
Vat dit blogbericht samen met:
Noot van de redactie: U beschikt over de data. De vraag voor 2026 is of de onderliggende infrastructuur is ontworpen om er ook daadwerkelijk iets mee te doen, of alleen om erover te rapporteren. De technologie is volwassen geworden. De architecturen zijn op elkaar afgestemd. Nu gaat het erom het op grote schaal te laten werken.
De trends in data-analyse die 2026 vormgeven, gaan niet over nieuwe tools of grotere modellen, maar over waar data-teams nu verantwoordelijk voor zijn en wat de gevolgen zijn van fouten. Dit boek is geschreven voor data-engineers, analytics-architecten en CDO's die momenteel infrastructuurbeslissingen nemen.
Vrijwel elke grote onderneming beweert tegenwoordig datagedreven te zijn. Slechts 37,8% van de Fortune 1000-bedrijven is dat daadwerkelijk – ondanks een gemiddelde jaarlijkse uitgave van 250 miljoen dollar aan data-initiatieven. Deze kloof bestaat al jaren. Wat in 2026 anders is, zijn de kosten.
Toen de analyse-infrastructuur alleen rapportage hoefde te ondersteunen, betekende een defecte pipeline een defect dashboard. Herstelbaar. Zichtbaar. Beperkt. Maar nu AI van pilot naar productie evolueert, zorgt diezelfde infrastructuur ervoor dat beslissingen automatisch worden genomen – en slechte data leidt niet langer alleen tot een slecht rapport. Het leidt tot een verkeerde actie, razendsnel en op grote schaal.
Meer dan de helft heeft aanzienlijke middelen verspild aan het trainen van modellen op data die ze niet hadden moeten vertrouwen.
De organisaties die de kloof vergroten, zijn niet de organisaties met de beste modellen of de grootste teams. Het zijn de organisaties die data-architectuur als een strategische beslissing beschouwen – en niet als een voorwaarde voor die strategische beslissing.
De wereldwijde markt voor data-analyse zal naar verwachting groeien van 104 miljard dollar in 2026 tot 496 miljard dollar in 2034. Wie deze waarde weet te verzilveren, wordt nu al bepaald door de infrastructuurkeuzes die momenteel worden gemaakt. Hieronder volgen zes verschuivingen die de organisaties die het goed doen, onderscheiden.
Decennialang werkte data-analyse volgens een pull-model. Iemand formuleerde een vraag, opende een tool en het systeem gaf een antwoord. Het inzicht was slechts zo goed als de gestelde vraag – wat betekende dat hele categorieën signalen onopgemerkt bleven, simpelweg omdat niemand eraan dacht om ernaar te zoeken.
Agentische analyses doorbreken dat contract. In plaats van te wachten tot er een vraag wordt gesteld, houden deze systemen continu in de gaten – ze sporen afwijkingen op voordat ze problemen worden, leggen de cijfers in begrijpelijke taal uit en grijpen direct in wanneer de drempelwaarden dat toelaten. Mensen blijven betrokken, maar op het niveau van de besluitvorming, niet op het niveau van de gegevensopvraging.
Zo werken AI-agenten:
Dit wordt niet door één ding veroorzaakt. Grote taalmodellen (LLM's) gaven agents de mogelijkheid om te redeneren over ongestructureerde context. Kleinere, gespecialiseerde modellen (SLM's) maakten die redenering betaalbaar op grote schaal. Samen produceren ze iets wat traditionele, op regels gebaseerde automatisering nooit kon: oordeelsvorming die zich aanpast. Platforms zoals 1Platform integreren dit al native in BI-tools via hun consumptielaag, wat betekent dat agentische analyses geen apart systeem meer zijn. Het is een functionaliteit binnen de platforms die teams al gebruiken.

Volgens Gartner zal 40% van de bedrijfsapplicaties tegen eind 2026 taakspecifieke AI-agents bevatten, tegenover minder dan 5% in 2025.
Voor analisten betekent dit in de praktijk het volgende: minder tijd besteden aan het ophalen van data, meer tijd aan het interpreteren ervan. De rol wordt niet kleiner, maar verschuift naar een meer centrale positie.
Traditionele analysepipelines hebben een probleem met de richting van de data. Data stroomt maar in één richting: verzamelen, transformeren, modelleren, leveren. Een inzicht belandt in een dashboard, een mens handelt ernaar, en wat er vervolgens gebeurt, verdwijnt simpelweg uit beeld. De uitkomst keert nooit terug naar het model. De volgende voorspelling draait op dezelfde historische data, zonder te weten wat de vorige beslissing daadwerkelijk heeft opgeleverd.
Beslissingsintelligentie met een gesloten lus bepaalt de richting. Elke beslissing wordt een data-event op zich – vastgelegd, gelabeld en teruggekoppeld als trainingssignaal. Het model leert van wat het heeft gedaan, niet alleen van wat de data aangaf voordat het handelde. De nauwkeurigheid neemt exponentieel toe. De pipeline is geen eenrichtingsverkeer meer.
Kort samengevat:
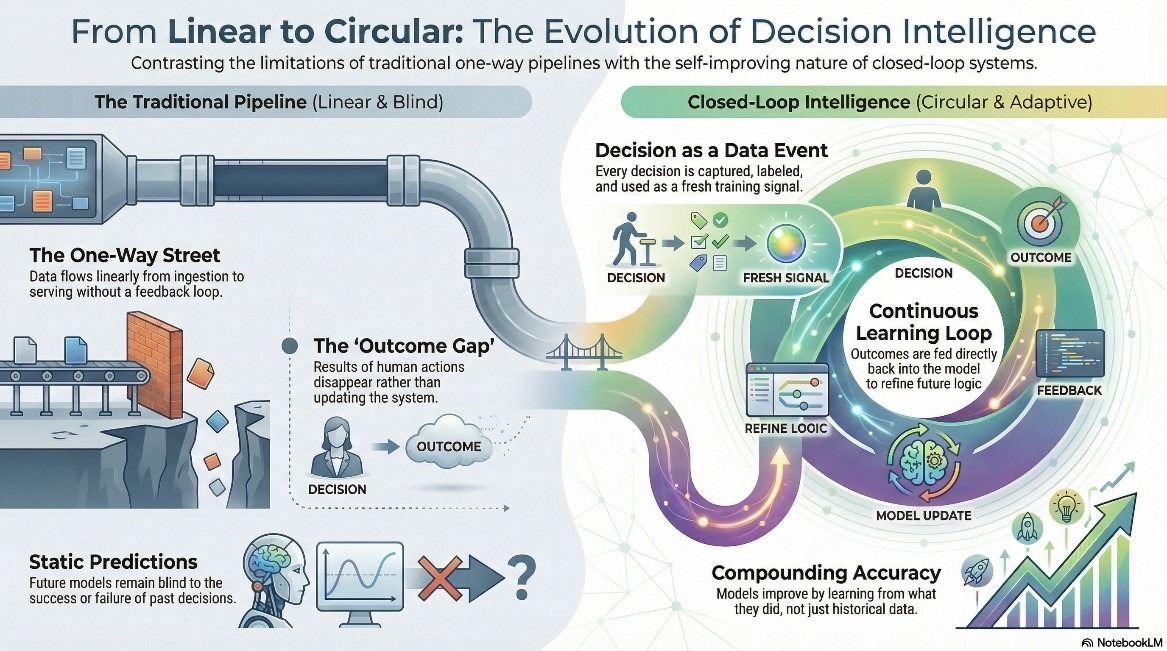
Voor datateams creëert dit een nieuwe categorie infrastructuurverantwoordelijkheid. Resultaatdata is nu een volwaardige entiteit – deze moet worden gemodelleerd, beheerd en gemonitord zoals elke productiebron. Dat klinkt eenvoudig, totdat de feedbackloop stilletjes begint te haperen. Resultaatdata komt te laat binnen. Het komt verkeerd gelabeld binnen. Soms komt het helemaal niet binnen. Elk van deze gevallen leidt tot modelafwijkingen die aanzienlijk moeilijker te detecteren zijn dan een mislukte data-invoertaak – en 89% van de dataleiders met AI in productie heeft al misleidende outputs ervaren als gevolg van precies dit soort upstream-storingen.
Dit is waar de architectuur van 1Platform de gesloten lus operationeel maakt in plaats van theoretisch. Data Nexus beheert het volledige data-ecosysteem, inclusief uitkomstsignalen, terwijl Agenthood AI beslissingen uitvoert binnen gedefinieerde drempelwaarden en elke actie en elk resultaat terugschrijft naar de pipeline. Afwijkingen worden detecteerbaar. Beslissingen worden controleerbaar. De feedbacklus wordt behandeld als infrastructuur – omdat dat het ook is.
Data-eigendom verschuift van de centrale engineeringafdeling naar de business – en de architectuur volgt eindelijk die trend. Het Lakehouse bood een uniforme opslag- en rekenomgeving. Wat het niet kon verenigen, was het eigenaarschap. Naarmate organisaties groeien, is de echte bottleneck niet de architectuur, maar het governancevacuüm dat ontstaat wanneer tientallen domeinteams data produceren zonder duidelijke verantwoordelijkheid.
Het datanetwerk gaat verder waar het lakehouse ophoudt. In plaats van alles te centraliseren in één platform dat eigendom is van één team, verdeelt het netwerk het eigenaarschap over domeinteams onder een gefedereerd bestuursmodel: het lakehouse als technische basis, Delta Lake, Apache Iceberg en Apache Hudi die interoperabiliteit tussen verschillende leveranciers mogelijk maken, en het netwerk als het operationele model erbovenop. Datacontracten tussen producenten en consumenten komen naar voren als het praktische handhavingsmechanisme, waardoor SLA's van ambitieuze doelen veranderen in operationele verplichtingen.
De markt voor data meshes laat zien hoe serieus bedrijven dit nemen: 1,5 miljard dollar in 2024, op weg naar 3,5 miljard dollar in 2030. Wanneer domeinteams eigenaar zijn van hun data en daarvoor verantwoording afleggen, AI-modellen trainen met schonere input, cross-functionele vragen niet langer in een wachtrij van de technische afdeling hoeven te wachten en het bedrijf antwoorden krijgt die de werkelijke situatie weerspiegelen.
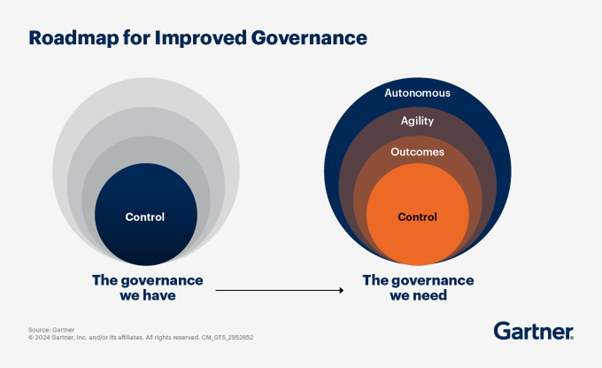
Maar slechts 18% van de organisaties beschikt over de governance-volwassenheid om dit goed uit te voeren, en 62% noemt governance nog steeds als de grootste belemmering voor de adoptie van AI . Het probleem zit hem zelden in de architectuur, maar eerder in de vraag of observability vanaf dag één is ingebouwd en of de verantwoordelijkheid voor SLA's daadwerkelijk wordt overgedragen aan de domeinteams. Gedistribueerd beheer zonder een convergentielaag ruilt simpelweg de ene bottleneck in voor de andere. 1Platform bevindt zich boven het mesh-netwerk om die kloof te dichten – het verenigt datamanagement, beslissingsintelligentie en agentische uitvoering in één beheerde laag, zodat gedistribueerd beheer de analyse-ervaring niet versnippert.
Harmonisering van Data Mesh en DDH voor een wereldwijde leider in alcoholische dranken
SLM's generaliseren niet – dat is nu juist de bedoeling. Het verfijnen van bedrijfseigen workflows zoals financiële reconciliatie, klinische documentatie of afhandeling van uitzonderingen in de toeleveringsketen vereist gelabelde, domeinspecifieke trainingsdata in grote hoeveelheden. Data uit de praktijk leveren die zelden. Uitzonderlijke gevallen zijn structureel ondervertegenwoordigd, regelgeving beperkt wat bruikbaar is voor training en annotatie op grote schaal is duur en tijdrovend.
Synthetische data is hét antwoord voor de technische wereld. Nu je dit hebt, kun je:
- Genereer de randgevallen die nooit in productielogboeken voorkomen.
- Maak trainingssets die voldoen aan de regelgeving, zonder persoonsgegevens aan te raken.
- Labelen op grote schaal zonder menselijke annotatoren.
Grand View Research schat de markt voor AI-trainingsdatasets op $3,2 miljard in 2025 en op $16,3 miljard in 2033. Synthetische data vormen het snelstgroeiende segment met een samengesteld jaarlijks groeipercentage van 30,5%. Gartner voorspelt dat synthetische data in 2030 de belangrijkste bron voor AI-training zullen worden en daarmee ook echte data.
Voor datateams betekent dit een nieuwe verantwoordelijkheidsstructuur. Synthetische datapijplijnen vereisen validatie van de dataverdeling — gegenereerde data die de variatie in de echte wereld niet weerspiegelt, produceert modellen die de evaluatie doorstaan, maar in productie stilletjes falen. Schemadekking, klassenbalans en de afwijking tussen synthetische en echte dataverdelingen moeten allemaal worden gecontroleerd en gemonitord. De kwaliteitseisen zijn identiek aan die van elke andere productiedatabron. Het verschil is dat het datateam nu de bron is, en niet alleen de beheerder.
Organisaties die dit goed aanpakken, beschouwen het genereren van synthetische data als een volwaardige technische praktijk — met versiebeheer, tests en regelgeving — en niet als een voorverwerkingsstap die wordt uitgevoerd vóór de modeltraining.
Actualiteit, schema, volume, distributie, herkomst — ontworpen voor BI-dashboards. In agentische pipelines, waar data autonome beslissingen aanstuurt, moet observeerbaarheid de traditionele normen overstijgen.
Het probleem zit hem in de beginfase. Salesforce geeft aan dat 89% van de data-leiders die AI in productie hebben genomen, te maken hebben gehad met misleidende resultaten. De meeste fouten liggen niet in het model zelf, maar in de data die eraan wordt aangeleverd. Denk aan veranderingen in de functionaliteit tussen de trainings- en de implementatiefase, schemawijzigingen die de validatie doorstaan maar de onderliggende logica verstoren, en data die te laat binnenkomen en de feedbackloop verstoren.
De 2026-stack voegt toe wat klassieke observability mist: monitoring van de featuredistributie tussen trainings- en serving-omgevingen, handhaving van datacontracten op de grens tussen producent en consument, en observability van uitkomstdata om de feedbackloop te sluiten. Teams die alleen de modellaag instrumenteren, bestrijden het symptoom. De oorzaak ligt aan de bron.
Een model kan accuraat zijn en toch onbeheersbaar. Geen traceerbaarheid van de trainingsdata. Geen documentatie over hoe de kenmerken zijn ontworpen. Geen manier om aan een toezichthouder, een auditor of een zakelijke stakeholder uit te leggen waarom het systeem een specifieke output heeft geproduceerd. In 2026 is dat geen complianceprobleem, maar een belemmering voor de implementatie.
De verschuiving die plaatsvindt binnen datateams is dat governance steeds meer wordt geïntegreerd in het bouwproces. Datacontracten worden vastgelegd voordat pipelines live gaan, in plaats van dat er pas over onderhandeld wordt nadat er iets misgaat. Kwaliteits-SLA's worden beheerd door het domeinteam dat de data produceert, in plaats van dat een centrale afdeling de data achteraf beoordeelt. Trainingsdata worden op dezelfde manier geverifieerd en gedocumenteerd als productiecode – want als een model niet goed functioneert, is de eerste vraag altijd welke data gebruikt is om het te trainen.
 Gartner
Gartner De EU AI-wetgeving, die vanaf augustus 2026 van kracht wordt, formaliseert wat toonaangevende datateams al als standaard beschouwen: het traceren van de herkomst van ruwe data tot de output van een model is een eersteklas technische prestatie. Organisaties die hierop vooruitlopen, doen niet meer governance-werk, maar hebben dit eerder geïntegreerd in de architectuur en het ontwerp van de datapipeline, waar het een fractie kost van wat het later achteraf zou kosten.
De meeste datateams in 2026 staan slechts één architectuurbeslissing verwijderd van het moment waarop hun investeringen in AI ofwel enorm groeien, ofwel juist teniet worden gedaan. Het verschil zit hem niet in het budget of het talent. Het gaat erom of de data-infrastructuur – de pipelines, de contracten, de feedbackloops, het governance-systeem – is ontworpen voor autonome besluitvorming of alleen voor rapportage.
De voorspellingen van Gartner maken de richting duidelijk. Tegen 2028 convergeert de gefragmenteerde markt voor datamanagement naar één ecosysteem rondom data fabric en GenAI. Tegen 2027 vermindert AI, geïntegreerd in data engineering tools, de handmatige tussenkomst met 60%. Tegen 2026 wordt natuurlijke taal de dominante interface voor dataverbruik. De infrastructuur wordt niet langer rondom AI gebouwd, maar erdoor herbouwd.
De organisaties die vooroplopen doen niet meer dan dat. Ze hebben eerder de juiste basis gelegd. 1Platform van Polestar Analytics brengt datamanagement, beslissingsintelligentie en agentgestuurde uitvoering samen in één beheerde laag – waardoor de kloof tussen wat de data zegt en wat het bedrijf ermee doet geen architectuurprobleem meer is.