
Vat dit blogbericht samen met:
| Van signaalkwaliteit tot Agentic AI: ontdek hoe vraagvoorspelling en S&OP-integratie de autonome planning, governance en omzetgroeimanagement hervormen. |
Leiders in de toeleveringsketen hebben tien jaar lang de nauwkeurigheid van prognoses met enkele procentpunten verbeterd. Vervolgens gaven ze die prognose over aan een autonoom systeem en noemden dat transformatie.
De voorspellingsfout is niet veranderd. Wat wél veranderd is, is de manier waarop ermee wordt omgegaan. Volgens onderzoek ligt de mediane voorspellingsfout in de voedingsmiddelen- en drankenindustrie rond de 25%. Bij duurzame consumentenproducten loopt deze op tot 50%. Het wordt pas echt interessant wanneer we agentsystemen inzetten om beslissingen te nemen over aanbod, prijsstelling en allocatie bovenop die fout – in realtime, zonder menselijke controle om de fout eerst te ontdekken. Gartner voorspelt dat 50% van de oplossingen voor supply chain management in 2030 intelligente agenten zal integreren. Denk eens aan de gevolgen.
Een vertekende prognose in een maandelijkse S&OP-cyclus kost je een slecht kwartaal. Dezelfde vertekende prognose die een autonome agent voedt, kost je continu geld – in een razend tempo.
Het foutenpercentage is niet het probleem, maar een symptoom. Organisaties die hun voorspellingen goed doen, doen niets bijzonders – ze pakken de fundamentele zaken in de juiste volgorde aan. Signaalkwaliteit vóór methodologie. Methodologie vóór integratie. Integratie vóór automatisering.
Die volgorde wordt in dit stuk in kaart gebracht.
Voordat je de volgorde kunt aanpassen, moet je eerst begrijpen wat de oorzaak is van de problemen. De meeste mislukkingen bij prognoses zijn geen methodologische fouten, maar fouten in de methodologie zelf. Denk bijvoorbeeld aan de juiste techniek toegepast op de verkeerde SKU, de verkeerde data of de verkeerde planningshorizon. Het is nuttiger om te begrijpen waar de problemen precies zitten, dan te discussiëren over welke methode beter is.
Laten we daarmee beginnen.
Twee methodenfamilies domineren de moderne vraagvoorspelling.
FAMILIE 1 - Statistische methoden (ARIMA, exponentiële gladmaking, Holt-Winters)
Ontwikkeld voor stabiliteit. Presteert goed bij SKU's met een hoog volume, een vraaggeschiedenis van meer dan 18 maanden en een lage afhankelijkheid van externe factoren. Snel, transparant en verklaarbaar in een S&OP-evaluatie. De juiste basis voor het voorspellen van de kernportfolio.
| Situatie | Aanbevolen methode |
|---|
| Stabiele vraag | Voortschrijdend gemiddelde / SES |
| Trend + Seizoensgebondenheid | Holt-Winters |
| Sterke autocorrelatie | ARIMA |
| Prijs- en promotie-impact | Regressie / ARIMAX |
| Intermitterende vraag | Croston (SBA) |
| Planning op meerdere niveaus | Hiërarchische verzoening |
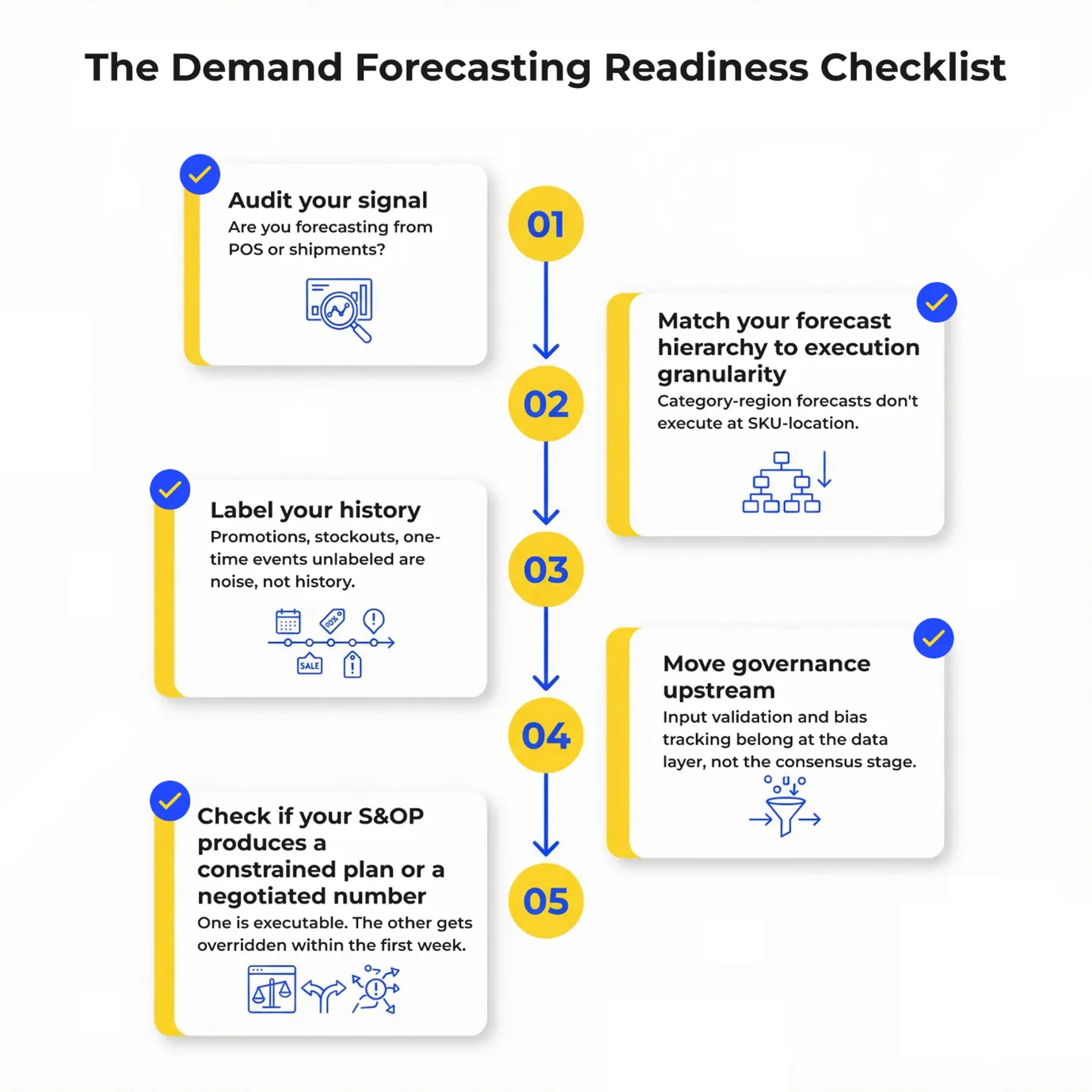
Ze breken af onder drie specifieke omstandigheden: promotieperiodes, introductie van nieuwe producten en externe vraag. En hier is de factor die de meeste teams over het hoofd zien: de meeste organisaties voorspellen op basis van verzendgegevens, niet op basis van verkoopgegevens. Verzendgegevens weerspiegelen wat je hebt besloten te verzenden. Verkoopgegevens weerspiegelen wat consumenten hebben besloten te kopen. Voorspellen op basis van verzendgegevens van een gepromoot product betekent dat je model je eigen aanbodgedrag leert, niet dat van de markt. De basislijn lijkt stabiel. De werkelijke vraag daaronder is dat niet.
FAMILIE 2 - Op ML gebaseerde modellen (Gradient Boosting, LSTM, Ensemble Frameworks)
Ze kunnen omgaan met causale complexiteit die statistische methoden niet aankunnen. Niet-lineaire interacties tussen prijs, promotie, acties van concurrenten en externe signalen vallen precies binnen hun expertisegebied. Maar ze stellen hoge eisen aan de data: voldoende volume op voorspellingsniveau, duidelijke gebeurtenislabels over de gehele trainingsperiode en een voor voorraadtekorten gecorrigeerde historie – zodat het model een leveringsprobleem niet aanziet voor een vraag van nul.
Als je machine learning toepast op schaarse of vervuilde data, is het niet vanzelfsprekend dat het mislukt. Het genereert zelfverzekerde, foute voorspellingen in richtingen die moeilijker te diagnosticeren zijn dan een simpele ARIMA-misser. Je hebt interpreteerbare mislukking ingeruild voor ondoorzichtige mislukking.
| Scenario | ML-model |
|---|
| Tabelgegevens + promoties | XGBoost / LightGBM |
| Lange sequentiële gegevens | LSTM / GRU |
| Veel SKU's + probabilistische prognose | DeepAR / TFT |
| Hoge interpreteerbaarheid vereist | GBM + SHAP |
| Kleine dataset | SVR |
De regel: statistische basislijnen voor stabiele SKU's met duidelijke signalen. Machine learning (ML) wordt ingezet wanneer er causale factoren aanwezig zijn, een gelabelde promotiegeschiedenis, voldoende volume en voor voorraadtekorten gecorrigeerde gegevens. Gebruik ML nooit om dataproblemen te compenseren die stroomopwaarts moeten worden opgelost.
Delphi, Salesforce Composite, marktonderzoek, expertbeoordelingen – deze methoden vervangen kwantitatieve modellen niet. Ze kalibreren ze. Voor de introductie van nieuwe producten, markttoetredingsscenario's en vraagverschuivingen die voortkomen uit inzichten die nog niet in uw historische data zijn vastgelegd, vult gestructureerde kwalitatieve input de leemte op die statistische en machine learning-methoden niet kunnen vullen. Het sleutelwoord is gestructureerd – ongestructureerde meningen die zonder toezicht in een prognose worden verwerkt, zorgen ervoor dat vooringenomenheid via de voordeur binnensluipt.
Nog een dimensie die alle drie doorkruist: de voorspellingshiërarchie. De nauwkeurigheid van de prognose maskeert fouten op SKU-locatieniveau. S&OP-beslissingen worden uitgevoerd op SKU-locatieniveau: welk distributiecentrum welk volume verwerkt, welke productielijn welke variant produceert. Dát is waar de prognose correct moet zijn – niet op het niveau dat er goed uitziet in een presentatie voor de directie. En het maakt allemaal niets uit als de input gefragmenteerd, vertraagd of onzuiver is. Het model kan geen onderscheid maken tussen een probleem met de datakwaliteit en een vraagsignaal. Het leert van beide.
Vraagvoorspelling eindigt niet wanneer je een getal hebt gegenereerd. Dan begint het pas echt belangrijk te worden.
Het S&OP-proces is de fase waarin prognoses ofwel leiden tot gecoördineerde actie, ofwel sneuvelen in een consensusvergadering. Wanneer de basis voor de prognoses solide is, heeft elke fase concrete gegevens om mee te werken. Is dat niet het geval, dan erft en versterkt elke volgende fase de fout.
Hieronder ziet u hoe forecasting een directe impact heeft op elke S&OP-fase:
| S&OP-fase | Voorspellingsgegevens vereist | Wat gaat er kapot zonder? |
|---|
| Statistische vraagbeoordeling | Schone basislijn op SKU-regioniveau. POS, niet verzendingen. | De basislijn erft het aanbodgedrag, niet de vraag. Vooroordelen worden ongemerkt ingeslopen. |
| Onbeperkt vraagplan | Marktgedreven prognose, onafhankelijk van operationele beperkingen. | S&OP onderhandelt vanuit een verkeerd uitgangspunt. Politiek vult de data-lacune op. |
| Consensusvraagplan | Afstemming tussen verschillende afdelingen op één cijfer met tracking van overrides. | Overrides stapelen zich op zonder feedback. Modellen leren niets. Vooroordelen verergeren. |
| Beperkt aanbodplan | De gevalideerde vraag wordt afgestemd op de capaciteit en de voorraad. | De uitvoering ontvangt een plan dat losstaat van de operationele realiteit. |
| Pre-S&OP-evaluatie | Vraagvarianten op basis van scenariomodellen met betrouwbaarheidsintervallen. | Leidinggevenden nemen afwegingsbeslissingen zonder rekening te houden met de onzekerheid van de voorspellingen. |
| Executive S&OP | Financieel afgestemd vraagplan met risico-indicatoren. | Strategische beslissingen worden op basis van consensus genomen, niet op basis van waarschijnlijkheid. |
| S&OE-uitvoering | Hoogfrequente vraagdetectie. Realtime signaal versus planafwijking. | De wekelijkse uitvoering verloopt in het duister tussen de maandelijkse cycli. Latentie leidt tot verlies. |
Als je dit goed aanpakt, volgen de resultaten vanzelf. Organisaties die vraagvoorspellingen effectief integreren met S&OP rapporteren een verbetering van 15-20% in de afstemming tussen voorspelling en planning en een vermindering van de veiligheidsvoorraad met 10-15% – werkkapitaal dat direct weer in de bedrijfsvoering wordt geïnvesteerd.
Als de basis eenmaal goed is, voeg je er een element aan toe en verandert het beeld.
De maandelijkse S&OP-cyclus had één onderschat kenmerk: hij was te traag om zijn eigen fouten te ontdekken. Gelukkig zijn Agentic-systemen dat niet. Voorraadbeheer, prijsaanpassingen en allocatiebeslissingen worden nu autonoom uitgevoerd – met een frequentie en schaal die geen enkele menselijke beoordelingscyclus kan evenaren.
De voorspellingsfout wacht niet tot de volgende maandelijkse cyclus. Hij stapelt zich in realtime op. Dit leidt tot drie zeer specifieke verschuivingen die bepalen wat dit betekent voor de voorspellingspraktijk:
- De afstemmingscycli worden verkort van weken tot uren.
Agentsystemen handelen op basis van het actuele voorspellingssignaal zonder op consensus te wachten. Als dat signaal onjuist is – zendingen niet op het verkooppunt, promoties zonder label, niet-gecorrigeerde voorraadtekorten – handelt de agent vol vertrouwen op basis van onjuiste informatie. De overlegvergadering die dit had kunnen signaleren, bestaat dan niet meer.
- De beslissingsvertraging verdwijnt, en daarmee ook het correctievenster.
De vertraging bij de planning betekende ook bedenktijd — tijd om de cijfers te bevragen, te toetsen aan marktinformatie en in te grijpen wanneer iets niet klopte. Autonome uitvoering elimineert die periode. De kwaliteit van de prognose is niet langer een ongemak voor de planning, maar een operationeel risico.
- De timing van de governance verschuift naar een eerder stadium.
Bij een handmatig proces vindt governance plaats in de consensusfase. Bij agentsystemen is een foute beslissing al genomen – waarschijnlijk honderden keren – voordat deze zichtbaar wordt. Governance moet zich richten op voorspellingsinput en modelmonitoring, niet op beslissingsoutput. Je kunt een structureel signaalprobleem niet oplossen door alleen maar audits uit te voeren.
Onderzoek van McKinsey bevestigt dat AI-gestuurde voorspellingen fouten met 20-50% verminderen, maar alleen als de onderliggende data-infrastructuur dit ondersteunt. De prestatiekloof tussen organisaties die eerst investeren in signaalkwaliteit en organisaties die AI inzetten op vervuilde data, wordt snel groter.
Het afsluiten begint met vijf vragen.
Wanneer vraagsignalen een actieve rol gaan spelen, eindigt forecasting niet langer bij de supply planning; het wordt de trigger die de S&OP-uitvoering synchroniseert met de resultaten van Revenue Growth Management.
De meeste organisaties stoppen bij de aanbodzijde. Het vraagsignaal vertelt je wat je moet produceren en waar je het moet opslaan – de prijs-, promotie- en margebeslissingen die in datzelfde signaal besloten liggen, worden later, elders, door een ander team genomen.
Die vertraging heeft gevolgen. Een prognose wijst op een piek in de verkoop van een gepromoot drankproduct – bevestigde activering in de detailhandel, seizoensgebonden stijging. De toeleverancier reageert hierop. De handelsinkoop heeft het nog niet door. Tegen de tijd dat de beslissing over de promotie genomen wordt, is de tijdspanne korter geworden. De prognose klopte. De reactie van het bedrijf kwam te laat.
Dit is de kloof tussen de nauwkeurigheid van de voorspelling en de waarde van de voorspelling.
Om dit te bereiken, moeten het vraagsignaal en de commerciële reactie binnen dezelfde S&OP-cyclus plaatsvinden – en niet na elkaar. Beslissingen over aanbod en omzet moeten gezamenlijk worden genomen, op basis van hetzelfde signaal en binnen hetzelfde planningsvenster.
Agentgestuurde uitvoering maakt dat mogelijk. In plaats van prognoses via opeenvolgende prijs-, promotie- en handelsworkflows te leiden, herijken agentgestuurde systemen de promotiediepte, herverdelen ze handelsinvesteringen en handhaven ze margebegrenzingen in realtime. Zo krijgen S&OP een uitvoerbaar omzetplan, in plaats van een getal waarover onderhandeld moet worden.
Dat is waar Profit Pulse , de agentische RGM-suite van Polestar Analytics op 1Platform , in werking treedt: het zet nauwkeurige voorspellingen om in gesynchroniseerde aanbod- en commerciële acties, met gekwantificeerde prijsstijgingen en gecontroleerd neerwaarts risico.
De prognose is niet langer een input voor de planning, maar de aanleiding voor een gecoördineerde RGM-beslissing.
Voorspellen is het brein. Prijsbepaling is het hart. Profit Pulse zorgt ervoor dat beide blijven kloppen.
Laten we RGM met agenten tot leven brengen.
De organisaties die als eerste vooruitgang boeken, doen dat niet door betere technologie in te zetten op een gebrekkige basis. Ze doen het door de signaalkwaliteit te verbeteren, de methodologie af te stemmen op de data en prognoses te integreren in elke fase van S&OP, nog voordat automatisering een rol speelt.
Dat is de volgorde. En dat is precies waar Polestar Analytics actief is: van het opschonen van het vraagsignaal en het bouwen van de S&OP-architectuur die het bruikbaar maakt, tot het implementeren van agentisch RGM via Profit Pulse op 1Platform, zodat de nauwkeurigheid van de prognoses zich direct vertaalt in omzetbeslissingen.
De basis is het voordeel. Al het andere bouwt daarop voort.