
Vat dit blogbericht samen met:
Noot van de redactie: Begrijp hoe Data Mesh-architecturen de obstakels voor het centrale datateam kunnen wegnemen en een gedecentraliseerde aanpak mogelijk maken waarmee teams zelf domeinoverschrijdende data-analyse kunnen uitvoeren.
Volgens Gartner levert slechts 20% van de data-analyseprojecten daadwerkelijk zakelijke resultaten op. Gezien het feit dat de huidige data-architecturen beter toegerust moeten zijn om de alomtegenwoordigheid en de steeds complexere onderlinge verbondenheid van data aan te kunnen, is dit niet verwonderlijk. De vraag die in elke directiekamer speelt, is dan ook: hoe kunnen bedrijven een data-architectuur op de juiste manier bouwen om de data-efficiëntie te verhogen, rekening houdend met de groeiende complexiteit van data en de vele toepassingsmogelijkheden?
Het data mesh-concept, voor het eerst gedefinieerd in 2018 door Zhamak Dehghani , is de nieuwste benadering van data-architectuur voor bedrijven en is gericht op het aanpakken van de valkuilen van traditionele dataplatformen. Bedrijven die op zoek zijn naar een data-architectuur die aansluit op hun steeds veranderende datagebruiksscenario's, zouden de data mesh-architectuur moeten overwegen om hun bedrijfsprocessen en analyses te ondersteunen.
Data Mesh is een relatief nieuwe aanpak voor het beheren van data in grote, complexe organisaties. Simpel gezegd houdt het in dat datasilo's worden afgebroken en data op een meer gedecentraliseerde en collaboratieve manier wordt georganiseerd.
Het idee achter Data Mesh is dat data als een product moet worden behandeld, waarbij eigenaarschap en verantwoordelijkheid binnen de organisatie worden verdeeld. In plaats van dat één centraal team alle data voor de organisatie beheert, is elk team of elke afdeling verantwoordelijk voor de data die zij creëren en gebruiken.
Stel, u werkt voor een groot e-commercebedrijf. In de traditionele aanpak is er wellicht een centraal datateam verantwoordelijk voor het beheer van alle klantgegevens, productgegevens en transactiegegevens voor de hele organisatie. Maar met een Data Mesh-aanpak is elke afdeling verantwoordelijk voor het beheer van de gegevens die betrekking hebben op hun specifieke werkgebied.
Het klantenserviceteam zou verantwoordelijk zijn voor het beheren van klantgegevens, het productteam voor het beheren van productgegevens en het financiële team voor het beheren van transactiegegevens. Elk van deze teams zou zijn eigen dataproducten creëren, zoals een klantendatabase of een productcatalogus, en deze producten beschikbaar stellen aan andere teams binnen de organisatie.
Door datasilo's af te breken en eigenaarschap en verantwoordelijkheid te verdelen, is het de bedoeling dat data gemakkelijker beheerd en gedeeld kan worden binnen de organisatie. Dit kan leiden tot betere samenwerking, snellere besluitvorming en meer innovatie.
Wil je op grote schaal waarde uit data halen?
Wij helpen u bij het implementeren van bedrijfsbrede oplossingen voor uw cruciale data, zodat u het ware potentieel van uw bedrijfsdata kunt ontsluiten.
Hieronder vindt u een tabel waarin de kenmerken van traditionele datamanagementplatformen worden vergeleken met data mesh-architecturen.
| Traditionele datamanagementplatformen | Data Mesh-architectuur |
|---|
| Ondersteun een centraal datateam dat diverse domeinen beheert. | Ondersteun autonome domeinteams |
| Beheer code, beleid en gegevens als één geheel. | Beheer code en pipelines zelfstandig. |
|---|
| Vereist aparte stacks voor operationele en analytische workloads. | Biedt één platform voor operationele en analytische werkzaamheden. |
|---|
| Centraliseer het platform voor optimale controle. | Decentraliseer het platform voor optimale schaalbaarheid. |
|---|
| Bewustzijn van het strijdkrachtendomein | Blijf domein-onafhankelijk. |
|---|
In plaats van data als een gecentraliseerde opslagplaats te beschouwen, maakt het gedecentraliseerde karakter van een data mesh het mogelijk dat data-eigenaarschap in handen komt van domeinspecifieke teams. Deze teams beheren, controleren en leveren de data als een product, waardoor data gemakkelijk toegankelijk en onderling verbonden is binnen de hele organisatie.
Tegenwoordig kunnen veel datagebruiksscenario's binnen organisaties worden onderverdeeld in analytische en operationele data. Operationele data vertegenwoordigt gegevens uit de dagelijkse werkzaamheden van de applicaties van de organisatie. Bijvoorbeeld, bij een webwinkel gaat het om klant-, transactie- en voorraadgegevens. Dit type operationele data wordt over het algemeen opgeslagen in databases en gebruikt door ontwikkelaars om diverse API's en microservices te creëren die de bedrijfsapplicaties aandrijven.
Operationeel versus analytisch datavlak
Aan de andere kant vertegenwoordigt analytische data historische bedrijfsgegevens die worden gebruikt om zakelijke beslissingen te verbeteren. In webwinkels bijvoorbeeld, beantwoordt analytische data vragen zoals "hoeveel consumenten hebben dit product de afgelopen jaren besteld?" of "welke producten zullen klanten waarschijnlijk in het winterseizoen kopen?". Analytische data wordt doorgaans vanuit meerdere operationele databases met behulp van ETL-technieken naar gecentraliseerde dataopslagplaatsen zoals datawarehouses en datalakes getransporteerd. Data-analisten en -wetenschappers gebruiken deze data voor hun analytische werkzaamheden, en marketing- en productteams kunnen op basis van de data impactvolle beslissingen nemen.

Een data mesh-aanpak begrijpt het fundamentele verschil tussen de twee hoofdtypen data en probeert deze twee typen data te verbinden binnen een andere structuur: een gedecentraliseerde aanpak voor databeheer.
Bekijk eens het aanbod van Microsoft: Azure Synapse Analytics, in combinatie met Data Lake Storage Gen2 en SQL-databases, als centrale componenten voor het implementeren van een data mesh-architectuur.
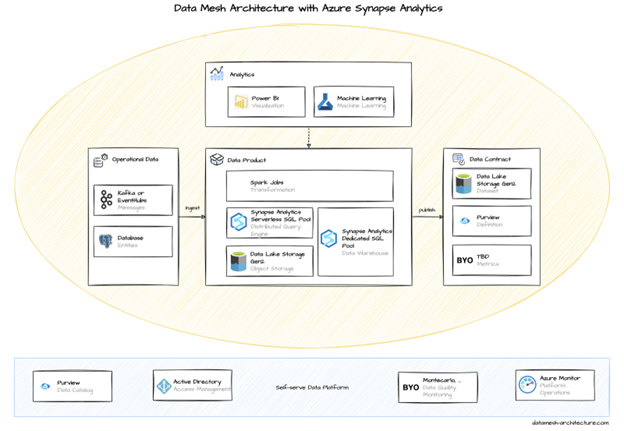
Een data mesh-framework is gebaseerd op vier principes die de manier veranderen waarop data-analyse binnen de onderneming mogelijk wordt gemaakt :

Domeingestuurde eigendom en architectuur
Het belangrijkste principe van een data mesh is het overdragen van de zeggenschap over eigendom en data naar de domeinteams. Zij zijn van begin tot eind verantwoordelijk voor de data – van het zorgen voor de juiste bronnen of ingevoerde data, tot het onderhouden en bouwen van de benodigde verwerkingspipelines, en het beschikbaar stellen van de data aan andere domeinteams als producten (daarover later meer), met de nodige kwaliteitsgaranties en beheersmaatregelen. De domeinteams kunnen worden gedefinieerd door afdelingen, businessunits of andere soortgelijke groeperingen. Bij een correcte implementatie kunnen nieuwe domeinteams soepel en op een significante manier worden toegevoegd wanneer data wordt gecorreleerd tot nieuwe dataproducten.
Gegevens als product
Zoals al in het eerste principe werd aangegeven, zijn domeinteams niet alleen verantwoordelijk voor de data en de daaruit voortvloeiende dataproducten. En dataproducten moeten net als elk ander product worden behandeld. Consumenten en andere domeinteams moeten dataproducten kunnen vinden en gebruiken. De domeineigenaar is verantwoordelijk voor het onderhouden en bijwerken (of uitfaseren) van deze producten om de nauwkeurigheid en kwaliteit te waarborgen. Hoe ziet dit er in de praktijk uit? Stel je een supply chain-team voor dat een inventarisdataproduct beheert dat marketingmedewerkers kunnen gebruiken om nieuwe kortingscampagnes te ontwikkelen of dat regionale teams kunnen gebruiken om nieuwe bestellingen te plaatsen.
Zelfbedieningsinfrastructuur
Het derde principe is om al deze zelfservice eenvoudig te maken voor de domeinteams. Complexe technologieën en specialistische vaardigheden zijn niet houdbaar in een data mesh-ontwerp. Er is behoefte aan een gemeenschappelijk platform en een set tools die elk domeinteam kan gebruiken om hun dataproducten te ontwikkelen en te beheren, zonder vast te lopen op beperkingen qua infrastructuur of onderhoud.
federatief bestuur
Het laatste essentiële onderdeel van een succesvol datamesh is governance. Een datamesh-architectuur mag niet ten koste gaan van toegangscontrole en gegevensbescherming. Er moet een evenwicht zijn tussen wereldwijde governancebeleidsregels en -controles, en ervoor zorgen dat elk domeinteam deze beleidsregels kan definiëren en implementeren bij het ontwikkelen en delen van hun dataproducten. Deze gefedereerde governance is cruciaal voor het waarborgen van gegevensprivacy en compliance, en voor het faciliteren van data-ontdekking op grote schaal.
Gecombineerd maken deze principes een gedecentraliseerd, maar robuust en uitgebreid dataframework mogelijk, ontworpen om zakelijke resultaten te leveren. De resulterende analytische data-architectuur en het operationele model behandelen data als een product dat beheerd kan worden door de teams met de meest diepgaande kennis van hun gebruiks- en analysebehoeften.
Bekijk hieronder enkele belangrijke voordelen van Data Mesh.

Het implementeren van een data mesh kan de toegang tot en controle over data binnen uw organisatie aanzienlijk verbeteren. Het is echter cruciaal om de beste implementatiepraktijken te overwegen om ervoor te zorgen dat u het maximale uit deze technologie haalt.
- Begin met de bedrijfsfunctionaliteiten: identificeer eerst de bedrijfsfunctionaliteiten en hun datavereisten, en ontwerp de data mesh-architectuur daar omheen.
- Decentraliseer het eigenaarschap: Wijs het eigenaarschap van de gegevens toe aan individuele teams, die verantwoordelijk zijn voor de kwaliteit, beveiliging en het beheer van de gegevens.
- Gebruik domeingestuurd ontwerp: Pas de principes van domeingestuurd ontwerp toe om domeinspecifieke dataproducten te creëren die door andere teams kunnen worden gebruikt.
- Gebruik API's voor dataproducten: Ontwikkel API's voor dataproducten om ze gemakkelijk vindbaar en bruikbaar te maken.
- Benadruk de datakwaliteit: Zorg ervoor dat de data van hoge kwaliteit is door kwaliteitscontroles uit te voeren, datapipelines te bewaken en feedback te geven aan dataproducenten.
- Gebruik een datacatalogus: Implementeer een gecentraliseerde datacatalogus om één betrouwbare bron voor data-ontdekking te creëren. Implementeer databeveiliging: Implementeer databeveiligingsmaatregelen om ervoor te zorgen dat gevoelige gegevens worden beschermd tegen ongeautoriseerde toegang.
- Implementeer databeheer: Implementeer praktijken voor databeheer om naleving van wet- en regelgeving en normen te waarborgen.
- Omarm cloud-native technologieën: gebruik cloud-native technologieën om schaalbaarheid, betrouwbaarheid en flexibiliteit mogelijk te maken.
- Bevorder een datagedreven cultuur: Stimuleer een datagedreven cultuur waarin data wordt gebruikt om besluitvorming te sturen en waarin data als een waardevolle troef wordt beschouwd.
Door deze best practices voor de implementatie van een data mesh te volgen, kunt u ervoor zorgen dat uw bedrijf over de juiste infrastructuur, doelen en behoeften beschikt om een effectieve data mesh-oplossing te bouwen.
Hoe kunnen wij u helpen transformeren en groeien?
Onze aanpak kan u helpen bij het verzamelen, verrijken, transformeren en beschikbaar stellen van data via een gecentraliseerd platform.
Hoewel gedistribueerde data mesh-architecturen nog steeds aan populariteit winnen, helpen ze teams hun schaalbaarheidsdoelen te bereiken voor veelvoorkomende big data-toepassingen. Deze omvatten:
Business intelligence-dashboards: Naarmate er nieuwe initiatieven ontstaan, hebben teams vaak behoefte aan aangepaste dataweergaven om de prestaties van deze projecten te begrijpen. Data mesh-architecturen kunnen in deze behoefte aan flexibiliteit en maatwerk voorzien door data toegankelijker te maken voor dataverbruikers.
Klantbeleving: Klantgegevens stellen bedrijven in staat hun gebruikers beter te begrijpen, waardoor ze meer gepersonaliseerde ervaringen kunnen bieden. Dit is in diverse sectoren waargenomen, van marketing tot de gezondheidszorg.
Machine learning-projecten: Door domeinonafhankelijke data te standaardiseren, kunnen datawetenschappers gemakkelijker data uit diverse bronnen samenvoegen, waardoor de tijd die aan dataverwerking wordt besteed, wordt verkort. Deze tijdsbesparing kan ertoe leiden dat sneller een aantal modellen in productie worden genomen, wat de realisatie van automatiseringsdoelen mogelijk maakt.
Naarmate bedrijven meer data verzamelen, opslaan en analyseren, wordt gedecentraliseerd data-eigendom steeds belangrijker. Uiteindelijk is het teruggeven van data aan degenen die er verstand van hebben de beste weg. Het ontwikkelen van een gedistribueerde selfservice-architectuur met gecentraliseerd beheer vereist voortdurende toewijding.
De overgang van een monolithisch naar een gedistribueerd model vereist een reorganisatie van de organisatie en een cultuurverandering. Deze inspanning is echter de moeite waard, omdat dit transformatieve paradigma de potentie heeft om de datacentrische visie van een onderneming te versterken.
Polestar Analytics is een toonaangevend IT-adviesbureau dat talloze organisaties heeft geholpen hun dataprocessen te transformeren. De hoeveelheid gegenereerde data neemt exponentieel toe en de toegang tot monolithische datasets wordt met de tijd steeds lastiger. Boek vandaag nog een consult!