
Vat dit blogbericht samen met:
In de huidige competitieve zakelijke omgeving is het implementeren van een Enterprise Data Warehouse niet zomaar een IT-project, maar een strategische noodzaak. Met de dagelijks toenemende hoeveelheid data, die naar verwachting in 2028 wereldwijd meer dan 394 zettabytes zal bedragen, moet u ervoor zorgen dat uw Enterprise Data Warehouse-systeem niet alleen geschikt is voor opslag, maar ook voor de groeiende vraag naar analyses.
Je weet vast al wat het is. Een Enterprise Data Warehouse (EDW) is als de Marie Kondo van je datalandschap: het brengt orde in de ongeorganiseerde chaos door informatie uit verschillende systemen samen te voegen in een overzichtelijke, gecentraliseerde opslagplaats die analyses ondersteunt. Het is niet zomaar een database, maar een architecturale oplossing die business intelligence-functies en weloverwogen besluitvorming mogelijk maakt.
De eerste enterprise data warehouses (EDW's) waren gecentraliseerd. Ze maakten gebruik van relationele systemen gebouwd op SQL-databases met functies zoals SELECT, JOIN en GROUP BY voor het verwerken van historische rapporten en basis business intelligence.
Moderne Enterprise Data Warehousing (EDW)-diensten zijn gedistribueerde en cloudgebaseerde platforms. Ze maken gebruik van technologieën zoals Massively Parallel Processing (MPP)-databases , data lakes en streaming-ingestie, waarmee verschillende gegevenstypen – gestructureerde, semi-gestructureerde en ongestructureerde data – worden beheerd. Daarnaast ondersteunen ze realtime analyses, ACID-transacties, complexe SQL-functies en integratie met AI/ML-tools voor het nemen van operationele beslissingen, met behulp van ELT en datavisualisatie.
Maar laten we eerlijk zijn, zonder een efficiënte implementatie blijken de meeste bedrijfsdatawarehouses uiteindelijk niet meer te zijn dan veredelde opslagsystemen.
Wat onderscheidt de topbedrijven? Het is zelden de technologie zelf, maar eerder de manier waarop ze hun datawarehouseplatforms implementeren en verder ontwikkelen door middel van strategische best practices.
Om het maximale uit uw datawarehouse te halen, volgt u deze vijf best practices met een logisch implementatieplan:
Beste praktijk: Stel meetbare bedrijfsdoelstellingen vast voordat u zelfs maar nadenkt over de technologiekeuze.
De meeste implementaties van datawarehouses voor bedrijven mislukken omdat het IT-projecten blijven die worden afgemeten aan uptime en queryprestaties in plaats van aan bedrijfsresultaten. De strategie zou in plaats daarvan moeten beginnen vanuit een bedrijfsresultaat. Definieer bijvoorbeeld specifieke, meetbare resultaten zoals:
Beslissingssnelheid: Het verkorten van de wekelijkse voorraadplanningscycli van 5 dagen naar 2 dagen (wat een efficiëntiewinst van 2,5x vereist) zou er ruwweg als volgt uit kunnen zien (uitgaande van 1 TB aan huidige wekelijkse data) : een toename van 20-40% in rekenkracht.
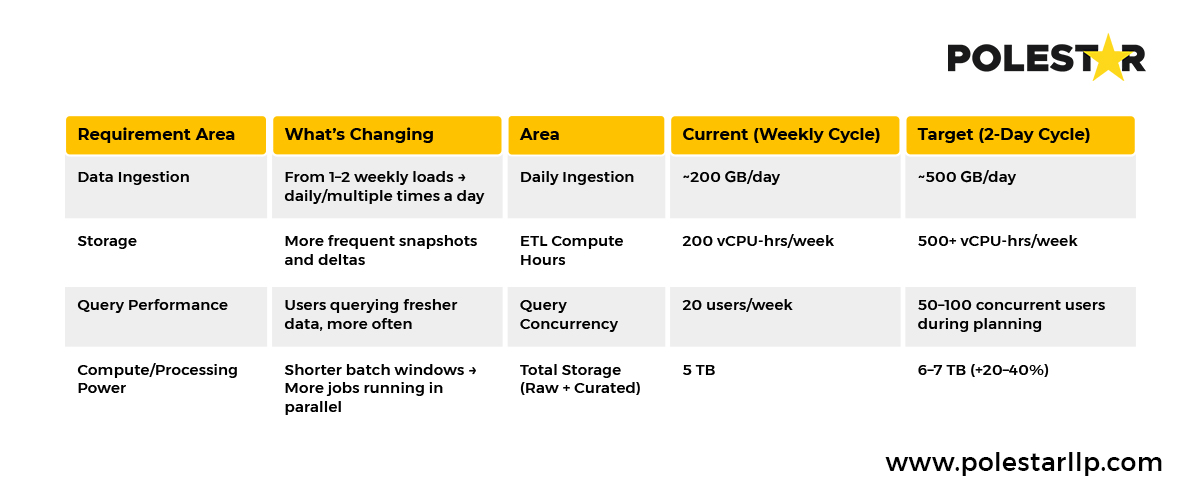 Een voorbeeld van hoe afstemming binnen de bedrijfsstrategie de magazijnstrategie beïnvloedt.
Een voorbeeld van hoe afstemming binnen de bedrijfsstrategie de magazijnstrategie beïnvloedt. Of uw focus nu ligt op klantbehoud, operationele efficiëntie of naleving van regelgeving, de optimalisatie of kenmerken van uw Enterprise Data Warehouse moeten deze resultaten direct mogelijk maken door middel van duidelijke meetbare resultaten.
Beste praktijk: Implementeer uitgebreide procedures voor gegevenskwaliteit in de staginglaag zelf.
De meeste datawarehouses beschikken tegenwoordig over een stagingomgeving die fungeert als cruciaal controlepunt tussen bronsystemen en productieomgevingen voor datakwaliteit. Het gaat hierbij echter niet alleen om datavalidatie, maar om het opzetten van een systematisch kwaliteitsborgingssysteem dat meegroeit met het datavolume en de complexiteit van uw data. Enkele best practices voor deze laag zijn:
| Gebied | Beste praktijk |
|---|
| Gegevensgetrouwheid | Rauw houden; geen bewerkingen uitvoeren. |
|---|
| Laden | Alleen toevoegen; voorzien van tijdstempel |
|---|
| Indeling | Op datum/bron |
|---|
| Metadata | Sla laadtijdstempels, bestandsnamen en batch-ID's op. |
|---|
| Kwaliteitscontroles | Alleen lichtgewicht validaties |
|---|
| Beveiliging | Versleutelen + toegang beperken |
|---|
| Behoud | Stel een vervaltermijn in (bijv. 30-90 dagen). |
|---|
| Traceerbaarheid | Schakel herkomst- en batchtracering in. |
|---|
| Opslagformaat | Geef de voorkeur aan kolomgeoriënteerde formaten zoals Parquet/Delta. |
|---|
PS Deze werkwijzen worden specifieker wanneer je een ander type platform gebruikt, zoals GCP , AWS of Databricks. Bijvoorbeeld: het toepassen van vacuumbeleid (VACUUM Delta-tabellen na 7-30 dagen) om opslagruimte vrij te maken, of het inschakelen van data lifecycle management (DLM) bij gebruik van Unity Catalog met cloudopslag voor een Databricks-implementatie .
Praktische toepassing: Hybride integratiebenaderingen die aansluiten op de snelheidseisen van de bedrijfsvoering.
De strategische waarde van een Enterprise Data Warehouse (EDW) ontstaat door de integratie van diverse informatiebronnen in samenhangende bedrijfsinzichten. Moderne EDW-implementaties moeten traditionele batchverwerking voor historische analyses ondersteunen en tegelijkertijd realtime datastromen mogelijk maken voor operationele besluitvorming. Enkele veelgebruikte best practices die organisaties tegenwoordig hanteren zijn:
- Integratie door het inzetten van Change Data Capture (CDC) voor continue synchronisatie en het configureren van orchestratie voor gemengde verwerking.
- De juiste integratiemethode – ETL voor workflows met strenge compliance-eisen, ELT voor schaalbaarheid of realtime streaming voor live analyses – hangt af van de bedrijfsbehoeften.
- Implementeer intelligente pijplijnorkestratie
- Implementeer geavanceerd afhankelijkheidsbeheer
- Implementeer automatische schaalbaarheid van de pijplijnuitvoering
- Configureer intelligente foutafhandeling en monitoring.
- Of gebruik zelfs realtime data-invoer met tools zoals Apache Kafka of AWS Kinesis voor het streamen van databronnen.
Maar om echt de beste data-integratie in het AI-tijdperk te realiseren, moet je repetitieve taken zoals data-extractie, -transformatie, -laden en modelcreatie automatiseren om de efficiëntie te verbeteren en fouten te verminderen. En wij hebben een van de beste oplossingen daarvoor: Data Nexus !
Beste praktijk: Ontwerp een OLAP-engine binnen een drielaagse Enterprise Data Warehouse-architectuur, afgestemd op de analytische consumptiepatronen.
De architectuur van uw Enterprise Data Warehouse bepaalt de wendbaarheid van uw organisatie. De meest effectieve EDW-implementaties hanteren daarom een drielaagse architectuurstrategie die een balans vindt tussen prestatie-eisen en de toegankelijkheidsbehoeften van de organisatie.
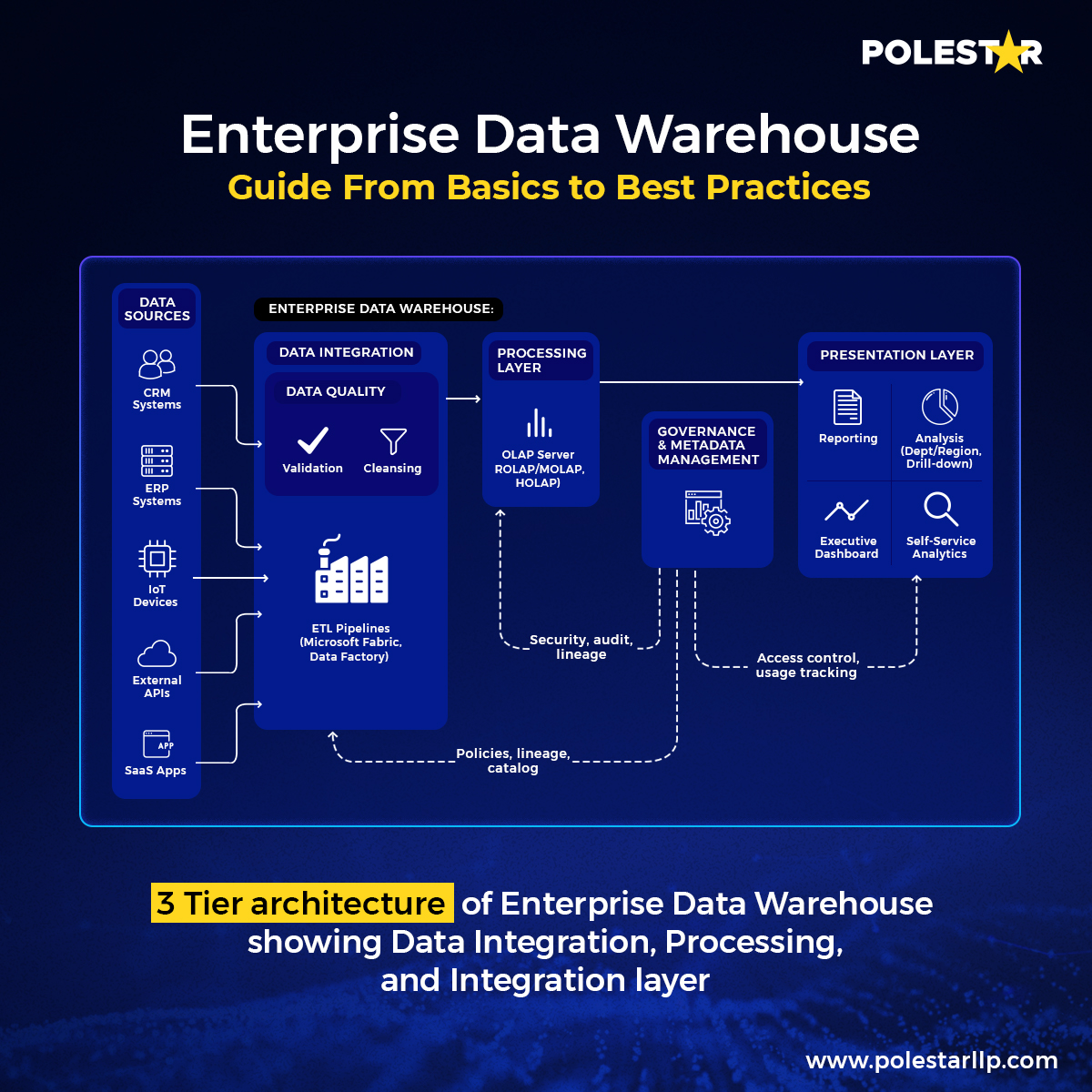 3-laags architectuur van een Enterprise Data Warehouse
3-laags architectuur van een Enterprise Data Warehouse De verwerkingslaag moet voor OLAP-engines worden geconfigureerd op basis van specifieke analytische en zakelijke vereisten:
- ROLAP (Relationele OLAP): Dit is bedoeld voor gedetailleerde, onderzoekende analyses waarbij de actualiteit van gegevens en de mogelijkheid om in te zoomen op details cruciaal zijn. Zo gebruiken financiële dienstverleners ROLAP bijvoorbeeld voor compliance-onderzoeken waarbij reactietijden van 10 tot 30 seconden op gedetailleerde transactiegegevens vereist zijn.
- MOLAP (Multidimensional OLAP): Optimaal voor managementdashboards die responstijden van minder dan een seconde vereisen voor vooraf gedefinieerde statistieken. Retailbedrijven gebruiken MOLAP bijvoorbeeld voor dagelijkse verkoopdashboards, waarbij ze grote hoeveelheden vooraf geaggregeerde data opslaan en direct inzichten leveren.
- HOLAP (Hybrid OLAP): Combineert beide benaderingen voor organisaties die behoefte hebben aan snelheid voor het management en diepgaande analyses. Een productiebedrijf zou bijvoorbeeld een HOLAP-architectuur implementeren waarbij productiemanagers via ROLAP-query's toegang hebben tot de realtime status van apparatuur, terwijl managers via MOLAP-kubussen vooraf geaggregeerde dagelijkse productieoverzichten kunnen bekijken.
Moderne platforms zoals Microsoft Fabric illustreren deze flexibele architectuur met OneLake als dataopslagplaats, Synapse Data Warehouse voor de OLAP-laag (met ondersteuning voor HOLAP) en Power BI voor presentatie. Hierdoor kunnen organisaties binnen één platform profiteren van zowel datawarehousebeheer als de flexibiliteit van een datalake.
Praktische informatie: Naast het waarborgen van de herkomst van gegevens, moeten metadata nu ook LLM's en agenten kunnen ondersteunen.
In het AI-tijdperk is metadata niet langer slechts een catalogus; het is de brandstof voor automatisering, herkomstregistratie, governance en intelligente ontdekking. Effectief metadata-management is verder geëvolueerd dan alleen technische documentatie. Moderne metadata-benaderingen richten zich op de zakelijke context naast technische specificaties, met name nu organisaties zich voorbereiden op AI en agentgestuurde workflows.
Er zijn dus een aantal zaken om in de gaten te houden met betrekking tot standaardisatie, versiebeheer, de zakelijke context en monitoring, zoals:

Aanvullende best practices voor metadata voor agents en generatieve AI
- Metadatacatalogi moeten leesbaar zijn voor LLM via API's of via ingebedde opslagplaatsen.
- Maak het eenvoudiger om Retrieval-Augmented Generation (RAG)-systemen en data-copiloten van stroom te voorzien met contextuele metadata.
- Automatiseer het taggen en classificeren van datasets (bijv. financiën, klanten, persoonsgegevens).
Nieuwe technologieën, groeiende datavolumes en veranderende bedrijfsbehoeften vereisen allemaal een effectief enterprise datawarehouse of zelfs een modern lakehouse-systeem. En daarvoor vormen de AI-gestuurde datawarehouse-oplossingen van Polestar Analytics de volgende stap in de transformatie van uw datastrategie!
V: Hoe kan generatieve AI de werking van bedrijfsdatawarehouses verbeteren?
A: Generatieve AI zou de werking van Enterprise Data Warehouses op de volgende gebieden transformeren:
Geautomatiseerde gegevensvoorbereiding: AI genereert ETL-code, waardoor de ontwikkeltijd wordt verkort en de kwaliteitsnormen voor gegevens worden gewaarborgd. AI kan bijvoorbeeld automatisch transformatieregels aanmaken wanneer nieuwe gegevensbronnen worden toegevoegd.
Querygeneratie: Zakelijke gebruikers kunnen hun analytische behoeften in natuurlijke taal beschrijven, waarna AI geoptimaliseerde SQL-query's genereert, waardoor deze voor iedereen toegankelijk zijn. Geautomatiseerde inzichten: AI monitort datapatronen en genereert zakelijke inzichten. Het waarschuwt relevante belanghebbenden voor afwijkingen zonder handmatige analyse.
V: Wat is Lakehouse-architectuur? Waarin verschilt deze van traditionele Enterprise Data Warehouses?
A: Data Lakehouse is een hybride platform voor gegevensopslag en -verwerking dat het beste van traditionele data lake- en data warehousingtechnologieën combineert: goedkope opslag in een open formaat dat toegankelijk is voor diverse systemen (van de eerste) en krachtige beheer- en optimalisatiefuncties (van de laatste).
| Functie | Traditionele EDW | Architectuur van huizen aan het meer |
|---|
| Gegevenstypen | Voornamelijk gestructureerd | Alles (gestructureerd, semi-gestructureerd, ongestructureerd) |
|---|
| Schema | Schema-on-Write (rigide) | Schema-on-Read/Write (flexibel) |
|---|
| Wendbaarheid | Minder flexibel, lastig voor nieuwe werklasten. | Zeer flexibel, ondersteunt diverse analyses (BI, ML) |
|---|
| Kosten | Vaak hoger (eigendomsrechtelijk beschermd) | Over het algemeen lager (open formaten, cloud-native) |
|---|
| Bestuur/ACID | Sterke ACID-transacties en governance (ingebouwd) | Voegt ACID- en governance-functies toe aan een data lake (bijv. Delta Lake). |
|---|
V: Wat zijn de belangrijkste elementen van een Enterprise Data Warehouse?
A: Een uitgebreid Enterprise Data Warehouse-systeem integreert vier belangrijke elementen:
Centrale database: De architectonische basis voor kolomopslag, geoptimaliseerd voor analytische query's. Hulpmiddelen voor data-integratie: Geavanceerde ETL/ELT-pipelines voor het extraheren, transformeren en laden van informatie, met moderne platforms die realtime streaming en AI-gestuurde dataverwerking ondersteunen.
Metadata-repository: Uitgebreide documentatie met technische specificaties, zakelijke context en operationele metadata, die steeds verder wordt aangevuld met AI voor geautomatiseerde classificatie en ontdekking.
Hulpmiddelen voor gegevenstoegang: query-interfaces, OLAP-systemen, visualisatieplatforms en AI/ML-mogelijkheden die informatie toegankelijk maken voor verschillende gebruikersprofielen en analytische toepassingen.