
Vat dit blogbericht samen met:
Wacht, niet helemaal "de Monica". Maar je kunt je er zeker in herkennen, en iedereen die ooit naar Friends heeft gekeken, zal dit zich herinneren:

Laten we het iets breder trekken: het gaat niet alleen om mensen tevreden stellen (wat uiteindelijk het doel is) , maar ook om te begrijpen waar mensen het over hebben en daarop gepast te reageren. Dus waar we het vandaag over gaan hebben, is hoe je kunt achterhalen of mensen tevreden zijn of dat je het soms gewoon niet begrijpt.
Het basisidee van sentimentanalyse is het contextueel analyseren of opinieonderzoek van een tekst om de toon en het sentiment ervan te bepalen als positief, negatief of neutraal. In de praktijk maakt sentimentanalyse gebruik van Natural Language Processing (NLP)-technieken op teksten, sociale mediagegevens of recensies om inzichten te verkrijgen over de klant of het product.

Vond je de definitie eenvoudig? Wil je meer weten over de verschillende typen en hoe het werkt? Wacht nog even, want eerst is het belangrijk om te begrijpen hoe het gebruikt moet worden. Zijn er voorbeelden waarbij de resultaten van sentimentanalyse niet helemaal volgens plan verliepen? Laten we vandaag niet beginnen met een prijswinnend voorbeeld, maar met iets waar we een waarschuwing bij moeten geven.
Morbius
Sony bracht Morbius in juni 2022 opnieuw uit, maar was dat wel de juiste keuze? Hoewel er veel discussie is over de heruitgave, is het belangrijk om te begrijpen waarom ze dat deden. Twittergebruikers prezen de film sarcastisch, verzonnen citaten en uitspraken als "It's Morbin' Time", en Sony interpreteerde dit verkeerd als lof. Oké, dat betekent niet dat we je afraden om sentimentanalyse te doen, maar wel dat het niet absoluut is (sarcasme kan meer kwetsen dan alleen gevoelens, ook die van een machine learning-gebruiker). Wat we bedoelen is dat het met de nodige voorzichtigheid en in de juiste context bekeken moet worden.
Het Morbius-team had bijvoorbeeld aanvullende gegevens zoals reacties kunnen controleren en deze kunnen vergelijken met andere releases, wat het onderzoek van BuzzSumo hieronder prachtig samenvat:
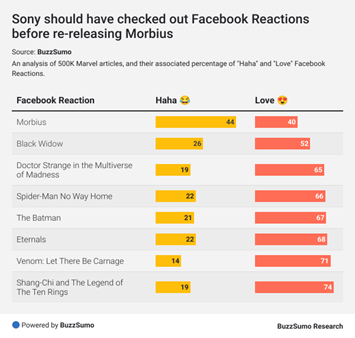
Bron: BuzzSumo Research
Dit laat zien dat data soms context nodig heeft en in vergelijking met andere films bekeken moet worden. De bovenstaande data toont het verschil in reacties tussen Morbius en andere Marvel-films.
KPMG
Iedereen weet dat KPMG een advies- en auditkantoor is, waardoor tekstuele analyse van groot belang is voor de organisatie. Er zijn twee situaties waarin contextuele data mining bijzonder belangrijk is voor een bedrijf als KPMG.
Duurzaamheidsverslagen zijn rapporten die over het algemeen openbaar en voor investeerders toegankelijk zijn en waarin bedrijven hun economische, ecologische en maatschappelijke impact beschrijven. KPMG is als auditbedrijf gekwalificeerd om te analyseren of de rapporten gepubliceerd kunnen worden, oftewel of ze evenwichtig zijn (niet alleen de positieve aspecten, maar ook de negatieve, zodat mensen een juiste beoordeling kunnen maken). KPMG moest echter de hindernis van positief geformuleerde negatieve beweringen overwinnen, waarvoor het bedrijf gebruikmaakte van Bidirectional Encoder Representation (BERT) van Google. KPMG gebruikt ook tekstanalyses om patronen en trefwoorden te detecteren en zo compliance-risico's te signaleren.
De beruchte zaak Johnny Depp - Amber Heard
Allereerst wil ik geen partij kiezen, maar alleen een analyse bespreken die beide partijen hebben gepresenteerd over de tweets met een aantal hashtags, waaronder #justiceforjohhnydepp. In dit geval presenteerde een adviseur op het gebied van intellectueel eigendom de "maatschappelijke opinie" met
- Aantal tweets
- Tijdstip van tweets
- Inhoud
- Sentiment
- Hypothesetoetsing
Als dataliefhebber vond ik de manier waarop hij de data-extractie en -analyse van de Twitter API's uitlegde erg boeiend. Het biedt ook een doorsnee gebruiker de mogelijkheid om zich in de details van de analyse te verdiepen. Ze probeerden correlaties te analyseren tussen de uitspraken en de tijd, evenals het sentiment van de tweets in het algemeen.
Ongeacht de oplossing was het geweldig om te zien dat Data Science vertegenwoordigd en begrepen werd door iedereen. Er zijn wel nadelen, zoals de noodzaak om bij het zoeken de volledige zinnen of woorden exact te gebruiken. Typfouten kunnen niet alleen verwarring veroorzaken, maar ook het systeem omzeilen. (Voor fans van "The Office": hoe Michael Scott Dwight niet kon vervangen door Samuel L. Chang.)
Wilt u het consumentensentiment beter in kaart brengen?
Analyseer de beschikbare gegevens van uw e-commerceplatforms en achterhaal de achterliggende intentie.
Als u denkt dat dit het einde is van de toepassingsvoorbeelden, dan vergist u zich. Dit zijn slechts enkele praktijkvoorbeelden; we zullen later uitgebreider ingaan op de toepassingsmogelijkheden van sentimentanalyse, nadat we hebben besproken hoe sentimentanalyse in de praktijk werkt.
Bouwstenen van sentimentanalyse
Natuurlijke taalverwerking vormt de basis van sentimentanalyse en verdere analyses zoals intentieanalyse. Afhankelijk van de hoeveelheid te analyseren data zijn er verschillende manieren om data te analyseren. Deze vallen grofweg in twee categorieën: regelgebaseerd en automatisch.
Regelgebaseerde aanpak
Zoals de naam al doet vermoeden, wordt de regelgebaseerde aanpak gebruikt om het onderwerp en de mening daarover te identificeren. Enkele fasen die in een regelgebaseerde aanpak voor tweets of teksten worden doorlopen (in willekeurige volgorde) zijn:
- Transformatie: De tekst wordt omgezet naar kleine letters, waarbij HTML, accenten en URL's uit de gegevens worden verwijderd.
- Tokenisatie: Dit is de methode om tekst op te splitsen in kleinere woorden, waaronder verschillende vormen zoals woord en leesteken, witruimte, zin, reguliere expressie en tweet. We gebruiken hier het patroon van reguliere expressies.
- Normalisatie: dit omvat het stammen en lemmatiseren van woorden. Ook hiervoor bestaan verschillende typen, zoals de Porter Stemmer, Snowball Stemmer, WordNet Lemmatizer (die een netwerk van cognitieve synoniemen toepast op tokens op basis van een grote lexicale database van het Engels), UDPipe (dat een vooraf getraind model gebruikt voor het normaliseren van gegevens), enzovoort.
- Filteren en kassalabeling
Als je ze allemaal tegelijk wilt zien, is hier een voorbeeld van de verschillende fasen van het voorbewerken van tekst in Orange , met de afbeelding hieronder:
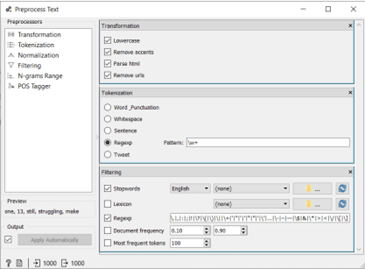
De nadelen van een op regels gebaseerd systeem zijn dat het niet geavanceerd genoeg is om te verwerken hoe woorden zich combineren tot zinnen, en dat het verfijning, testen en onderhoud vereist om goed te functioneren.
Automatische aanpak
Deze methode maakt gebruik van machine learning-technieken om teksten te modelleren als een classificatieprobleem, waarbij ze worden gesegmenteerd in positieve, negatieve of neutrale teksten. Omdat de gebruikte modellen machine learning zijn, worden eerst trainingsgegevens gebruikt, waarop de feature-extractie en classificatie plaatsvinden. Nadat de trainingsgegevens zijn verwerkt, wordt de daadwerkelijke dataset gebruikt om de resultaten te verkrijgen.
Het voordeel van het gebruik van een machine learning-model is dat het niet alleen getraind kan worden op basis van drie parameters of tags (PNN), maar ook op basis van meer parameters. Zo biedt de visualisatie van sentiment in tweets bijvoorbeeld een breed scala aan emoties om de resultaten in kaart te brengen.

Elk type data vereist een zekere mate van voorbereiding, zoals we besproken hebben bij de regelgebaseerde aanpak, bijvoorbeeld tekstvectorisatie, Bag of Words, Bag of n-grams, enzovoort.
De classificatiealgoritmen die in dit geval worden gebruikt, kunnen de volgende zijn:
- Meervoudige regressie: een zeer bekend algoritme in de statistiek dat wordt gebruikt om de waarde van de onafhankelijke variabele te voorspellen op basis van meerdere afhankelijke variabelen.
- Naïeve Bayes: Gebruikt de stelling van Bayes om de categorie van een tekst te voorspellen (probabilistisch model).
- Support Vector Machines (SVM's): een niet-probabilistisch model dat zowel classificatie als regressie ondersteunt en punten in een multidimensionale ruimte uitzet. Het projecteert punten op hypervlakken die de klassen onderscheiden.
- Neurale netwerken: door woorden met vergelijkbare betekenissen en vectorwaarden weer te geven met behulp van technieken uit Deep Learning en kunstmatige neurale netwerken (ANN).
Naast deze twee modellen kunt u ook een hybride model gebruiken met een combinatie van automatische en op regels gebaseerde benaderingen. We gaan hier niet specifiek op in, omdat we de technieken en methoden die in beide modellen worden gebruikt al uitgebreid hebben besproken. Laten we het nu hebben over het gebruik van sentimentanalyse voor organisaties.
Hoewel we hierboven al een paar voorbeelden hebben besproken van sociale sentimentanalyse, tekstmining, enzovoort, laten we het nu eens hebben over de toepassingen van sentimentanalyse voor bedrijven op het gebied van marketing, branding, onderzoek en klantenservice. Enkele voorbeelden van toepassingen van sentimentanalyse zijn:
1. Intentieanalyse
Dit is de volgende stap in sentimentanalyse, namelijk het begrijpen van de intentie achter een reactie, tweet, tekst of vraag. Intentieanalyse gaat bijvoorbeeld over het achterhalen waar de boodschap over gaat, of het nu nieuws, een mening, een advertentie, een suggestie, een vraag, enzovoort is. Dit kan niet alleen helpen bij het vinden van de relevante toon, maar ook bij het classificeren van het soort berichten dat wordt ontvangen.
2. Merkmanagement
Merkimago is belangrijk voor zowel bedrijven als mensen. Om terug te komen op Monica's citaat (uit FRIENDS): je wilt dat iedereen je aardig vindt, maar hoe kijk je daar eigenlijk naar? Het checken van de Google-rating kan nu als ouderwets worden beschouwd, vooral voor bedrijven met een grote aanwezigheid op sociale media. Tegenwoordig draait alles om het analyseren van wat mensen daadwerkelijk denken, met name bij de lancering van nieuwe producten en diensten. Alle gedeelde informatie, zoals stories, blogs, forums, enzovoort, is data en al deze informatie kan worden omgezet in inzichten, al is het maar om het sentiment op sociale media te monitoren.
3. De stem van de klant
Een eenvoudig antwoord op de vraag "Waarom?" is: Om te verbeteren. Neem bijvoorbeeld bedrijven zoals Airbnb, hotels of restaurants. Hun belangrijkste data is de feedback van klanten, en dan vooral de negatieve recensies. Weet je nog dat Monica een negatieve recensie schreef en de chef-kok probeerde te leren hoe hij het gerecht moest maken, en daardoor de baan kreeg? (Als je geen fan bent van Friends, negeer dit dan maar!) Kortom, het gaat erom hoe je negatieve recensies kunt analyseren en omzetten in concrete acties die een significante impact hebben op toekomstige bestellingen.
4. Feedback van medewerkers
Niet alles draait om de winst of omzet van een organisatie; het is ook belangrijk om te kijken naar de gezondheid van de organisatie in relatie tot de medewerkers. Hoewel bedrijven een Employee Mood Index kunnen gebruiken om de stemming onder medewerkers te peilen, of een interne NPS (Net Promoter Score), kan het analyseren van feedback inzicht geven in: a) de gebieden waar de meeste medewerkers zich zorgen over maken, b) het algemene sentiment ten aanzien van de werk-privébalans en c) meer ideeën om de productiviteit te verhogen. Niet alleen de feedback van bestaande medewerkers, maar ook gegevens uit bronnen zoals Glassdoor, reviews, enzovoort, zijn hierbij relevant.
5. Marktonderzoek
Bij de lancering van een nieuw product of een nieuwe dienst kunt u uw product bestuderen, analyseren en vergelijken met een bestaand product, met name dankzij de vele feedback en recensies die online beschikbaar zijn. U kunt ook de demografie van de gebruikers die het product gebruiken in kaart brengen, of markttrends analyseren aan de hand van officiële tijdschriften en rapporten. Door zowel kwalitatieve als kwantitatieve bronnen te analyseren, kunt u nieuwe informatiebronnen aanboren.
6. Monitoring van sociale media
We hebben al twee verschillende voorbeelden besproken waarin sociale media een rol hebben gespeeld. Door bij te houden wat er gebeurt, waarover gesproken wordt en hoe mensen het waarnemen, krijgen zowel bedrijven als mensen een beter inzicht in hoe ze in de toekomst moeten handelen. Waarom? Denk bijvoorbeeld aan de keren dat mensen video's deelden over slechte klantenservice, of aan de keer dat Game of Thrones onbedoeld Starbucks sponsorde nadat een paar mensen de bekers in een paar scènes hadden opgemerkt, of aan de slechte reputatie die luchtvaartmaatschappijen kregen door overboekte vluchten.
Dit zijn slechts enkele bekende en veelgebruikte voorbeelden van sentimentanalyse. Als je dieper graaft, vind je er nog veel meer, zoals reviewanalyse voor webwinkels, of hoe McKinsey een sentimentanalysetool genaamd City Voices ontwikkelde voor de afdeling stadsplanning van Brazilië. Je kunt natuurlijk ook altijd zelf een nieuwe toepassing bedenken.
Benieuwd wat Retail 4.0 betekent voor de technologiesector?
Met dit e-book krijgt u inzicht in het volgende tijdperk van de retailrevolutie en de drijvende technologieën erachter.
Beloofd, we naderen het einde van deze discussie, maar in plaats van de gebruikelijke weg te bewandelen en de voordelen van sentimentanalyse te bespreken, wil ik graag even stilstaan bij de uitdagingen. (Uiteraard zijn er uitdagingen wanneer we een machine de emoties achter toon en tekst willen laten begrijpen).
Ironie en sarcasme: De heruitgave van Morbius is daar een levend voorbeeld van. Ik denk niet dat we hier nog eens op terug hoeven te komen! We hebben een Chandler nodig om de data te trainen.
Context: Voor iemand die Friends heeft gezien, heeft de vraag "What you doin'?" een andere betekenis dan voor iemand die dat niet heeft gedaan. Daarom kan het nodig zijn om tijdens de verwerking of voorbewerking van gegevens context te hebben. Bijvoorbeeld: "Nee!" klinkt negatief, maar als de vraag zou zijn: "Vond je het vreselijk?", dan zou de context positief zijn.
Vergelijking: A is beter dan B is algemeen bekend. Maar wanneer de beweringen slechts beter zijn dan niets hebben, kan het lastig zijn om dit als een negatieve bewering te classificeren.
Emoji's: Welkom in de 20e eeuw, waar emoji's, vooral in tweets, een veel grotere rol spelen dan tekst. Je zou ze kunnen verwijderen of hun Unicode-tekens afzonderlijk aan emoties kunnen toewijzen. Twijfel je aan onze bewering? Kijk dan naar de afbeelding hieronder. Wat is het enige verschil tussen de twee antwoorden? Een emoji. De tweede emoji is voor een mens duidelijk sarcastisch, maar voor een bot is dat waarschijnlijk niet het geval. Niet goed getest, dus de interpretatie is twijfelachtig.

Definitie van Neutraal: Deze categorie, die zich ergens tussen positief en negatief bevindt, kan lastig te bepalen zijn, tenzij de data goed getraind is. De data moet objectief zijn, geen irrelevante informatie bevatten en wensen, enzovoort, moeten begrepen worden.
Bedankt dat je tot het einde van de discussie bent gebleven, ik hoop dat je het met plezier hebt gelezen.
Kortom, wat we willen zeggen is dat sentimentanalyse , opinieonderzoek of contextuele analyse – hoe je het ook wilt noemen – belangrijk is, vooral nu gezien de enorme hoeveelheid data die organisaties tot hun beschikking hebben om te analyseren, en omdat API's het steeds gemakkelijker maken om data te integreren en te ontsluiten.
Wat houdt je tegen? Wil je hulp? Neem vandaag nog contact met ons op!