
Vat dit blogbericht samen met:
Met elke dag die voorbijgaat, worden organisaties wereldwijd geconfronteerd met uitdagingen op het gebied van datamanagement – veel meer dan ooit tevoren. Sinds het gebruik van data in de jaren 80 begon, is er veel veranderd; met name door de opkomst van cloudcomputing, die enorme veranderingen teweeg heeft gebracht in de manier waarop data wordt gebruikt, verwerkt en begrepen.
Tegenwoordig wordt er elke seconde een enorme hoeveelheid data gegenereerd; het vinden van opslagoplossingen voor deze gigantische hoeveelheden is van het grootste belang. Bij het beheren van data overwegen data managers en professionals het gebruik van datawarehouses of datalakes als opslagplaats.
Wat betekenen deze termen nu precies, wat is het verschil tussen beide en wat is de beste oplossing voor uw organisatie?
In dit artikel duiken we diep in de overeenkomsten en verschillen tussen datawarehouses en datalakes, met als doel antwoorden te vinden op vragen van bedrijven die te maken hebben met beperkingen op het gebied van hun omgeving en budget.
Een data lake is een systeem of opslagplaats voor gegevens die ongestructureerd en in hun natuurlijke/ruwe vorm worden opgeslagen; dat wil zeggen, de gegevens zijn niet verwerkt of geanalyseerd. Een data lake stelt organisaties in staat om grote hoeveelheden diverse datasets op te slaan zonder eerst een model te hoeven bouwen.
Het is doorgaans een centrale opslagplaats voor alle bedrijfsgegevens, inclusief onbewerkte kopieën van gegevens uit bronsystemen en bewerkte gegevens die worden gebruikt voor taken zoals rapportage, visualisatie, geavanceerde analyses en machine learning.
Stel je een data lake voor als een grote watermassa, bijvoorbeeld een meer in zijn natuurlijke staat. De data lake wordt gecreëerd door data die vanuit verschillende bronnen binnenstromen, waarna diverse gebruikers de data kunnen onderzoeken en er monsters van kunnen nemen.
Een data lake kan gestructureerde data uit relationele databases (rijen en kolommen), semi-gestructureerde data (CSV, logbestanden, XML, JSON), ongestructureerde data (e-mails, documenten, PDF's) en binaire data (afbeeldingen, audio, video) bevatten. Het is met name nuttig wanneer data managers op zoek zijn naar manieren om data uit diverse bronnen in verschillende formaten vast te leggen en op te slaan. In veel gevallen worden data lakes als kosteneffectief beschouwd en gebruikt om data op te slaan voor verkennende analyses.
Een datawarehouse , daarentegen, brengt al uw gegevens samen en slaat ze op een georganiseerde/gestructureerde manier op. Het helpt om gegevens op één plek te consolideren met als doel waardevolle zakelijke inzichten te verkrijgen die vervolgens kunnen worden gebruikt om betere zakelijke beslissingen te nemen – het helpt u in wezen om waarde uit de data te halen.
Zodra het doel van de data is vastgesteld, wordt deze in een datawarehouse geladen. Dit stelt organisaties vervolgens in staat om inzichten te verkrijgen via analytische dashboards, operationele rapporten en/of geavanceerde analyses.
Datawarehousing verbetert simpelweg de kwaliteit van business intelligence , waardoor managers geen zakelijke beslissingen meer hoeven te nemen op basis van beperkte data of op hun onderbuikgevoel.
Doordat alle soorten gegevens op één plek worden opgeslagen, stellen datawarehouses organisaties in staat om snel weloverwogen beslissingen te nemen over belangrijke initiatieven.
De laatste tijd is er een toename in gesprekken over zowel datawarehouses als datalakes, waarbij mensen proberen de voordelen van beide te begrijpen, en zelfs hoe ze samen op het enterprise-niveau ingezet kunnen worden. Het gaat er niet om de een tegen de ander uit te spelen, maar eerder om te begrijpen hoe ze hand in hand kunnen werken.
AANBEVOLEN LEES: DATA LAKES VS. DATA WAREHOUSE! WAT ZIJN DE VERSCHILLEN?
Gegevensbronnen: Gegevensbronnen zijn de plaatsen waar originele gegevens, afkomstig van diverse interne en externe bronnen, zich bevinden. Dit kunnen operationele gegevensbronnen zijn, zoals ERP- en CRM-systemen, maar ook gegevens van sociale media, zoals websitebezoeken, populariteit van content, enzovoort. Daarnaast kunnen het ook gegevens van derden zijn, zoals demografische gegevens, enquêtes, volkstellingen, enzovoort, of zelfs ongestructureerde gegevens zoals afbeeldingen en video's.
Ruwe/Landingslaag: Gegevens worden uit verschillende bronsystemen geëxtraheerd en in ruwe vorm opgeslagen in de landingslaag van het data lake. De landingslaag tagt de gegevens aan de hand van het bronsysteem.
Gestandaardiseerde laag: Omdat gegevens in verschillende formaten worden aangeleverd (relationeel, JSON, binair, enz.), moeten ze worden gestandaardiseerd naar een rij- en/of kolomindeling. Deze laag transformeert de gegevens ook en past bedrijfslogica toe.
Samengestelde laag: Deze laag wordt gecreëerd op basis van de bedrijfsbehoeften en kan data marts bevatten voor rapportage en analyses. Afhankelijk van wie toegang heeft tot de samengestelde laag, kan deze ook gedenormaliseerde data bevatten voor datawetenschappers.
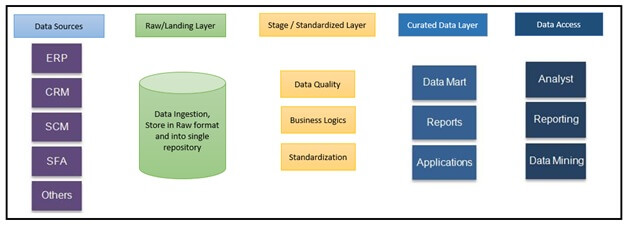
Anders dan datawarehouses, volgt een data lake de ELT-aanpak (Extract, Load, Transform). Zo werkt het:
Gegevensextractie en -laden: De extractie van de brongegevens omvat routines die de gegevens lezen en in een geschikt formaat naar een opslaglocatie verplaatsen. Het gegevensextractieproces is onderverdeeld in:
- Gegevens uit de systemen lezen – Verbinding maken met verschillende systemen via connectors of API-aanroepen om toegang te krijgen tot de gegevens;
- Label de binnenkomende brongegevens – Inkomende gegevens van verschillende bronsystemen worden gelabeld zodat ze in de toekomst kunnen worden geraadpleegd.
Datatransformatie: Dit omvat dataopschoning, datastandaardisatie, bedrijfslogica, enzovoort.
De kwaliteit (volledigheid, validiteit en nauwkeurigheid) van de gegevens moet worden gekwantificeerd en toegelicht, zodat de besluitvormers de betrouwbaarheid van de gegevens kunnen beoordelen en pas daarna kunnen bepalen welke maatregelen nodig zijn.
De gegevens, afkomstig uit verschillende bronnen, kunnen in verschillende formaten voorkomen. Deze worden gestandaardiseerd tot een tabelvorm met rijen en kolommen, bijvoorbeeld door JSON-gegevens naar tabellen om te zetten. Bedrijfslogica wordt toegepast volgens de vereisten. De gegevens worden opgeslagen in een beheerde laag van waaruit ze, indien nodig, voor iedereen toegankelijk zijn.
Stel je data-architectuur voor als een shepherd's pie of een lasagne – met lagen. Elke laag speelt een rol, in dit geval bij het omzetten van ruwe data in waardevolle data die klaar is voor gebruik – analyse en business intelligence. Om de ruwe data waardevol te maken, moet deze een proces van gelaagdheid, sorteren, structureren en opschonen doorlopen. Pas dan komen de meest relevante gegevens bovenaan te staan. Een datawarehouse maakt dit in feite mogelijk.
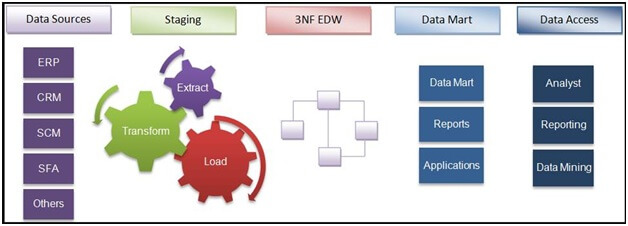
Gegevensbronnen: Gegevensbronnen zijn de plaatsen waar originele gegevens, afkomstig van diverse interne en externe bronnen, zich bevinden. Dit kunnen operationele gegevensbronnen zijn, zoals ERP- en CRM-systemen, maar ook gegevens van sociale media, zoals websitebezoeken, populariteit van content, enzovoort. Daarnaast kunnen het gegevens van derden zijn, zoals demografische gegevens, enquêtes, volkstellingen, enzovoort, of zelfs ongestructureerde gegevens zoals afbeeldingen en video's.
Staginglaag: Gegevens moeten uit verschillende bronsystemen worden geëxtraheerd en vervolgens op de staginglaag terechtkomen. In een EDW is de staginglaag de Truncate Load Staging Layer, waar incrementele gegevens uit het bronsysteem moeten worden geëxtraheerd.
Transformatie: Gegevens moeten worden getransformeerd volgens het datamodel en de bedrijfslogica. Het is belangrijk om te weten dat transformatielagen kunnen variëren per systeem en per vereiste.
Laden: De getransformeerde gegevens moeten vervolgens volgens de beste werkwijzen en vereisten in het EDW worden geladen.
Data marts: Data marts worden bovenop het EDW gecreëerd om te voldoen aan de rapportagevereisten en om de best mogelijke prestaties te leveren tijdens het rapporteren.
De beste werkwijzen of beslissingen die genomen moeten worden voor datawarehouses:
- Beschik over een datamodel.
- Stel een gegevensstroomdiagram samen.
- Bepaal welke eigenschappen of kenmerken in de tijd variëren.
- Hanteer een erkende standaard voor datawarehouse-architectuur, zoals 3NF, stermodellering, enz., afhankelijk van de vereisten.
- Overweeg om een agile datawarehouse-methodologie te gebruiken.
Datawarehouses volgen de ETL-aanpak, oftewel Extract Transform Load. Zo werkt het:
1) Gegevensextractie: De extractie van de brongegevens omvat routines die de gegevens lezen, deze omzetten naar een tussentijds schema en verplaatsen naar een tijdelijke werkruimte waar gegevens in tussentijdse schema's worden bewaard. Het gegevensextractieproces is onderverdeeld in:
- Gegevens uit de systemen lezen – verbinding maken met verschillende systemen via connectors of API-aanroepen om toegang te krijgen tot de gegevens.
- Het vaststellen van wijzigingen om nieuwe gegevens te identificeren, oftewel het identificeren van gegevens die in het datawarehouse moeten worden geladen, vermindert de hoeveelheid gegevens die ernaartoe wordt gemigreerd aanzienlijk. Aangepaste data-acquisitietechnieken kunnen in twee algemene categorieën worden onderverdeeld: statisch en incrementeel. Statische data-acquisitie houdt meestal in dat er een momentopname van de gegevens op een bepaald tijdstip wordt gemaakt. In sommige gevallen kan de volledige dataset worden hersteld, maar waarschijnlijk zal slechts een subset worden gebruikt. Incrementele data-acquisitie daarentegen is een tijdsafhankelijk model voor het vastleggen van wijzigingen in besturingssystemen. Deze techniek is het meest geschikt in situaties waarin de gegevenswijziging aanzienlijk kleiner is dan de omvang van de dataset gedurende een bepaalde periode. Er kunnen drie verschillende technieken worden toegepast: capture, trigger-gebaseerde capture en transaction log capture.
- De generaliserende sleutel is een belangrijke beheertoepassing die moet worden geïmplementeerd. Operationele invoerschakelaars moeten doorgaans worden geherstructureerd voordat ze worden vastgelegd. Zelden blijft een invoersleutel ongewijzigd bij het lezen in de operationele omgeving en het schrijven naar de datawarehouse-omgeving. In eenvoudige gevallen wordt een tijdselement aan de sleutelstructuur toegevoegd. In complexe gevallen moet de volledige invoersleutel een nieuw hashproces doorlopen of worden geherstructureerd.
- Het combineren van gegevens uit meerdere bronnen: In de meeste datawarehouses zijn de gegevens afkomstig van verschillende, onafhankelijke bronsystemen. In dergelijke gevallen is het noodzakelijk om een tussenliggende dataopslagomgeving in te richten.
2) Datatransformatie: Dit is een van de belangrijkste processen in ETL. Datatransformatie omvat ook dataopschoning. De kwaliteit (volledigheid, validiteit en nauwkeurigheid) van de data in het datawarehouse moet worden gekwantificeerd en geanalyseerd, zodat besluitvormers de betrouwbaarheid van de data kunnen beoordelen en pas daarna kunnen bepalen welke maatregelen nodig zijn.
De meest voorkomende soorten bodemgegevens zijn:
- Dummywaarden
- Gebrek aan gegevens
- Multifunctionele velden
- Inconsistente gegevens
- Hergebruik van primaire sleutels
- Niet-unieke identificatoren
De overige gegevenstransformaties omvatten:
- Hernoem op basis van logische namen in plaats van technische namen.
- Het samenvoegen van twee datasets
- Denormalisatie van dimensies
3) Gegevens laden: Na de gegevenstransformatie volgt het laadproces, waarbij de gegevens op de datawarehouse-server worden geplaatst. Zodra de gegevens zich in het EDW bevinden, worden specifieke data marts aangemaakt op basis van de rapportage- of bedrijfsvereisten.
Data lakes en data warehouses zijn twee kanten van dezelfde medaille: het zijn verschillende tools die voor verschillende doeleinden worden gebruikt, afhankelijk van wat een organisatie wil bereiken. Data lakes bewaren alle data, terwijl data warehouses gezuiverde, verwerkte en gestructureerde data bewaren.
Data lakes zijn kosteneffectief en relatief eenvoudig aan te passen, terwijl het lastiger is om de structuur van een datawarehouse te wijzigen, simpelweg vanwege het aantal lagen en processen dat eraan verbonden is.
Naarmate bedrijfsdata diverser worden, hebben organisaties uiteindelijk de mogelijkheid om te kiezen wat het beste bij hen past. Ze kunnen de functionele aspecten van zowel datawarehouses als datalakes begrijpen en werken aan een model dat de voordelen van beide combineert.
Het hoge tempo waarin bedrijven een datagedreven strategie hanteren om hun digitale transformatie te leiden, wordt gedreven door data-analyse. Competente datamethoden worden ingezet om de ontbrekende schakels aan te vullen voor organisaties die te maken hebben met beperkingen, vooroordelen en mislukkingen.
Bij de implementatie van datawarehouses en datalakes hebben beide de mogelijkheid om operationele, historische en zelfs realtime data te transformeren, wat leidt tot een hogere efficiëntie, betere bedrijfsprestaties en uiteindelijk een betere klantervaring.
Hoewel veel organisaties nog steeds worstelen met het experimenteren met datawarehouses en datalakes, is het een standaardvereiste geworden voor organisaties om zich aan te passen aan de steeds veranderende wereld van data-analyse.
Over het algemeen heerst er veel optimisme over analytics in de nabije toekomst. We zullen zien dat organisaties van alle groottes en omvang analytics integreren in hun dagelijkse bedrijfsvoering.
Uiteindelijk hopen we bij Polestar de kracht van data beschikbaar te maken voor organisaties in alle sectoren. We helpen hen miljarden datapunten en datasets te analyseren om realtime inzichten te verkrijgen en hen in staat te stellen cruciale beslissingen te nemen om hun bedrijf te laten groeien.
Blijf op de hoogte van je favoriete onderwerpen.