
Fassen Sie diesen Blogbeitrag wie folgt zusammen:
Anmerkung der Redaktion: Die Suche nach der optimalen Cloud-basierten Data-Warehousing-Lösung ist sowohl kostenintensiv als auch technisch anspruchsvoll. Diese Analyse beleuchtet die technischen Aspekte von AWS Redshift und Google BigQuery werden vorgestellt und ihre Architekturen, Funktionalitäten und Eignung für unterschiedliche Geschäftsanforderungen beleuchtet. Obwohl es im Bereich der Data Warehouses oft ein standardisiertes Konzept gibt, möchte dieser Blog Führungskräfte und Entscheidungsträger dabei unterstützen, Verbindungen zwischen ihren bestehenden Architekturen herzustellen und die beste Alternative zu finden.
Data Warehousing hat sich im letzten Jahrzehnt dank Cloud Computing und Big-Data-Technologien deutlich weiterentwickelt. Cloudbasierte Data-Warehouse-Lösungen sind für viele Unternehmen zur bevorzugten Wahl geworden, da sie Skalierbarkeit, Leistung, Kosteneffizienz und Verfügbarkeit bieten. Darüber hinaus sind hybride und heterogene Datenarchitekturen mittlerweile Standard.
Welche Komponente sollte für einen bestimmten Vorgang der Datenaufbereitung oder -analyse verwendet werden?
Benötigen wir eine Cloud-basierte Data-Warehouse-Lösung oder nicht?
Welche zentrale Rolle spielt jeder OEM in einer Multi-Cloud-Architektur?
Diese Entscheidungen sind für CDOs oft eine Herausforderung, da sie das Potenzial haben, die Effizienz und Effektivität der Datenprozesse einer Organisation erheblich zu beeinträchtigen.
AWS Redshift mit seiner Speicher- und Massively Parallel Processing (MPP)-Architektur und Google BigQuery mit seinem einzigartigen spaltenbasierten Speichersystem sind zwei herausragende Akteure auf diesem Gebiet, die jeweils eine einzigartige Reihe von Funktionen und Möglichkeiten bieten, die auf unterschiedliche Anwendungsfälle zugeschnitten sind.
Der globale Markt für Data Warehousing hatte im Jahr 2022 einen Wert von 28,73 Mrd. US-Dollar und es wird erwartet, dass der Gesamtumsatz von 2023 bis 2029 mit einer durchschnittlichen jährlichen Wachstumsrate (CAGR) von 10,7 % auf fast 58,54 Mrd. US-Dollar ansteigen wird [1].
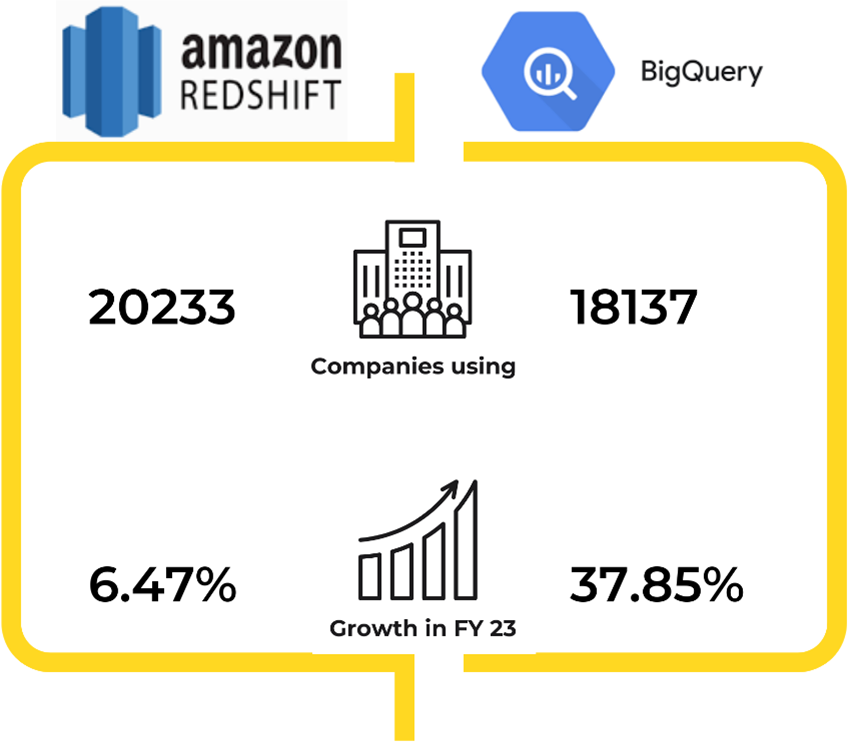
Architektur und Datenspeicherung
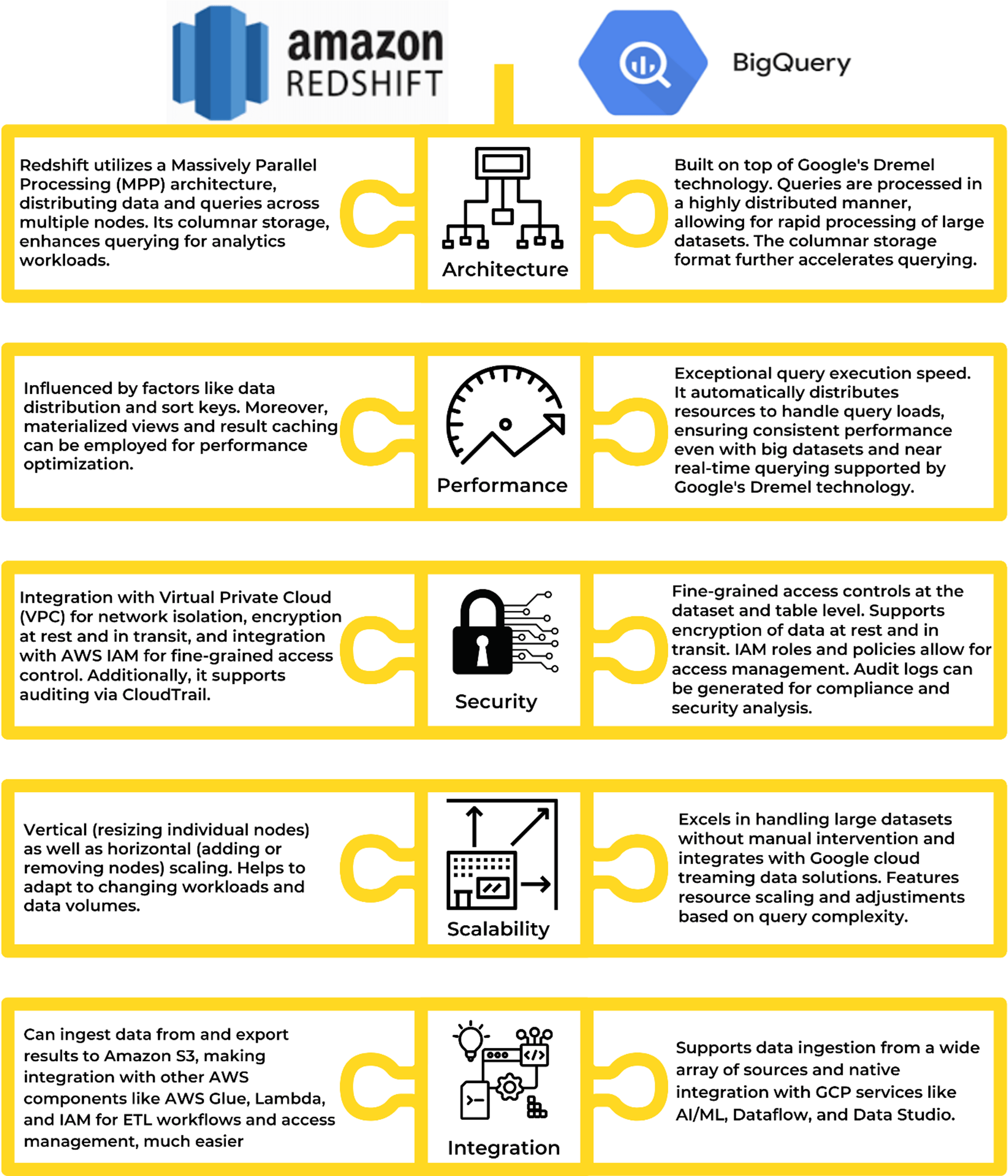
Amazon Redshift nutzt eine spaltenorientierte Speicherarchitektur, die Daten spaltenweise statt zeilenweise organisiert. Dieses Design ermöglicht hocheffiziente Abfrage- und Aggregationsvorgänge, insbesondere für Analyse-Workloads. Redshift arbeitet zudem auf einem Cluster-basierten Modell, in dem mehrere Knoten zusammenarbeiten, um Abfragen zu verarbeiten. Die Daten werden auf diese Knoten verteilt, was eine parallele Verarbeitung und damit eine höhere Leistung ermöglicht.
Datenerfassung
Die Datenaufnahme in Redshift kann über verschiedene Methoden erfolgen, darunter Batch-Verarbeitung, direkte Abfragen und Datenstreaming. Die nahtlose Integration mit AWS Glue ermöglicht effiziente ETL-Prozesse. Redshift unterstützt eine Vielzahl von Datenkonnektoren und APIs und gewährleistet so die reibungslose Integration verschiedenster Datenquellen. In Leistungstests erreichte Redshift Aufnahmeraten von bis zu 10 GB/s.
Erweiterte Analyse- und Machine-Learning-Funktionen
Amazon Redshift bietet eine robuste Umgebung für fortgeschrittene Analysen und Anwendungen des maschinellen Lernens (ML). Es lässt sich nahtlos in gängige ML-Frameworks wie TensorFlow und Apache MXNet integrieren. Darüber hinaus ermöglicht Redshift Spectrum die direkte Abfrage von Daten aus Amazon S3, sodass Data Scientists die Leistungsfähigkeit externer Datenquellen in ihren ML-Modellen nutzen können.
Sicherheit und Compliance
Redshift bietet ein robustes Sicherheitsframework mit Funktionen wie der Verschlüsselung ruhender und übertragener Daten. Die Zugriffskontrolle erfolgt über AWS Identity and Access Management (IAM) und ermöglicht so eine detaillierte Steuerung der Benutzerberechtigungen. Redshift erfüllt diverse Branchenstandards und Zertifizierungen und bietet damit eine sichere Umgebung für sensible Daten. Redshift ist unter anderem nach SOC 2, HIPAA und PCI DSS zertifiziert.
Preisgestaltung und Kostenüberlegungen
Amazon bietet Flexibilität ohne langfristige Verpflichtungen, während reservierte Instanzen erhebliche Kosteneinsparungen bei vorhersehbaren Workloads ermöglichen. Darüber hinaus ermöglicht Redshift Spectrum kosteneffiziente Abfragen von in Amazon S3 gespeicherten Daten und bietet so ein optimales Verhältnis zwischen Leistung und Kosten.
Tauchen Sie tief in die Vergleiche zwischen RedShift und Snowflake ein.
Eine aufschlussreiche Entdeckungsreise, die Ihr Unternehmen auf Jahre hinaus stärken wird – Treffen Sie die beste Wahl für Ihre Datenbedürfnisse.

Im Gegensatz zum oben genannten Konkurrenten von Amazon arbeitet BigQuery auf der Google Cloud Platform mit einem verteilten Speichersystem, das eine nahtlose Skalierung der Rechenressourcen je nach Bedarf ermöglicht. Die Daten in BigQuery werden in Capacitor gespeichert, einem speziell für die effiziente Abfrageausführung entwickelten Speicherformat. Diese Architektur stellt sicher, dass die Rechenressourcen ausschließlich für die Verarbeitung von Abfragen zur Verfügung stehen, was zu beeindruckenden Leistungssteigerungen führt.
Datenerfassung
BigQuery bietet zahlreiche Optionen zur Datenaufnahme, darunter Batch-Verarbeitung, Streaming und föderierte Abfragen für externe Datenquellen. Die enge Integration mit anderen Google Cloud-Diensten vereinfacht Daten-Workflows. Darüber hinaus gewährleistet die Unterstützung von Standard-SQL und die Kompatibilität mit gängigen ETL-Tools reibungslose Datenintegrationsprozesse. BigQuery kann Streaming-Daten mit einer Geschwindigkeit von bis zu 100.000 Zeilen pro Sekunde und Tabelle verarbeiten.
Erweiterte Analyse- und ML-Funktionen
Google BigQuery bietet mit BigQuery ML einen nativen ML-Dienst, mit dem Nutzer ML-Modelle direkt in der Plattform mithilfe von Standard-SQL-Abfragen erstellen können. Dadurch entfällt die Notwendigkeit, Daten zu extrahieren und an externe ML-Tools zu übertragen. BigQuery ML unterstützt eine Vielzahl von Modelltypen, darunter lineare und logistische Regression, Zeitreihenprognosen und vieles mehr.
Sicherheit und Compliance
Die Google Cloud Platform hat BigQuery mit umfassenden Sicherheitsmaßnahmen ausgestattet, darunter die Verschlüsselung von Daten sowohl während der Übertragung als auch im Ruhezustand. Die Zugriffskontrolle erfolgt über Google Cloud IAM und ermöglicht so fein abgestufte Zugriffsrichtlinien. BigQuery erfüllt zudem zahlreiche Branchenstandards und gewährleistet damit die Einhaltung strengster Sicherheits- und Compliance-Anforderungen. BigQuery ist unter anderem nach ISO 27001, SOC 2 und HIPAA zertifiziert.
Preisgestaltung und Kostenüberlegungen
BigQuery verwendet ein nutzungsbasiertes Abrechnungsmodell. Speicher- und Abfragekosten werden getrennt ausgewiesen, was eine präzise Kostenkontrolle ermöglicht. Dank der verteilten Architektur von BigQuery zahlen Nutzer nur für die tatsächlich genutzten Ressourcen während der Abfrageausführung. Dies macht BigQuery zu einer wirtschaftlichen Wahl für Unternehmen, die nach kostengünstigen Datenanalyselösungen suchen.
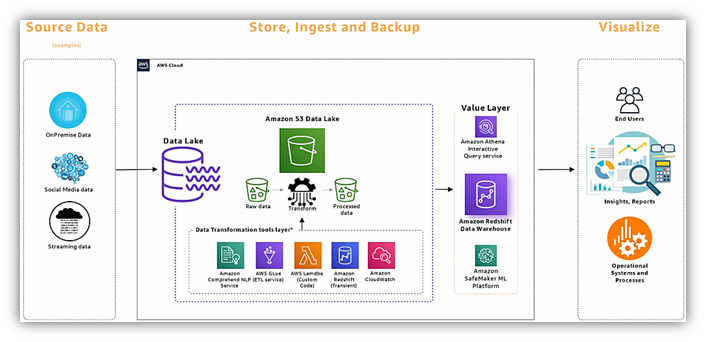
Amazon Redshift findet seine Nische in Szenarien, in denen hohe Leistung und komplexe Analysen von größter Bedeutung sind. Es zeichnet sich durch seine Leistungsfähigkeit in den Bereichen Data Warehousing, Business Intelligence und Data Science aus, insbesondere in Unternehmen, die stark in das AWS-Ökosystem investiert sind.
Google BigQuery hingegen glänzt bei Echtzeit-Datenanalysen und Szenarien, in denen eine schnelle Abfrageausführung entscheidend ist. Dank seiner serverlosen Architektur ist es eine ausgezeichnete Wahl für Unternehmen, die eine wartungsarme und leistungsstarke Cloud-basierte Data-Warehousing-Lösung suchen.
Amazon Redshift vs. BigQuery: Die wichtigsten Unterschiede
Gesamtdatenstrategie: Redshift ist zwar für den Einsatz in Hybrid-Cloud-Systemen geeignet, lässt sich aber insbesondere in Unternehmen mit einer etablierten AWS-Infrastruktur nahtlos integrieren – dank bestehender VPCs, IAM-Rollen und Data-Lake-Integrationen. Die native Integration mit Diensten wie AWS Glue für ETL und SageMaker für ML schafft ein zusammenhängendes Datenökosystem. BigQuery hingegen positioniert sich dank seiner Multi-Cloud-Kompatibilität als vielseitige Lösung für heterogene oder hybride Architekturen. Die Möglichkeit, externe Daten direkt aus dem Cloud-Speicher abzufragen, kombiniert mit der engen Integration in Google Cloud AI/ML-Dienste, ermöglicht Unternehmen mit vielfältigen Cloud-Umgebungen optimale Lösungen.
Fachkompetenz/Verfügbarkeit von Talenten: Neben den Plattformen selbst ist es entscheidend, die erforderliche Expertise zu berücksichtigen, um ihr volles Potenzial auszuschöpfen. Redshift basiert stark auf SQL und ist daher eine naheliegende Wahl für Teams mit Erfahrung in relationalen Datenbanken. Die Integration mit AWS-Ökosystemdiensten wie Glue, Lambda und Kinesis erfordert gewisse AWS-Kenntnisse. BigQuerys proprietärer SQL-Dialekt hingegen mag für manche Teams eine vertraute Umstellung sein, doch die nahtlose Integration mit Data Lakes und den KI/ML-Diensten von Google Cloud erfordert Einarbeitung.
Redshift vs. BigQuery: Preisvergleich: In der aktuellen, unsicheren Geschäftslage spielen die Kosten für die meisten Unternehmen eine entscheidende Rolle. AWS Redshift lässt sich aufgrund seiner bedarfsorientierten, stundenbasierten Abrechnung etwas leichter prognostizieren. In vielen Anwendungsfällen kann BigQuery mit seinen 6,25 $/TiB Abfragekosten jedoch die bessere Wahl sein. Amazon Redshift mit seiner spaltenorientierten Speicherung und Clusterarchitektur ist ideal für Organisationen, die hohe Leistung und Skalierbarkeit benötigen, insbesondere für solche, die bereits im AWS-Ökosystem etabliert sind. Google BigQuery bietet mit seiner verteilten Architektur und nutzungsbasierten Abrechnung ein flexibleres Preis- und Speicherpaket – eine effektive Lösung für Unternehmen, die schnelle Abfrageausführung und nahtlose Skalierbarkeit benötigen.
Zukünftige Anwendungsfälle: Die Schnittstelle zwischen Data-Warehousing-Plattformen und maschinellem Lernen (ML) ist ein Bereich, in dem das Potenzial von Redshift und BigQuery besonders deutlich zum Tragen kommt. Redshift eignet sich mit seiner MPP-Architektur hervorragend für die parallele Verarbeitung beim Training von ML-Modellen. Die Elastizität und Skalierbarkeit der Redshift-Cluster in Kombination mit GPU-Unterstützung ermöglichen es Data Scientists, immer komplexere Modelle zu bearbeiten. BigQuery zeichnet sich mit seinen integrierten ML-Funktionen durch schnelle, iterative Modellbereitstellung und -inferenz aus. Die Entscheidung hängt daher von der Art Ihrer ML-Workloads ab – von intensivem Modelltraining bis hin zu Echtzeitvorhersagen.
Bereit für eine detaillierte Analyse der vier großen Cloud-Anbieter – AWS vs. Snowflake vs. Azure vs. Google Cloud?
Kundensegmentierung und Personalisierung für eine Einzelhandelskette
Die Massively Parallel Processing (MPP)-Architektur von AWS Redshift wird genutzt, um große Datensätze mit Kundentransaktionshistorien, demografischen Informationen und Verhaltensdaten effizient zu verwalten. Mithilfe fortschrittlicher Analyseverfahren wie der Singulärwertzerlegung (SVD) oder t-verteilter stochastischer Nachbareinbettung (t-SNE) führt die Handelskette komplexe Kundensegmentierungsanalysen durch. Durch die Integration von Machine-Learning-Frameworks wie Apache Spark MLlib oder scikit-learn kann die Kette personalisierte Empfehlungssysteme entwickeln, die Techniken wie kollaboratives oder inhaltsbasiertes Filtern nutzen.
Wertsteigerung: Dieser Ansatz ermöglicht es der Handelskette, hochgradig personalisierte Marketingkampagnen, Produktempfehlungen und Werbeangebote bereitzustellen. Durch den Einsatz der Rechenleistung und des maschinellen Lernens von Redshift erzielt die Kette höhere Konversionsraten und eine gesteigerte Kundenbindung.
Vorausschauende Instandhaltung für eine Produktionsanlage
Die Stream-Processing-Funktionen von BigQuery verarbeiten eingehende Sensordaten von Produktionsanlagen. Zeitreihenanalyseverfahren mit Schneller Fourier-Transformation (FFT) oder Wavelet-Transformation werden angewendet, um Muster zu erkennen, die auf drohende Anlagenausfälle hinweisen. Maschinelle Lernalgorithmen, die über Plattformen wie die Google AI Platform in BigQuery integriert sind, ermöglichen die Entwicklung und den Einsatz von Modellen für die vorausschauende Wartung.
Wertsteigerung: Dieser technische Ansatz ermöglicht es dem Produktionswerk, Wartungsarbeiten vorherzusagen und zu planen, bevor es zu kritischen Anlagenausfällen kommt. Durch die Nutzung der Echtzeit-Datenverarbeitungsfunktionen und des maschinellen Lernens von BigQuery erzielt das Werk erhebliche Kosteneinsparungen durch minimierte ungeplante Ausfallzeiten und gesteigerte Betriebseffizienz.
Die Wahl zwischen Amazon Redshift und Google BigQuery hängt letztendlich von den spezifischen Anforderungen und Prioritäten einer Organisation ab. Es gibt zwar einige Unterschiede, aber weitaus mehr Gemeinsamkeiten.
Zusammenfassend lässt sich sagen, dass ein umfassendes Verständnis der technischen Feinheiten jeder Plattform entscheidend für eine fundierte Entscheidung ist. Indem Sie die Stärken von Amazon Redshift oder Google BigQuery mit den spezifischen Bedürfnissen Ihres Unternehmens in Einklang bringen, können Sie das volle Potenzial Ihrer Datenanalyseprojekte ausschöpfen.