 Kshitij GuptaDatenstratege
Kshitij GuptaDatenstratege
Melden Sie sich an, um die neuesten Einblicke und Updates zu Technologie, KI & Datenanalyse, Data Science und Innovationen von Polestar Analytics zu erhalten.
Jahrzehntelang bedeutete die Entwicklung einer KI-Anwendung in Echtzeit die Verwaltung zweier grundlegend inkompatibler Systeme. Die Infrastruktur für Analytik und maschinelles Lernen befand sich auf der einen Seite – in einem Data Lake oder Data Warehouse, das auf hohen Durchsatz ausgelegt war. Die operative Datenbank hingegen befand sich auf der anderen Seite – eine eigenständige PostgreSQL-Instanz, die die aktuellen Benutzeraktivitäten erfasste. Dazwischen lag eine fehleranfällige Pipeline: Change-Data-Capture-Jobs, ETL-Synchronisierungen und Replikationslogik, die planmäßig ausfielen und Latenzen in Minuten, nicht in Millisekunden, verursachten.
Die wirtschaftlichen Kosten dieser architektonischen Fragmentierung sind gut dokumentiert. Unternehmen erleiden durchschnittlich jährlich Verluste in Höhe von 12,9 Millionen US-Dollar, die direkt auf mangelhafte Datenqualität zurückzuführen sind – eine Summe, die sich noch erhöht, wenn Echtzeit-KI-Systeme gezwungen sind, mit veralteten, durch die Pipeline verzögerten Daten zu arbeiten.
Bis 2026 werden Unternehmen jedoch 60 % der KI-Projekte aufgeben, die nicht über geeignete Daten verfügen. Der Engpass liegt nicht in der Rechenleistung oder der Modellqualität, sondern in der Diskrepanz zwischen Transaktionsdaten und den KI-Systemen, die diese Daten verarbeiten sollen.
Databricks Lakebase ist die architektonische Antwort auf diese Lücke. Operative Datenbanken bilden einen Markt mit einem Volumen von über 100 Milliarden US-Dollar und sind die Grundlage jeder Anwendung. Sie basieren jedoch auf einer jahrzehntealten Architektur, die für sich langsam verändernde Anwendungen konzipiert wurde. Dies macht sie schwer zu verwalten, teuer und anfällig für Anbieterabhängigkeit. Künstliche Intelligenz (KI) führt zu neuen Anforderungen: Jede Datenanwendung, jeder Agent, jede Empfehlung und jeder automatisierte Workflow benötigt nun schnelle und zuverlässige Daten in der Geschwindigkeit und im Umfang von KI-Agenten .
Seit dem Start im Juni 2025 ist die Akzeptanz mehr als doppelt so schnell gewachsen wie beim Data-Warehousing-Produkt von Databricks. Tausende von Unternehmen führen Produktionsworkloads direkt auf ihren operativen Daten aus.
Der herkömmliche Ansatz zur Entwicklung von Datenanwendungen erforderte einen erheblichen Kompromiss in der Softwareentwicklung. Man musste den Informationsanwendungsfall – historischer Kontext, Generierung von ML-Features, analytische Abfragen – gegen den Transaktionsanwendungsfall abwägen – Erfassung der Nutzerklicks von vor drei Sekunden, Aktualisierung des Inventars in Echtzeit, Speicherung des Agentenstatus während des Workflows.
Die Handhabung beider Systeme erforderte den Betrieb separater Datenbanken, die über fehleranfällige Datenleitungen miteinander verbunden waren. Das Ausmaß dieses Problems ist beträchtlich: Datenteams melden durchschnittlich 67 Störungen in den Datenleitungen pro Monat, und 68 % der Teams benötigen vier oder mehr Stunden, um einen Fehler zu erkennen. Dateningenieure wurden zu „Pipeline-Feuerwehrleuten“. ML-Modelle griffen auf Daten zurück, die bereits veraltet waren, wenn sie eintrafen. Echtzeit-KI-Anwendungen erwiesen sich als Widerspruch in sich.
Lakebase auf der Databricks-Datenbankplattform ist nicht einfach nur „Postgres auf Databricks“. Es ist ein Paradigmenwechsel in unserer Denkweise über operative und analytische Daten, die zusammen existieren – verwaltet, abfragbar und unterstützt von derselben Plattform.
Anstatt eine separate Datenbank einzurichten, Reverse-ETL-Jobs zu erstellen und die Authentifizierung an zwei Stellen zu verwalten, können Teams jetzt verwaltete Lakehouse-Tabellen mit Millisekunden-Abfragezeiten in Postgres synchronisieren, Anwendungsstatus- und Transaktionstabellen direkt in Databricks Lakebase erstellen und alles mit Databricks-Identitäten und Postgres-Rollen sichern.
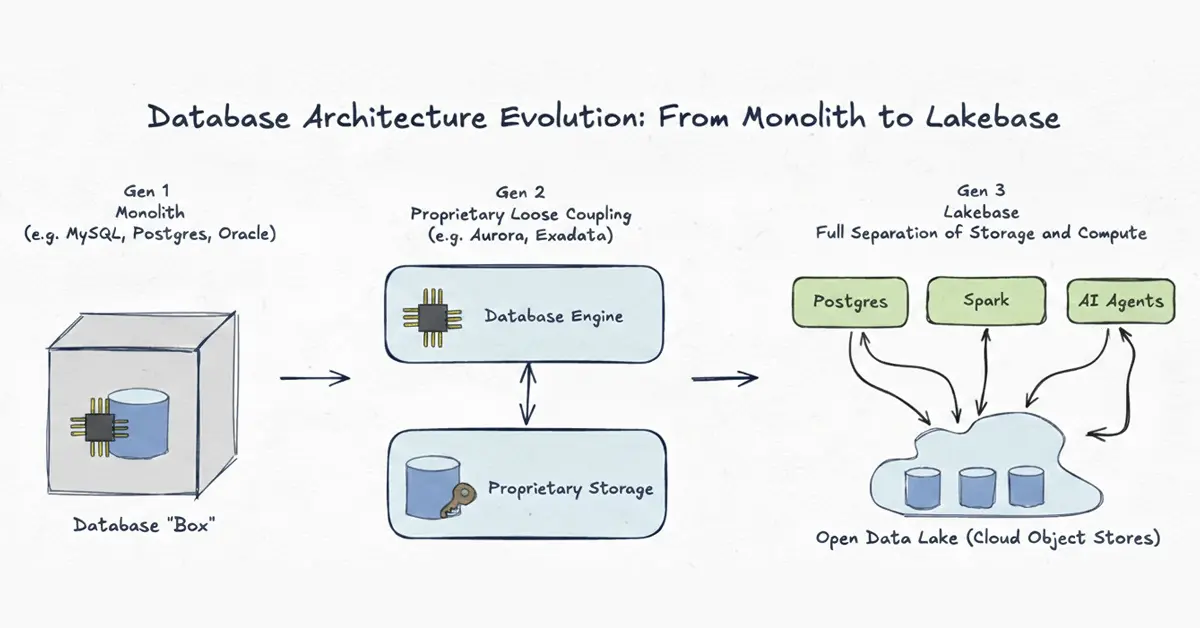
Wie sich die Datenbankarchitektur über drei Generationen hinweg entwickelt hat – von monolithischen On-Premise-Systemen hin zur vollständig entkoppelten, offenen Lakebase-Architektur. Die Trennung von Rechenleistung und Speicher ist der zentrale Durchbruch, der KI-Anwendungen in Echtzeit ohne fehleranfällige Pipelines ermöglicht.
Databricks Lakebase vereinfacht die Anwendungsentwicklung mit einer bewährten OLTP-Datenbank und beseitigt so die Probleme der Datenbankverwaltung. Komplexe, benutzerdefinierte ETL-Pipelines entfallen, und Transaktionsdaten werden nahtlos in Analysen und KI-native Databricks-Anwendungen integriert. Teams vermeiden Entwicklungsverzögerungen durch die Nutzung des vertrauten Open-Source-PostgreSQL mit bestehenden Bibliotheken , Frameworks und SQL – mit entkoppelter Rechen- und Speicherinfrastruktur für unabhängige Skalierung, Wiederherstellung zu einem bestimmten Zeitpunkt und der Möglichkeit, die Datenbank wie Code zu versionieren.
Die Databricks Lakebase-Architektur vereint die Zuverlässigkeit und Vertrautheit von PostgreSQL mit modernen Datenbankfunktionen wie Autoscaling, Scale-to-Zero, Branching und Instant Restore. Diese Funktionen ermöglichen flexible Entwicklungs-Workflows, kosteneffizienten Betrieb und schnelle Iterationen. Die Plattform integriert Echtzeit-Feature-Serving für ML-Modelle und den Feature Store, Agentenstatus für KI-Agenten sowie Transaktionsdaten für Databricks Apps und alle damit verbundenen Anwendungen.
Der Datenaustausch zwischen Lakehouse und Lakebase erfolgt in beide Richtungen:
In beide Richtungen. Keine benutzerdefinierten Pipelines!
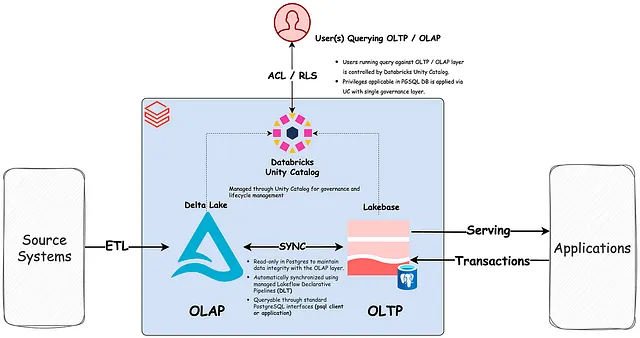
Die Databricks Lakebase-Architektur: Transaktionsverarbeitung (Postgres) läuft unabhängig auf einem offenen Speicherformat im Lake und vereint OLTP- und OLAP-Workloads auf einer einzigen, kontrollierten Grundlage – ohne dazwischenliegende ETL-Pipelines.
Die Lakebase Databricks-Plattform bietet einen produktionsreifen Funktionsumfang:
| Besonderheit | Was es bewirkt | Warum das wichtig ist |
|---|---|---|
| Serverloses Autoscaling & Scale-to-Zero | Die Rechenleistung passt sich dynamisch dem Datenverkehr an und schaltet sich bei Leerlauf ab. | Vermeidet unnötige Ausgaben für ungenutzte Infrastruktur |
| Sofortige Datenbankverzweigung | Erstellt in Sekundenschnelle Nullkopien der Produktionsdaten. | Risikofreies Testen ohne Duplizierung vollständiger Datensätze |
| Point-in-Time Recovery (PITR) | Stellt die Datenbank auf einen beliebigen Millisekundenstand innerhalb des Aufbewahrungszeitraums wieder her. | Schutz vor versehentlichem Löschen und Anwendungsfehlern |
| Unity Catalog Governance | Einheitliches Sicherheitsmodell für operative und analytische Daten | Eine einzige Zugriffskontrollrichtlinie für den gesamten Datenbestand |
| Tabellen synchronisieren | Sorgt automatisch für die Synchronisierung der Daten von Lakehouse und Lakebase | Keine anfälligen Pipelines; keine manuellen Synchronisierungsaufträge |
| Postgres 17-Unterstützung + pgvector | Vollständige Postgres-Kompatibilität inklusive KI-nativer Vektorsuche | Nutzen Sie vorhandene Tools; aktivieren Sie die semantische und Ähnlichkeitssuche nativ. |
Die Branching-Funktion verdient besondere Beachtung. Ähnlich wie Git für Datenbanken ermöglichen Branches Teams, innerhalb von Sekunden isolierte Umgebungen aus Produktionsdaten zu erstellen – Schemaänderungen zu testen, neue Anwendungslogik zu validieren, Lasttests durchzuführen – ohne Live-Workloads zu beeinträchtigen oder für eine vollständige Datenduplizierung zu bezahlen.
Die Bereitstellung einer produktionsreifen Anwendung auf der Lakebase Databricks-Plattform folgt einem strukturierten Ablauf. Die Dokumentation zu Microsoft Azure Databricks Lakebase und der Databricks-Blog zum Erstellen produktionsreifer Anwendungen beschreiben dies detailliert.
Die wichtigsten Phasen sind:
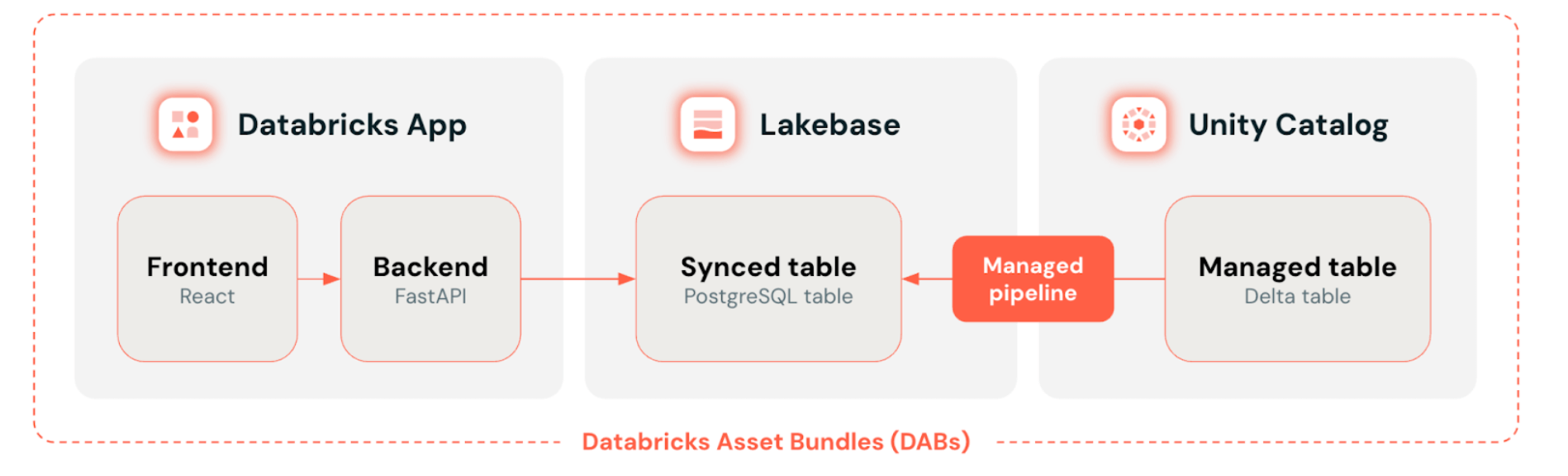
So wird eine produktionsreife Datenanwendung auf der Lakebase Databricks-Plattform zusammengestellt: Databricks Apps im Frontend, Databricks Lakebase als Transaktionsdatenschicht, Unity Catalog zur Verwaltung von kontrollierten Delta-Tabellen mit automatischer Synchronisierung – alles als Code über Databricks Asset Bundles bereitgestellt.
Die Anwendungsfälle der Lakebase-Datenbank erstrecken sich über verschiedene Branchen und Architekturmuster. Databricks Lakebase identifiziert die folgenden primären Workload-Typen:
| Industrie | Anwendungsfall der Lakebase-Datenbank | Was es ersetzt |
|---|---|---|
| Einzelhandel & E-Commerce | Personalisierte Empfehlungen und zielgerichtete Angebote in Echtzeit | Eigenständige Empfehlungsmodule, die von verzögerten Batch-Pipelines gespeist werden |
| Gesundheitspflege | Datenmanagement klinischer Studien in Verbindung mit prädiktiven Diagnosemodellen | Abgeschottete OLTP-Datenbanken, die von analytischen ML-Schichten getrennt sind. |
| Finanzdienstleistungen | Automatisierte Handels- und Streaming-Betrugserkennungsanalysen | Separate operative Datenbanken mit CDC-Pipelines zur Datenanalyse |
| Herstellung | Maschinentelemetrie-Erfassung und Workflows für die vorausschauende Wartung | Lokale Historian-Systeme mit manuellen Datenexportaufträgen |
| Medien & Unterhaltung | Echtzeit-Inhaltspersonalisierung und Zielgruppen-Engagement-Tracking | Fragmentierte Ereignisverfolgung mit verzögerter Warehouse-Synchronisierung |
Databricks Lakebase wurde für ein spezifisches Problem entwickelt. Es ist kein universeller Ersatz für jede operative Datenbank. Hier ist ein klarer Rahmen zur Beurteilung der Eignung:
Verwenden Sie Databricks Lakebase, wenn:
Azure Databricks Lakebase- Nutzer sollten vor der Planung latenzkritischer globaler Bereitstellungen die aktuelle regionale Verfügbarkeit der Autoscaling-Funktion der Plattform – die die wichtigsten AWS- und Azure-Regionen abdeckt – beachten. Die Azure-Dokumentation beschreibt die unterstützten Regionen und Konfigurationsdetails.
Databricks Lakebase unterstützt Latenzzeiten unter 10 ms für Workloads mit hohem Durchsatz und deckt damit die überwiegende Mehrheit der Anforderungen von KI-Anwendungen in Unternehmen ab. Die Kombination von Databricks Lakebase mit der OLTP-Datenbank ermöglicht die Lösung architektonischer Probleme auf grundlegend andere Weise und ebnet den Weg weg von fehleranfälligen ETL-Pipelines und der erzwungenen Trennung von Analyse- und Betriebsschichten.
Databricks Lakebase ist jetzt allgemein auf AWS verfügbar und befindet sich in der Beta-Phase auf Azure. Ein wachsendes Netzwerk von Launch-Partnern hat die Plattform für die Datenbankmodernisierung, die Entwicklung von Echtzeitanwendungen und agentenbasierte KI-Workflows validiert. Die Launch-Partner von Databricks Lakebase unterstützen Kunden dabei, von diesem Wandel zu profitieren, da sie die Lakebase-Plattform von Databricks für die Datenbankmodernisierung, die Entwicklung von Echtzeitanwendungen und die Bereitstellung agentenbasierter KI-Workflows validiert haben.
Polestar Analytics gehört zu den Launch-Partnern. Als Spezialist für die native Databricks- Implementierung in den Bereichen Data Engineering, KI-Anwendungen und Databricks Lakebase-Architektur bietet Polestar Analytics die Implementierungsmethodik – Architekturdesign, Datenflussmapping, Governance-Konfiguration und Anwendungsintegration –, die eine technisch leistungsfähige Plattform in ein zuverlässiges und skalierbares Produktionssystem verwandelt. Die Databricks-Datenbankplattform beseitigt den architektonischen Engpass. Ein bewährter Implementierungspartner minimiert das Bereitstellungsrisiko.
Databricks Lakebase-Integrationsübersicht: Wo Lakebase in die Gesamtplattform eingebettet ist
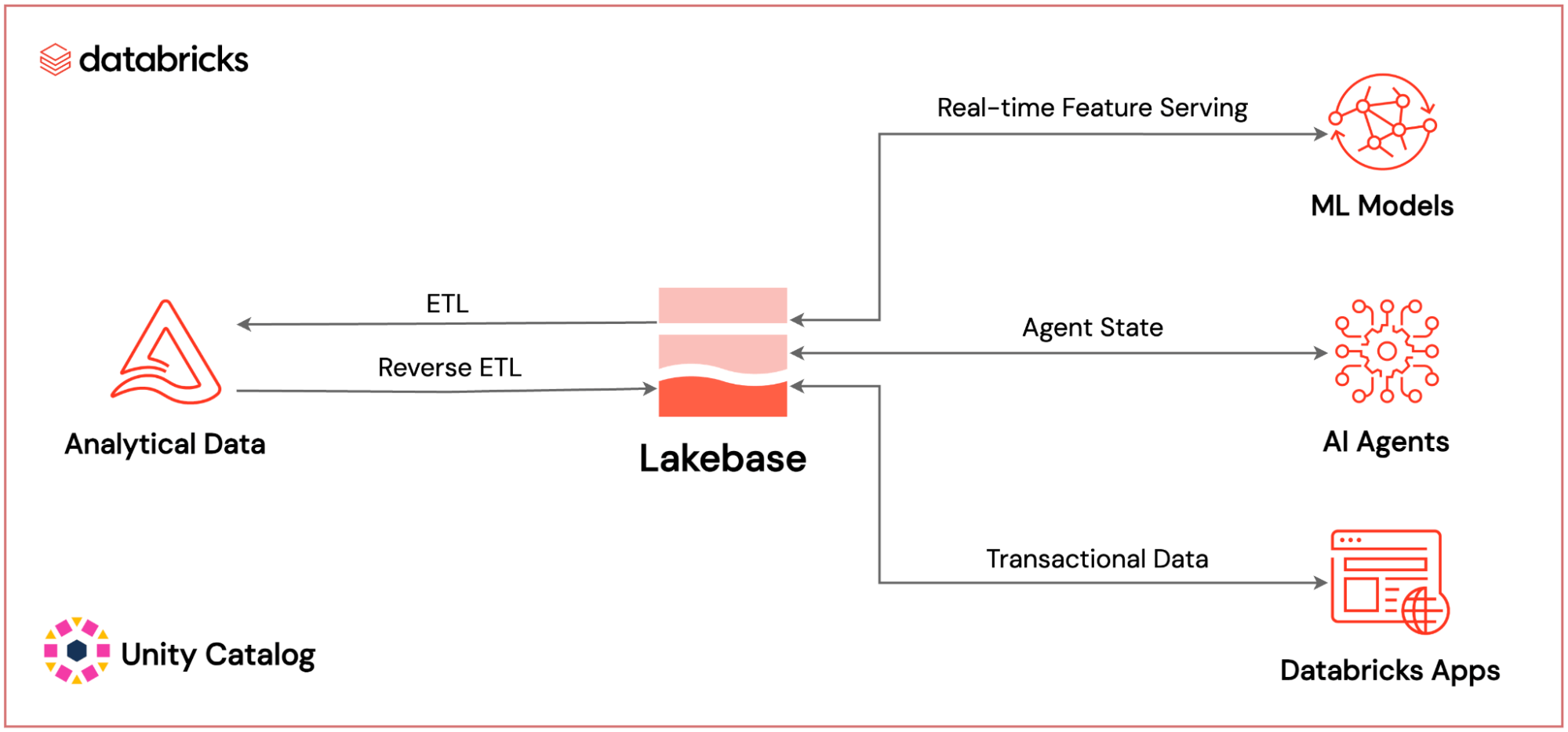
Wo Databricks Lakebase innerhalb der gesamten KI-nativen Plattform von Databricks angesiedelt ist: Bereitstellung von ML-Funktionen in Echtzeit, Persistenz des KI-Agentenstatus und Transaktionsdaten von Anwendungen – alles gesteuert durch Unity Catalog.
Entwickeln Sie Ihre Echtzeit-KI-Anwendung auf Databricks Lakebase. Vom Architekturentwurf von Databricks Lakebase bis zur Produktionsbereitstellung – Polestar Analytics begleitet Sie in jeder Phase Ihrer Implementierung.
Sprechen Sie mit unserem IngenieurteamLakebase steuert den bidirektionalen Datenaustausch über zwei dedizierte Mechanismen: Synced Tables und Lakehouse Sync. Beide arbeiten ohne benutzerdefinierte Pipelines. Die Konsistenz wird auf Plattformebene gewährleistet, wodurch manuelle ETL-Prozesse entfallen, die üblicherweise zu Abweichungen, unbemerkten Fehlern oder Latenzzeiten führen.
Nein, Lakebase ist mit Postgres 17 kompatibel, daher funktionieren bestehende Treiber, ORMs, SQL-Abfragen und Bibliotheken weiterhin ohne Änderungen. Die Änderung betrifft lediglich, wo Postgres ausgeführt wird und womit es sich verbindet, nicht die tägliche Interaktion der Entwickler damit.
Ja, Teams nutzen es heute schon für operative Dashboards, Echtzeit-Personalisierung und Transaktionsanwendungen, die einfach nur saubere, verwaltete Daten ohne zusätzlichen Aufwand benötigen. Die KI-Funktionen stehen zur Verfügung, sobald Sie bereit sind, sind aber keine Voraussetzung, um vom ersten Tag an einen Mehrwert zu erzielen.
Über den Autor
Datenstratege
Die meisten Daten beantworten Fragen. Die richtigen Daten ändern die Richtung.
Verwandter Blog
Kshitij Gupta
Kshitij Gupta