
Vat dit blogbericht samen met:
Noot van de redactie:
In dit artikel over Data Lakehouse beantwoorden we de hamvraag: Data Warehouse, Data Lakehouse of Data Lake? We geven een korte samenvatting van de redenen en de ontwikkeling ervan. Lees verder als je de nuances van Lakehouse ten opzichte van Databricks en Fabric wilt begrijpen!
Bevind je je in deze situatie: verveeld door het feit dat iedereen het over Gen AI heeft, terwijl je in werkelijkheid alleen maar het grootste obstakel ziet? De data. Het huidige data-, machine learning- en AI-landschap is een goed voorbeeld van de verwarrende situatie rond data en ziet er ongeveer zo uit:
 Ik ben Mattturk en Firstmark zeer dankbaar voor dit fantastische onderzoek.
Ik ben Mattturk en Firstmark zeer dankbaar voor dit fantastische onderzoek. Kort samengevat: het MAD-landschap is net zo chaotisch als de verborgen lagen van neurale netwerken.
Maar aangezien 72% van de best presterende CEO's (volgens IBM) aangeeft dat concurrentievoordeel afhangt van wie beschikt over de meest geavanceerde generatieve AI en kunstmatige intelligentie; en machine learning de topprioriteit is voor bedrijven (diverse rapporten) – vinden wij het belangrijk om de volgende vraag te stellen: Zijn uw data daadwerkelijk in staat om dit alles te ondersteunen?
Om deze vraag te beantwoorden, gaan we even terug in de tijdlijn van de data, om te zien hoe de databehoeften en de behoeften op het gebied van databeheer zich hebben ontwikkeld:
- Tijdperk 1.0: Bedrijven wilden inzichten uit hun data halen, dus bouwden ze datawarehouses bovenop hun data met schema-on-write-functionaliteit ter ondersteuning van business intelligence. Maar het probleem ontstond met de toenemende hoeveelheid ongestructureerde datasets, de kosten voor piekbelastingen en de groeiende behoefte aan complexe analyses. Geen van de toonaangevende ML-systemen, zoals TensorFlow, PyTorch en XGBoost, werkt namelijk goed bovenop datawarehouses. ML-systemen moeten grote datasets verwerken met behulp van complexe, niet-SQL-code.
- Tijdperk 2.0: Om het offloaden van ruwe data in goedkope en open formaten zoals Parquet te ondersteunen, terwijl tegelijkertijd systemen worden ondersteund die niet-SQL-code verwerken, zijn we het tijdperk van Data Lakes met een schema-on-read-architectuur ingegaan. Deze Data Lakes verloren echter de uitgebreide data management-functies die nodig zijn voor ACID-transacties, indexering, enzovoort, en die wel aanwezig waren in Data Warehouses.
- Tijdperk 3.0: De combinatie van data lake en datawarehouse – ofwel de tweelaagse architectuur – waarbij een subset van de data uit het data lake via ETL naar een datawarehouse wordt overgebracht voor verdere analyse en business intelligence-toepassingen. Hoewel dit zowel BI als AI ten goede komt, kunnen de complexiteit van de extra ETL-stappen, de verandering in semantiek, de SQL-dialecten en de ondersteunde gegevenstypen verschillen. Bovendien neemt de kans op fouten en bugs toe.
- Tijdperk 4.0: Het huidige tijdperk van Data Lakehouse – om de semantische flexibiliteit en opslag van een data lake te combineren met de rekenkracht en levering van een datawarehouse, oftewel om de wrijving tussen dataverbruik en -opname te elimineren of te verminderen.
Data Lakehouse is een hybride platform voor gegevensopslag en -verwerking dat het beste van traditionele data lake- en data warehousingtechnologieën combineert: goedkope opslag in een open formaat dat toegankelijk is voor diverse systemen (van de eerste) en krachtige beheer- en optimalisatiefuncties (van de laatste).
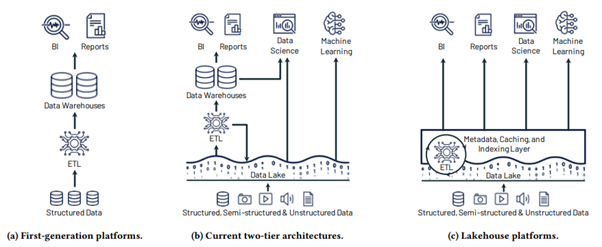 De evolutie van een architectuur met twee lagen naar een data lakehouse.
De evolutie van een architectuur met twee lagen naar een data lakehouse. De lakehouse-architectuur, die je terugvindt in Databricks, Microsoft Fabric, enzovoort, is erop gericht de kosten, operationele overhead en complexiteit te verminderen die gepaard gaan met het samenbrengen van data voor diverse doeleinden, van business intelligence tot kunstmatige intelligentie.
Hoewel de opmars van data lakehouses begon bij Uber en vervolgens Netflix, is het merendeel van de Fortune 500-bedrijven er inmiddels mee aan de slag gegaan. Drie van de belangrijkste voordelen van het gebruik van een data lakehouse zijn:
- Minder verouderde data: Ongeveer 70-80% van de analisten gebruikt verouderde data. Doordat alle data op één plek en in één formaat worden opgeslagen, krijgt u meer controle over uw data.
- Een uniform platform voor alle data-analyse: Data lakehouses kunnen een locatie bieden voor BI, SQL-analyses en meer geavanceerde analyses, waaronder machine learning, aangezien veel ML-bibliotheken, zoals TensorFlow en Spark MLlib, al data lake-bestandsformaten zoals Parquet kunnen lezen.
- Lagere kosten: U kunt mogelijk voorkomen dat organisaties twee keer moeten betalen voor de opslag van dezelfde gegevens, zoals vaak het geval is wanneer ze zowel een datawarehouse als een datalake gebruiken. Bovendien zijn commerciële datawarehouses vaak gebonden aan eigen bestandsformaten, wat kostbaar kan zijn, terwijl datalakes gebruikmaken van open formaten.
Hoewel we het al over alle drie hebben gehad en hoe de evolutie in datamanagement de noodzaak voor meer dan één ervan heeft aangetoond, zullen we proberen ze zo eenvoudig mogelijk met elkaar te vergelijken.
Van de groeiende behoefte aan wendbaarheid tot het snel kunnen inspelen op veranderingen – de noodzaak om kosten in evenwicht te brengen met de toenemende behoefte aan databeheer wordt met Data Lakehouse gerealiseerd.
Verschillen tussen een datawarehouse, een datalake en een datalakehouse
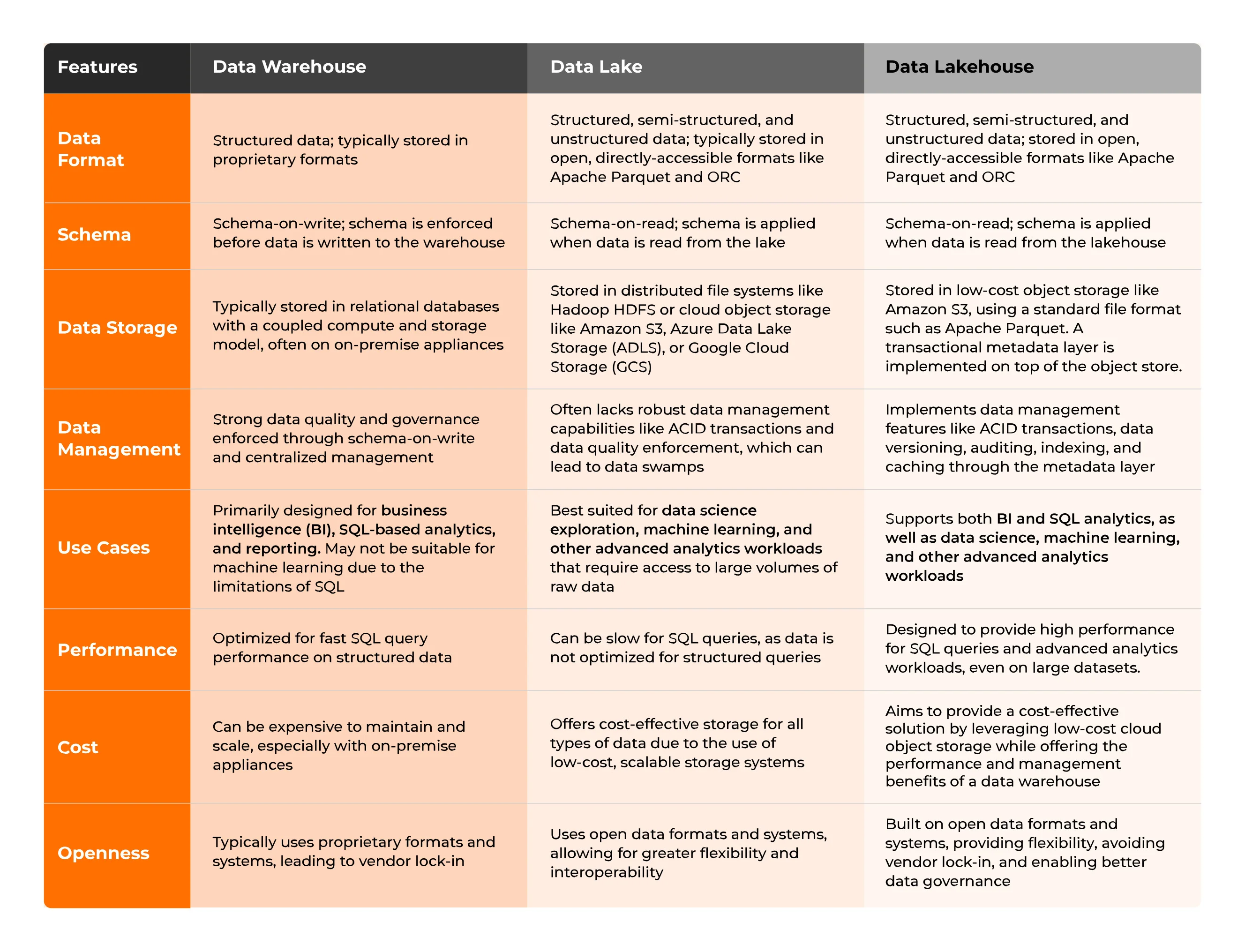 Het tonen van de verschillen op basis van diverse parameters zoals dataformaat, schema, openheid, prestaties, enz.
Het tonen van de verschillen op basis van diverse parameters zoals dataformaat, schema, openheid, prestaties, enz. Kort samengevat: een data lakehouse slaat gegevens op in een vergelijkbaar formaat als een data lake, maar de transactionele metadata-laag definieert welke objecten deel uitmaken van een tabelversie, net als bij een datawarehouse. Dankzij de grotere flexibiliteit en interoperabiliteit van data lakes en de mogelijkheid tot ACID-transacties zoals bij datawarehouses, is een data lakehouse een combinatie van beide concepten.
Het doel van een data lakehouse is nu vast wel duidelijk. Laten we daarom eens kijken hoe we het implementeren. Een typische data lakehouse-architectuur bestaat uit 5 lagen, namelijk:
- Invoerlaag: Verzamelt gegevens uit meerdere bronnen, zoals transactiegegevens, CRM en NoSQL-databases, en zet deze om in een opslagbaar formaat.
- Opslaglaag: Deze wordt doorgaans opgeslagen in een goedkoop opslagformaat, zoals de gebruikelijke cloudobjectopslag, bijvoorbeeld Amazon S3, Azure Data Lake Storage (ADLS) of Google Cloud Storage (GCS) - in open, direct toegankelijke formaten zoals Apache Parquet en ORC.
- Metadata-laag: Deze laag, uniek voor Data Lakehouse, bevindt zich bovenop de opslag van het data lake. Deze laag beheert de tabelindeling en houdt de bestanden bij, terwijl functies zoals schemahandhaving, versiebeheer, auditing, enzovoort mogelijk worden gemaakt. Voorbeelden van metadata-lagen zijn Delta Lake, Apache Hudi en Apache Iceberg.
- API-laag: Deze laag maakt het mogelijk om gegevens op te vragen met SQL API's voor traditionele BI en SQL-analyses, en met declaratieve DataFrame API's voor data science en machine learning-workloads.
- De dataverbruikslaag: van BI-tools voor dashboards, data science en machine learning voor het modelleren van data, realtime-applicaties voor het streamen van data, tot het delen van data tussen samenwerkende partijen – deze laag stelt gebruikers in staat om data op verschillende manieren te gebruiken en ermee te interageren.
 De 5 lagen van een Data Lakehouse-architectuur worden belicht.
De 5 lagen van een Data Lakehouse-architectuur worden belicht.
Met de komst van Microsoft Fabric en One Lake, oftewel Azure Data Lakehouse, is het concept gangbaarder geworden. Het is belangrijk om te vermelden dat de "Curated layer" (in een Microsoft Fabric-architectuur) indien nodig kan worden vervangen door een datawarehouse. Een lakehouse in Fabric kan zeer eenvoudig worden opgezet met de volgende opties.
Meer informatie over de architectuur van Azure Data Lakehouse en hoe u hiermee aan de slag kunt, vindt u hier .
Met Databricks Lakehouse is het eenvoudig om ETL-pipelines te automatiseren en te orkestreren. Voorheen was je waarschijnlijk al bekend met Azure Databricks (dat meestal wordt gebruikt met Azure Synapse ) of hun Delta Live-tabellen om de complexiteit van infrastructuurbeheer, taakorkestratie, foutafhandeling, enzovoort te doorgronden.
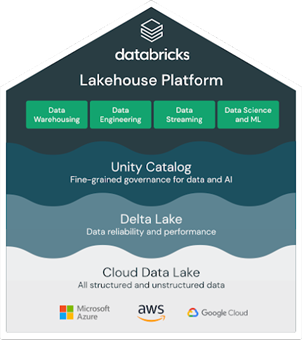 Bron: Databricks
Bron: Databricks Er zijn uiteraard ook andere spelers op de markt, zoals Amazon Redshift, Google Cloud BigQuery, Salesforce Data Cloud, Apache Hudi en meer. Belangrijke overwegingen bij de keuze tussen deze oplossingen zijn: prestaties, kosten, datavariëteit, schaalbaarheid, integratiemogelijkheden en governance.
We hebben de voordelen van een data lakehouse gezien, zoals lagere kosten in vergelijking met een architectuur met twee lagen, een vereenvoudigde architectuur voor het voorbereiden van gegevens, verhoogde betrouwbaarheid door minder problemen met de datakwaliteit en duplicatie, verbeterd beheer door consolidatie en een grotere schaalbaarheid voor de toekomst.
Naarmate organisaties de waarde ervan inzien, vooral in dit AI-tijdperk, zal het een cruciale rol spelen bij het stimuleren van datagedreven besluitvorming en innovatie. De toekomst van data lakehouses ziet er rooskleurig uit en hun voortdurende ontwikkeling zal ongetwijfeld de volgende generatie dataplatformen vormgeven – het enige wat u nog hoeft te doen, is het goed implementeren.
Neem contact op met onze data-engineeringexperts om te zien waar en hoe dit past in uw datamanagementstrategie.