer können BigQuery ML-Modelle mit dieser Funktion für Online-Vorhersagen in Vertex AI oder deren Serverschicht exportieren.
Multi-Cloud-Datenanalyse mit BigQuery Omni
BigQuery Omni ist eine flexible, vollständig verwaltete Multi-Cloud-Analyselösung , die Nutzern die sichere und kostengünstige Analyse von Daten in Clouds wie Azure und AWS ermöglicht. Durch die Verwendung von Standard-SQL und der vertrauten BigQuery-Oberfläche lassen sich Fragen schnell beantworten und Ergebnisse zentral über alle Datensätze hinweg teilen.
Verbundene Blätter
Auch Nutzer ohne SQL-Kenntnisse können mithilfe der verknüpften Tabellen in BigQuery große Datenmengen analysieren. Verschiedene Tools wie Diagramme, Pivot-Tabellen und viele andere ermöglichen die Gewinnung von Erkenntnissen aus den Daten.
Neben diesen vielen Funktionen ist das Data Warehouse mit zahlreichen weiteren ausgestattet, wie z. B. Echtzeit-Analysen, logisches Data Warehousing, materialisierte Sichten, automatische Datensicherung, Datentransferdienste, flexible Kostenmodelle, hohe Sicherheit, programmatische Interaktion und vieles mehr.
Einige prominente Kunden von Google BigQuery
- UPS
- Twitter
- Home Depot
- Dow Jones

Snowflake Inc. ist ein 2012 gegründetes Startup für Cloud-basierte Data-Warehousing-Lösungen. Snowflake bietet einen Cloud-basierten Datenspeicher- und Analysedienst an, der allgemein als „Data Warehouse as a Service“ bezeichnet wird. Er ermöglicht es Unternehmen, Daten mithilfe von Cloud-basierter Hardware und Software zu speichern und zu analysieren.
Das Snowflake-Data-Warehouse nutzt eine neue SQL-Datenbank-Engine mit einer einzigartigen, für die Cloud entwickelten Architektur. Snowflake weist viele Ähnlichkeiten mit anderen Enterprise-Data-Warehouses auf, bietet aber auch zusätzliche Funktionen und einzigartige Möglichkeiten.
Lernen wir die Snowflake-Architektur kennen.
Snowflakes einzigartige Architektur besteht aus drei wesentlichen Schichten:
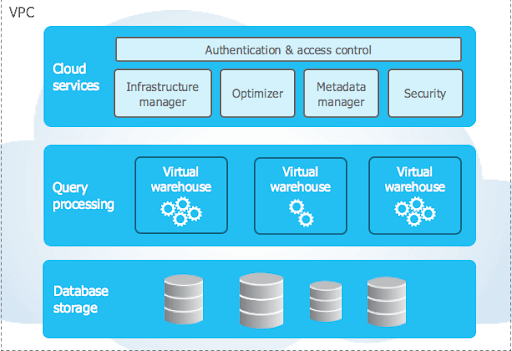
- Datenbankspeicher
- Abfrageverarbeitung
- Cloud-Dienste
Datenbankspeicher
Beim Laden von Daten in Snowflake werden diese in das interne, optimierte, komprimierte und spaltenorientierte Format umstrukturiert. Snowflake speichert diese optimierten Daten im Cloud-Speicher.
Snowflake verwaltet alle Aspekte der Datenspeicherung – Organisation, Dateigröße, Struktur, Komprimierung, Metadaten, Statistiken und weitere Aspekte der Datenspeicherung. Die von Snowflake gespeicherten Datenobjekte sind für Kunden weder direkt sichtbar noch zugänglich; sie können nur über SQL-Abfragen, die mit Snowflake ausgeführt werden, abgerufen werden.
Abfrageverarbeitung
Die Abfrageausführung erfolgt in der Verarbeitungsschicht. Snowflake verarbeitet Abfragen mithilfe von „virtuellen Data Warehouses“. Jedes virtuelle Data Warehouse ist ein MPP-Rechencluster, der aus mehreren Rechenknoten besteht, die Snowflake von einem Cloud-Anbieter bereitstellt.
Jedes virtuelle Lager ist ein unabhängiger Rechencluster, der keine Rechenressourcen mit anderen virtuellen Lagern teilt. Daher hat jedes virtuelle Lager keinen Einfluss auf die Leistung anderer virtueller Lager.
Cloud-Dienste
Die Cloud-Services- Schicht umfasst eine Sammlung von Diensten, die Aktivitäten innerhalb von Snowflake koordinieren. Diese Dienste verbinden alle Snowflake-Komponenten, um Benutzeranfragen vom Login bis zur Abfrageausführung zu verarbeiten. Die Cloud-Services-Schicht läuft auf Recheninstanzen, die Snowflake vom Cloud-Anbieter bereitstellt.
Optimieren Sie Ihr Geschäft mit der Snowflake Cloud-Datenplattform.
Merkmale
Einheitliche Plattform
Eine der herausragendsten Eigenschaften von Snowflake, mit der das Unternehmen häufig wirbt, ist die Möglichkeit, verschiedene Aktivitäten auf einer einzigen Plattform durchzuführen. Nutzer können ein breites Spektrum an Aufgaben erledigen, darunter App-Entwicklung, Data-Drilling im Data Lake, Forschung durch Data Scientists und vieles mehr.
Sichere Daten
Das Data Warehouse ermöglicht es Nutzern, Daten sicher mit verschiedenen Unternehmensbereichen oder sogar mit Kunden zu teilen, ohne sich Gedanken über Sicherheitsbedenken machen zu müssen. Ob strukturierte oder semistrukturierte Daten – Nutzer können sie problemlos und sogar live teilen.
Skalierbarkeit
Die Multi-Cluster-Architektur von Snowflake für gemeinsam genutzte Daten macht Speicher- und Rechenressourcen überflüssig. Dadurch können Benutzer die Ressourcen bedarfsgerecht skalieren, um große Datenmengen schnell zu laden, und sie nach Abschluss des gesamten Prozesses wieder reduzieren – ohne jegliche Serviceunterbrechungen. Benutzer können mit einem sehr kleinen virtuellen Data Warehouse beginnen und dieses je nach Bedarf erweitern oder verkleinern.
Wartungsfrei
Der Nutzer kann verschiedene Infrastrukturanbieter auswählen, während Snowflake die Datenplattform bereitstellt. Das Data Warehouse gilt als eine der besten Optionen zur Unterstützung der Geschäftseffizienz und der Datensouveränität.
Sicherheit
Von der Art und Weise, wie Benutzer auf Snowflake zugreifen, bis hin zur Datenspeicherung bietet Snowflake eine Vielzahl von Sicherheitsfunktionen. Sie können Netzwerkrichtlinien verwalten, indem Sie IP-Adressen auf eine Whitelist setzen, um den Zugriff auf das Konto einzuschränken. Snowflake unterstützt zahlreiche Authentifizierungsmethoden, darunter Single Sign-On (SSO) über föderierte Authentifizierung und Zwei-Faktor-Authentifizierung. Der Zugriff auf Objekte im Konto wird durch ein hybrides Modell aus diskretionärer Zugriffskontrolle (jedes Objekt hat einen Besitzer, der den Zugriff darauf gewährt) und rollenbasierter Zugriffskontrolle gesteuert. Dieser hybride Ansatz bietet ein hohes Maß an Kontrolle und Flexibilität.
Snowflake-Objekt mithilfe von Undrop wiederherstellen
Dies ist eine der einzigartigen Funktionen von Snowflake. Versehentlich abgelegte Snowflake-Objekte lassen sich wiederherstellen. Solange sich ein abgelegtes Objekt noch im Wiederherstellungsfenster befindet, kann es mit dem Befehl „Ablegen rückgängig machen“ in Snowflake wiederhergestellt werden.
Einige Kunden von Snowflake
- Mikron
- Yamaha
- Nielsen
- Überbestand
- HubSpot
- Adobe

Die Azure-Datenplattform ist ein cloudbasierter Datenintegrationsdienst, mit dem Sie datengesteuerte Workflows in der Cloud erstellen können, um Datenbewegungen und Datentransformationen zu orchestrieren und zu automatisieren.
Es ermöglicht die Erstellung datengesteuerter Workflows zur Orchestrierung des Datenaustauschs zwischen unterstützten Datenspeichern und der Datenverarbeitung mithilfe von Rechendiensten in anderen Regionen oder einer On-Premise-Umgebung. Zudem können Workflows sowohl programmatisch als auch über eine Benutzeroberfläche überwacht und verwaltet werden.
Mit Azure Data Factory können Sie datengesteuerte Workflows (sogenannte Pipelines) erstellen und planen, die Daten aus unterschiedlichen Datenspeichern einlesen können. Sie können komplexe ETL-Prozesse erstellen, die Daten mithilfe von Datenflüssen visuell transformieren.
Darüber hinaus können Sie Ihre transformierten Daten in Datenspeichern wie Azure SQL Data Warehouse veröffentlichen, damit Business-Intelligence-Anwendungen (BI) sie nutzen können. Letztendlich lassen sich Rohdaten mithilfe von Azure Data Factory in aussagekräftigen Datenspeichern und Data Lakes organisieren, um bessere Geschäftsentscheidungen zu ermöglichen.
LESEEMPFEHLUNG: KOEXISTENZ VON DATA WAREHOUSE UND DATA LAKE FÜR UNTERNEHMEN
Nun wollen wir uns näher mit der Architektur der Azure-Datenplattform befassen.
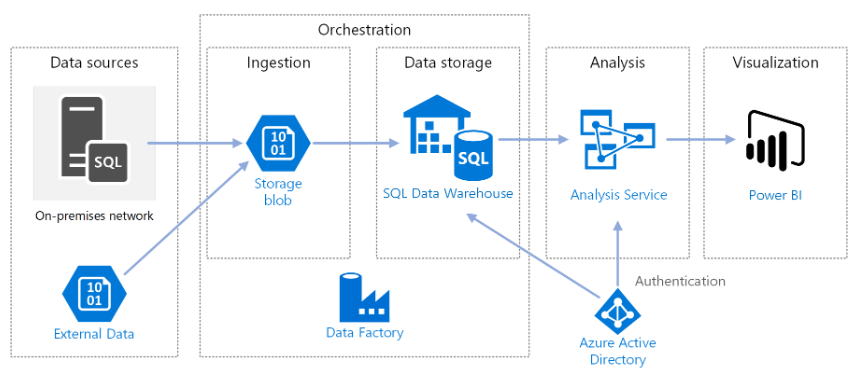
Datenquellen
Externe Daten – Ein häufiges Szenario für Data Warehouses ist die Integration mehrerer Datenquellen. Diese Referenzarchitektur lädt einen externen Datensatz mit den Einwohnerzahlen einzelner Städte pro Jahr und integriert ihn mit den Daten aus der OLTP-Datenbank. Sie können diese Daten für Erkenntnisse nutzen, wie zum Beispiel: „Entspricht das Umsatzwachstum in den einzelnen Regionen dem Bevölkerungswachstum oder übersteigt es dieses?“
Datenaufnahme und Datenspeicherung
Blob-Speicher – Der Blob-Speicher dient als Zwischenspeicher für die Quelldaten, bevor diese in Azure Synapse geladen werden.
Azure Synapse ist ein verteiltes System, das für die Analyse umfangreicher Datenmengen entwickelt wurde. Es unterstützt Massive Parallel Processing (MPP) und eignet sich daher für die Durchführung von Hochleistungsanalysen.
Azure Data Factory – Data Factory ist ein verwalteter Dienst, der die Datenübertragung und -transformation automatisiert. In dieser Architektur koordiniert er die verschiedenen Phasen des ELT-Prozesses.
Analyse und Berichterstattung
Azure Analysis Services – Analysis Services ist ein vollständig verwalteter Dienst, der Datenmodellierungsfunktionen bietet. Das semantische Modell wird in Analysis Services geladen.
Power BI – Power BI ist eine Suite von Business-Analytics-Tools zur Datenanalyse und Gewinnung von Geschäftseinblicken. In dieser Architektur fragt es das in Analysis Services gespeicherte semantische Modell ab.
Authentifizierung
Azure Active Directory (Azure AD) authentifiziert Benutzer, die sich über Power BI mit dem Analysis Services-Server verbinden.
Data Factory kann Azure AD auch zur Authentifizierung bei Azure Synapse verwenden, indem ein Dienstprinzipal oder eine verwaltete Dienstidentität (MSI) eingesetzt wird. Der Einfachheit halber verwendet die Beispielbereitstellung die SQL Server-Authentifizierung.
Merkmale
Datenresilienz
Das Allerwichtigste für Unternehmen bei der Auswahl eines Cloud-Data-Warehouse ist die Sicherheit. Bei Microsoft Azure werden alle Daten sicher in den Rechenzentren von Microsoft gespeichert. Microsoft Azure bietet zusätzliche Sicherheitsoptionen, die von den Nutzern ausgewählt werden können. Dies macht Azure zu einem der sichersten Cloud-Data-Warehouses und ist einer der Gründe, warum sich immer mehr Unternehmen dafür entscheiden.
BCDR-Integration
Azure-Speicher bietet nicht nur Datensicherheit, sondern gewährleistet auch die reibungslose Datenwiederherstellung. Er stellt zudem umfassende Backup-Funktionen bereit. Viele Kunden und Unternehmen nutzen Microsoft Azure, weil es erstklassige Backup-Lösungen bietet, die Ihre Daten zuverlässig schützen.
Kapazitätsmanagement
Kapazitätsplanung und -management können sehr zeitaufwändig sein. Microsoft Azure hingegen zeichnet sich durch eine Hybridarchitektur in seinen Speicherlösungen aus. Diese Architektur bietet zahlreiche Optionen wie Archivierung, Daten-Tiering, Komprimierung und vieles mehr für ein effizientes Kapazitätsmanagement.
Einzelfensterbetrieb
Neben den anderen Funktionen von Microsoft Azure bietet es unter anderem die Möglichkeit, Operationen in einer einzigen Ansicht durchzuführen. Dies hilft Benutzern, die gewonnenen Erkenntnisse besser einzusehen und zu verwalten.
Einige namhafte Kunden, die Microsoft Azure nutzen
- EY
- Kennametal
- H&R Block
- Cincinnati Kinderkrankenhaus
Da Daten zu einem unverzichtbaren Bestandteil von Unternehmen geworden sind, ist es entscheidend, sie so effizient wie möglich zu verwalten. Die richtigen Cloud-basierten Data-Warehouse-Services sind hierfür die ideale Lösung. Die Auswahl der passenden Plattform kann eine Herausforderung sein, doch der richtige Anbieter kann Unternehmen die optimale Lösung bieten.