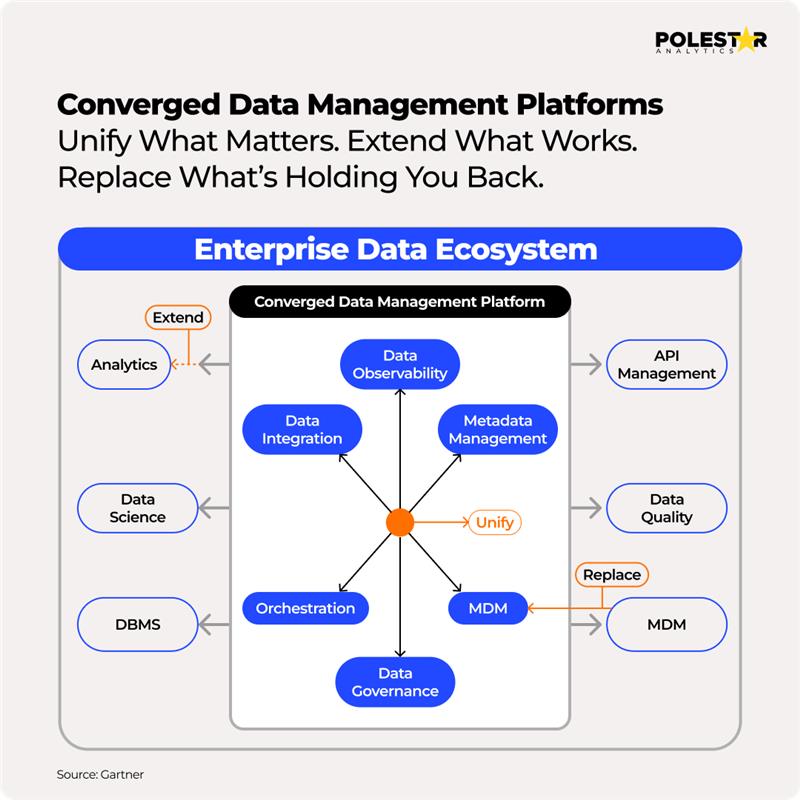
Een geconvergeerd dataplatform is één enkele data-infrastructuur. Het integreert data-acquisitie, -opslag, -beheer, kwaliteitscontrole en -analyse in één data-architectuur. Het vervangt bovendien losgekoppelde en op tools gebaseerde datasystemen.
- End-to-end workflowcoördinatie: De pipeline is geautomatiseerd, waardoor gegevens naadloos stromen zonder dat elk systeem binnen een onderling verbonden omgeving handmatig hoeft te worden gecontroleerd om een correcte gegevensstroom te garanderen.
- Vermindering van de wildgroei aan tools: Door een uniforme interface te gebruiken en verschillende tools en applicaties te verwijderen, kan een zakelijke gebruiker zich concentreren op het behalen van doelstellingen in plaats van te jongleren met een verscheidenheid aan overlappende applicaties en oplossingen.
- Snellere toegang tot bruikbare data: Met volledig inzicht in alle beschikbare informatie binnen een organisatie kunnen sneller en beter onderbouwde beslissingen worden genomen, en is data sneller beschikbaar voor AI-initiatieven.
Laag 1: Governance- en gegevensreferentielaag (Fundament)
Deze fundamentele laag creëert uw data-ecosysteem als één enkele bron van waarheid door:
- Het metadataregister is in wezen een informatieopslagplaats die een overzicht biedt van gegevensbronnen, locaties, inhoud en de waarde ervan voor gebruikers.
- Pipeline Management wordt gebruikt om te bepalen hoe componenten met andere componenten verbonden zijn om gegevens binnen het ecosysteem over te dragen en te wijzigen.
- Operationele controle: monitoring, meldingen en foutregistratie voor alle pijplijnen.
Laag 2: Gegevensverrijkingslaag (Intelligentie)
Deze laag zet ruwe data om in een bruikbare bron:
- ML-gestuurde verfijning: maakt gebruik van machine learning-modellen en statistische berekeningen om inzichten, signalen en belangrijke indicatoren te genereren. Dit helpt bij het nemen van betere beslissingen.
- Gebruiksvriendelijkheid verbeterd: Wijzigingen en verbeteringen in de datakwaliteit, samen met het toevoegen van betekenis, maken data geschikt voor gebruik door zowel menselijke gebruikers als AI-systemen.
Laag 3: Betrokkenheid en interactie (ervaring)
Deze bovenste laag biedt gebruiksvriendelijke toegang met:
- Op gebruikersprofielen gebaseerde visualisatie: Biedt een interface die is afgestemd op data-engineers, data-analisten en leidinggevenden binnen de organisatie.
- Semantisch zoeken: Vragen in natuurlijke taal die relevante gegevensproducten tonen.
- Zelfservice-analyse: een oplossing voor zakelijke gebruikers waarmee ze gegevens kunnen analyseren zonder afhankelijk te zijn van continue IT-ondersteuning.
- Maakt slimmere AI mogelijk met gecontroleerde toegang. Het geeft AI-systemen volledig contextueel inzicht, consistente semantiek en realtime data, ongeacht de gebruikte systemen. Uit onderzoek van Gartner blijkt dat 61% van de organisaties hun data-analysemodel specifiek voor AI aan het ontwikkelen is , waardoor de focus verschuift van probleemdetectie naar uitvoerbare oplossingen.
- Verhoogt de operationele efficiëntie op grote schaal: het combineert monitoring, CI/CD en connectiviteit in één dashboard. Hierdoor zijn maatwerkintegraties en training voor meerdere tools niet meer nodig. Bovendien versnelt het de omzetting van data naar waarde door middel van veilige, proactieve workflows.
- Strategische transformatie van datateams: Dataprofessionals kunnen hierdoor probleemoplossende en reconciliatietaken vermijden. Om waarde te creëren voor het hele bedrijf, kunnen ze zich vervolgens concentreren op AI-innovatie, dataproducten en zakelijke samenwerkingen.
Polestar Analytics' 1Platform lost fragmentatie op door Azure, AWS, GCP, Databricks en Snowflake te federeren in één beheerd systeem – zonder dat data verplaatst hoeft te worden. Technische teams behouden hun flexibiliteit. Zakelijke gebruikers gebruiken gebruiksvriendelijke interfaces met weinig of geen code, inclusief governance voor consistent beleid binnen de ecosystemen.
Lees meer: blog over het Converged Data Platform.