
Vat dit blogbericht samen met:
Low-code/no-code platforms pakken knelpunten in data-engineering aan door integraties te vereenvoudigen, transformaties te automatiseren en governance in te bedden in één uniforme data-architectuur.
- Waarom zijn low-code/no-code (LCNC) platforms geëvolueerd van workflowbouwers naar bedrijfskritische data-infrastructuur?
- De vier verborgen kosten die data-engineers betalen wanneer ze vertrouwen op losgekoppelde dataplatformen in plaats van uniforme LCNC-data-engineeringoplossingen .
- Hoe elimineer je het transformatieknelpunt met visuele ETL-pipelines, mogelijk gemaakt door low-code/no-code data engineering-oplossingen?
- De architectonische beslissing die bepaalt of AI-agenten uw data-infrastructuur versnellen of omzeilen.
Als je nog steeds "nadenkt over experimenteren" met Low Code No Code (LCNC)-platformen omdat je het ziet als een "opkomende trend", dan heb je het helemaal mis.
Nog maar een paar jaar geleden gebruikte minder dan 25% van de nieuwe bedrijfsapplicaties low-code . Vandaag de dag is dat aantal gestegen naar 80% . Wat is er veranderd? Low-code platforms zijn niet langer alleen workflowbouwers. We zijn overgestapt van het coderen van pipelines naar het orkestreren van intelligente systemen (dankzij AI met een agent ) die zichzelf besturen.
Data-engineeringknelpunten zijn niet nieuw. Elke nieuwe SaaS-integratie betekende wekenlange ontwikkeling van aangepaste connectoren. Of schemawijzigingen die zonder waarschuwing pipelines verstoorden. Businessteams wachtten maanden op simpele datatransformaties omdat alles handmatig gecodeerd moest worden.
Daarom begonnen LCNC-platforms aanvankelijk als tools om burgerontwikkelaars in staat te stellen afdelingsspecifieke applicaties te ontwikkelen. In de loop der tijd zijn enkele platforms uitgegroeid tot bedrijfsbrede infrastructuren die complexe automatisering, datademocratisering en nu zelfs AI-gestuurde orkestratie aankunnen.
Dit is wat er veranderd is voor data-engineers: in plaats van voor elke API een eigen connector te bouwen, configureer je kant-en-klare connectors. In plaats van complexe SQL-query's te schrijven voor standaardtransformaties, gebruik je visuele interfaces. In plaats van handmatige monitoring van schema-afwijkingen, doen de platforms dit automatisch. Je kunt je concentreren op complexe bedrijfslogica in plaats van op repetitief integratiewerk.
Vandaag zien we de resultaten van deze evolutie. Met low-code ontwikkelplatformen levert 61% van de gebruikers succesvol maatwerkapplicaties op, binnen de gestelde termijn, de scope en het budget. En low-code laat zien dat het de softwareontwikkeling tot wel tien keer kan versnellen.
Maar dit is wat de meeste organisaties over het hoofd zien: weten waar de branche naartoe gaat, heeft geen zin als je niet weet waar je nu staat.
Volwassenheidsmodel voor low-code/no-code: Waar staat uw organisatie?
De meeste bedrijven vallen in één van de drie volwassenheidsniveaus:
De belangen zijn groot, omdat elk niveau fundamenteel verschillende strategieën, bestuursmodellen en risicoprofielen vereist.
Weet je waar je staat? Dan is het tijd om te bepalen waar je naartoe wilt.
Ga aan de slag met een data-engineeringplatform met weinig code.
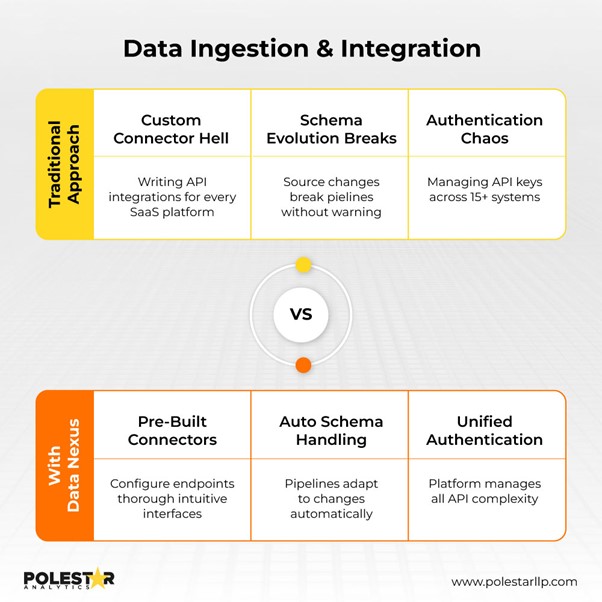
Begin met Data Nexus Iedere data engineer kent deze realiteit: wat vroeger een simpele ETL-taak was vanuit drie systemen, omvat nu het beheren van meer dan 15 API's, elk met verschillende limieten voor het aantal aanvragen, authenticatieschema's en ingrijpende wijzigingen.
Dit is wat je betaalt voor deze complexiteit:
De werkelijke kosten zitten niet in het SaaS-abonnement, maar in de ontwikkeltijd. Elke nieuwe tool vereist de ontwikkeling van aangepaste connectors, het beheer van OAuth-flows en constante monitoring van schema-afwijkingen. De overhead voor het onderhoud van uw pipeline neemt exponentieel toe, terwijl uw team gelijk blijft.
Technische realiteitscheck:
- API-snelheidslimieten: De meeste SaaS-platformen beperken het aantal verzoeken tot 100-1000 per minuut.
- De frequentie van schemaverschuivingen: API's wijzigen binnen enkele maanden, waardoor schema's niet meer werken.
- Authenticatiekosten: Het beheer van OAuth-tokens kost extra ontwikkeltijd (afhankelijk van de complexiteit van het project).
- Complexiteit van foutafhandeling: Aangepaste connectoren vereisen meer dan 200 regels code alleen al voor de logica van het opnieuw proberen.
De kosten van technische schuld lopen sneller op dan je ze kunt aflossen.
Data Nexus elimineert deze integratiekosten. Via Nexus kunt u verbinding maken met elk systeem (clouddatabases, ERP's, platte bestanden, API's, datawarehouses) zonder maatwerkontwikkeling. Het platform biedt vooraf gebouwde connectiviteit die authenticatie, snelheidsbeperking en schema-evolutie automatisch afhandelt.
Het tijdsverschil is aanzienlijk. Qua code- en frameworkontwikkeling versnelt het het proces met 70% . Dit betekent dat bij de taakselectie eenvoudige configuraties de complexe integratieontwikkeling vervangen. En je kunt je concentreren op de logica voor datatransformatie in plaats van op de overhead van de verbindingen.
Waar transformatie plaatsvindt, ontstaat onvermijdelijk een knelpunt. Bij datatransformatie kan dat een simpele zakelijke vraag zijn, zoals: "Hoeveel betalen we onze medewerkers in verschillende steden?" Drie maanden later worstel je nog steeds met niet-overeenkomende schema's en dubbele records.
Wat een eenvoudige query lijkt, wordt al snel een project voor de integratie van meerdere systemen – met schema-afstemming, het verwijderen van dubbele gegevens en kwaliteitscontrole. Elk van deze taken vereist specialistische vaardigheden en aanzienlijke ontwikkeltijd.
Dit is waar traditionele data-engineering vastloopt:
- Eindeloos veel SQL- en PySpark-code schrijven om uitzonderlijke gevallen af te handelen en dubbele records te verwijderen.
- Het creëren van complexe mappingtabellen om uiteenlopende gegevens te verzoenen.
- Opnieuw beginnen wanneer de bedrijfsbehoeften onvermijdelijk veranderen.
LCNC-platforms lossen dit anders op. Transformaties met slepen en neerzetten verzorgen standaardbewerkingen zoals samenvoegingen, deduplicatie en aggregatie als configuratieopties. U past bedrijfslogica toe via eenvoudige kolomvoorwaarden zonder code te schrijven, waardoor u uw tijd kunt besteden aan complexe bedrijfslogica in plaats van aan repetitieve gegevensbewerking .
PS: Kost bijna 50-70% van de tijd in vergelijking met handmatig.

Je hebt het transformatieknelpunt opgelost en kunt nu de vraag beantwoorden: "Hoeveel betalen we onze medewerkers in de verschillende steden?" Maar hier is het dieperliggende probleem: welke versie van "John Smith" is de echte?
De behoefte aan data die geschikt is voor analyses of AI is groter dan ooit. Met 1Platform's Data Nexus integreren we deze ideologie van analyseklare data in een op een medaillonarchitectuur gebaseerd proces:
- De gegevens behouden hun oorspronkelijke formaten in de bronzen laag van elk systeem.
- Uniforme entiteitstoewijzingen in de zilveren laag door middel van geautomatiseerde matchingalgoritmen die geen handmatig gegevensbeheer vereisen.
- De gouden laag biedt consistente weergaven voor analyses, terwijl de operationele datamodellen die afdelingen daadwerkelijk gebruiken, behouden blijven.
Deze aanpak helpt de organisatie een uniform beeld van alle gegevens te geven en tegelijkertijd haar technische mogelijkheden te verbeteren.
Low Code of No Code Data Engineering is wellicht dé oplossing voor uw data!
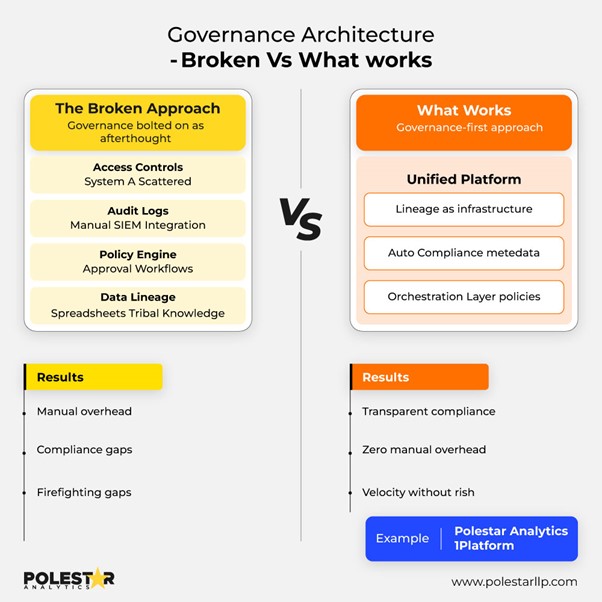
Databeheer verandert data-engineers in brandweermannen. Wanneer auditors om de herkomst van gegevens vragen, moet je je door spreadsheets heen worstelen en op zoek gaan naar degene die die datapipeline heeft gebouwd. GDPR-verzoeken betekenen dat je handmatig tientallen systemen moet doorzoeken. Business-teams bouwen verborgen workflows, waarna IT de schuld krijgt als compliance ze ontdekt.
Traditionele tools verspreiden het beheer over verschillende systemen. Toegangscontroles op vijf verschillende plaatsen. Auditlogboeken die handmatig moeten worden gecorreleerd.
LCNC-platforms zoals 1Platform centraliseren dit met:
- Een overzicht dat de volledige gegevensstroom van bron tot eindrapporten weergeeft.
- Toegangsbeheer dat van toepassing is op alle gegevensstromen vanuit één interface.
- Wijzigingen in de pijplijn die elke keer worden goedgekeurd
- Monitoringdashboards waarop u de status van datapijplijnen kunt volgen.
Wanneer auditors vragen stellen, raadpleegt u de metadata van het platform in plaats van als detective in verschillende systemen te gaan zoeken.
Wij hebben de oplossing gevonden voor uw data-engineeringbehoeften.
Intelligente platforms maken governance onderdeel van uw engineering-DNA met ingebouwde traceerbaarheid, geautomatiseerde compliance en schaalbare toegangscontroles.
Ontdek LCNC voor data-engineering Aangezien 93 procent van de IT-leiders aangeeft binnen de komende twee jaar autonome AI-agenten te willen introduceren, en bijna de helft dit al heeft gedaan, is uw architectuurkeuze belangrijker dan ooit.
Er zijn niet alleen data-agents die schemawijzigingen detecteren, pipelines automatisch aanpassen en dataconflicten oplossen zonder menselijke tussenkomst.
Maar je hebt ook schone data nodig om de branchespecifieke agents zo efficiënt mogelijk te laten werken.
Uw data-applicaties, AI-agenten en analyses moeten dus vanuit één basis werken. Niet alleen API-verbindingen tussen tools, maar daadwerkelijke architecturale eenheid waarbij data van invoer naar AI-verwerking naar geautomatiseerde acties stroomt zonder systeemgrenzen te overschrijden.
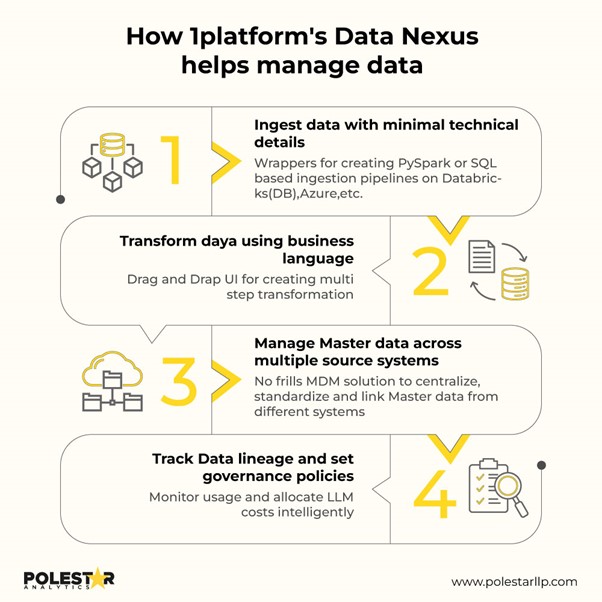 Hoe 1Platform's Data Nexus helpt bij het beheren van data
Hoe 1Platform's Data Nexus helpt bij het beheren van data Organisaties die Data Nexus en 1Platform vandaag gebruiken, bouwen de infrastructuur voor de autonome bedrijfsvoering van morgen.
Het verschil zit hem niet in de complexiteit, maar in de vraag of je architectuur voor je werkt of juist tegen je. Het gaat erom of je op één platform bouwt of er tien beheert.
De beslissing is aan jou.
Leiders moeten de besluitvormingsvertraging, de complexiteit van de integratie en de beschikbare capaciteit van de engineers evalueren. Als teams meer tijd besteden aan het onderhouden van pipelines dan aan het leveren van inzichten, wordt LCNC strategisch belangrijk. De beslissing gaat niet over het vervangen van engineers, maar over het herverdelen van inspanningen van repetitief integratiewerk naar waardevolle bedrijfslogica en AI-gestuurde innovatie.
Het grootste risico is de oplopende technische schuld en de vertraging van de besluitvorming. Naarmate data-ecosystemen groeien, leiden losgekoppelde tools tot exponentieel hogere onderhoudskosten. Dit vertraagt het verkrijgen van inzichten, vermindert het vertrouwen in data en verzwakt AI-initiatieven. Leiders moeten de adoptie van LCNC niet zien als een toolkeuze, maar als een architectuurbeslissing die van invloed is op de schaalbaarheid op lange termijn.
Leidinggevenden zouden prioriteit moeten geven aan platforms met ingebouwde governance, dataherkomst en toegangscontrole, in plaats van governance later toe te voegen. De focus moet liggen op uniforme zichtbaarheid over alle pipelines en datastromen. Door governance in de architectuur te integreren, wordt compliance automatisch geschaald in plaats van een reactieve, handmatige inspanning te worden.
CIO's en CDO's zouden prioriteit moeten geven aan architecturale uniformiteit, niet alleen aan gebruiksgemak. Het platform moet de volledige dataflow ondersteunen – van data-invoer tot AI-activering – binnen één ecosysteem. De cruciale vraag is of het platform toekomstige agentische AI-workflows mogelijk maakt of juist een nieuwe, losgekoppelde laag in de data-stack creëert.