
Summarize this blog post with:
- Which Databricks use cases for enterprises deliver the fastest, most measurable ROI
- How the Databricks Data Intelligence Platform architecture handles streaming, batch, and AI workloads within a single stack
- Why governance (and not just compute), is the gating factor for most Databricks AI use cases in regulated industries
Only about 48% of AI projects make it from prototype to production.
Not because the models are bad. Because the data infrastructure underneath them was never built to support them.
The Databricks Data Intelligence Platform has emerged as the architecture of choice for enterprises trying to close that gap. It is built to handle what fragmented toolchains cannot: batch and streaming in the same environment, governance and compute on the same platform, and AI workloads running on top of the same data layer that powers day-to-day operations.
But the platform does not deliver outcomes by itself. The enterprises that extract real value from Databricks data intelligence are the ones that implement it with architectural discipline — understanding which use cases it is genuinely suited for, what the real failure modes look like, and what governance decisions must be made before a single pipeline runs.
The timing is not coincidental. Three forces are converging simultaneously across enterprise data organisations.
- The volume and variety of data that organisations need to process has outpaced what traditional warehouse architectures were designed to handle.
- AI and machine learning initiatives have moved from experimental to board-level priorities. It creates pressure to build infrastructure that can support them in production.
- Regulatory scrutiny around data access, lineage, and AI model governance has made ungoverned data environments a legal and reputational liability, not just a technical inconvenience.
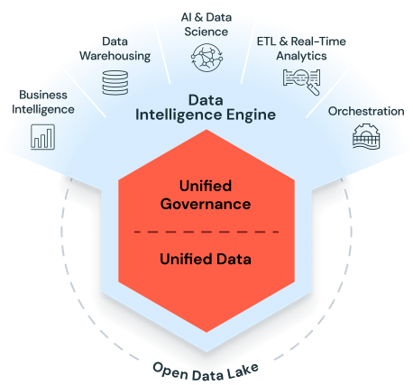 Source: The Databricks Data Intelligence Platform
Source: The Databricks Data Intelligence Platform
Do You Know?
Enterprises that delay modernisation are not standing still — they are falling behind organisations that are already compounding the advantages of unified data infrastructure.
The Databricks Data Intelligence Platform architecture addresses all three of these pressures within a single stack. The Lakehouse model eliminates the structural separation between data lakes and data warehouses. Unity Catalog provides unified governance across data, analytics, and AI assets. And the platform's compute layer — when configured correctly — scales to handle everything from historical batch processing to millisecond IoT streaming. The use cases below illustrate what this looks like when applied to real enterprise problems.
Explore the migration patterns that separate successful Unity Catalog deployments from failed ones!
See the Success Patterns
When people talk about modernisation, they're almost always comparing it to a 'lift-and-shift' alternative. That's where they miss the mark.
The most prevalent and immediately high-impact Databricks use case for enterprises is collapsing fragmented data infrastructure into a single, governed Lakehouse. Most large organisations are not operating one data platform — they are operating several: a legacy on-premises warehouse, a cloud object store used as an ad-hoc data lake, a separate analytics environment, and a disconnected ML workspace. Each of these was built to solve a specific problem at a specific point in time. Together, they create reporting latency, data inconsistency, and an engineering team that spends more time on maintenance than on value creation.
The Databricks Data Intelligence Platform architecture resolves this through the medallion architecture — a layered approach that structures data into:
- bronze (raw ingestion),
- silver (cleansed and validated),
- and gold (aggregated, business-ready) zones.
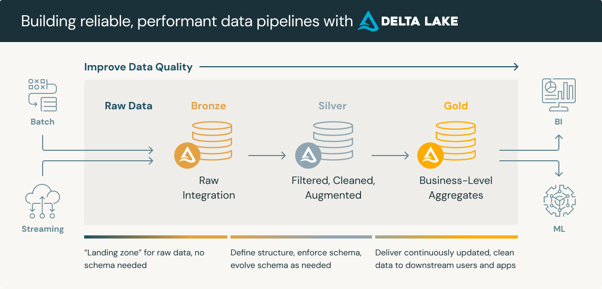 Source: Databricks
Source: Databricks
Delta Lake sits underneath all three layers, providing ACID transactions, schema enforcement, and time-travel capabilities that traditional data lakes cannot offer. The result is a single source of truth that serves both operational reporting and AI workloads without duplication or reconciliation overhead.
The most common failure mode in this use case is computing cost management. Enterprises moving to Databricks for the first time frequently underestimate the cost exposure created by interactive, all-purpose compute clusters left running without auto-termination policies. The fix is architectural, not reactive: standardising on job clusters for automated workloads, enforcing auto-termination at the infrastructure-as-code level using Terraform, and treating cluster governance as a financial control from Day 1 rather than a configuration detail addressed after costs spike.
Explore what a full data estate modernisation actually involves → Migrate and Modernise Your Data Estate
See What's Included
Real-time streaming is where the Databricks Data Intelligence Platform architecture most visibly separates itself from legacy approaches — and where the consequences of getting the implementation wrong are most immediately felt. For manufacturing, logistics, utilities, and any industry dependent on physical operations, the ability to act on data in motion rather than data at rest is not a technical preference. It is the difference between preventing a failure and responding to one.
Predictive maintenance enabled by real-time data processing can reduce machine downtime by 30 to 50% and extend equipment life by 20 to 40%. The bottleneck in most organisations is not sensor data availability. It is pipeline latency!
The core architectural challenge in industrial IoT deployments is the coexistence of fundamentally different data types: high-frequency sensor streams measured in milliseconds, and slow ERP or MES batch records updated daily or hourly. Legacy ETL systems were built for one or the other. The Databricks Data Intelligence Platform is designed to handle both simultaneously — but the implementation approach determines whether that potential is realised.
The critical decision point is between manual PySpark structured streaming and Delta Live Tables (DLT). Manual streaming jobs require engineers to explicitly define and maintain every failure mode — checkpoint management, state recovery, schema evolution handling. At scale, with multiple concurrent sensor feeds, that becomes a fragile and expensive maintenance liability. Delta Live Tables shifts this burden to the platform itself. Engineers declare the target state of the data; DLT manages dependency resolution, error handling, retries, and state checkpointing automatically.
See how 1Platform runs natively on the Databricks Data Intelligence Platform
See It in Action
Organisations using declarative pipeline frameworks report up to a 60% reduction in pipeline maintenance overhead compared to those operating hand-coded streaming jobs . The engineering time recovered translates directly into faster iteration on the analytics and AI layers above.
The practical outcome of a well-implemented DLT architecture in industrial settings is a data pipeline that can ingest high-frequency sensor data, join it with contextual ERP records, and surface actionable predictive maintenance signals — all within sub-minute latency. The operational shift this enables is significant: from reactive incident response to proactive intervention, before fAIlure occurs rather than after.
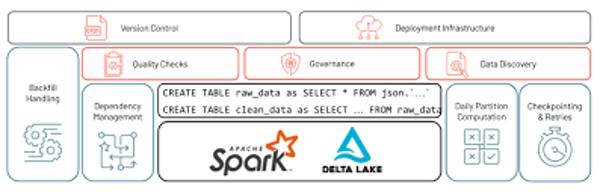 Source: Databricks
Source: Databricks
See how modernisation extends well beyond the migration milestone → What Comes After Data Migration?
Discover the Next Phase
Generative AI on proprietary enterprise data is the highest-ceiling and highest-risk category of Databricks AI use cases. The commercial opportunity is real: natural language querying of unstructured documents, AI-assisted compliance review, contract intelligence, and analyst co-pilots that eliminate the SQL dependency for business users. But in regulated industries — financial services, pharmaceuticals, healthcare, insurance — the path from prototype to production runs directly through a governance checkpoint that most organisations are not prepared for when they arrive at it.
The pattern is consistent. An enterprise builds a technically sound generative AI application using the Databricks Data Intelligence Engine — fine-tuning a large language model on proprietary documentation, integrating retrieval-augmented generation against internal knowledge bases. Then the CISO, the legal team, or the compliance function asks a straightforward question: can you show us exactly which data the model trained on, who had access to it, and what controls were in place? Without a structured answer, the project halts.
Did You Know?
- KPMG research shows 62% of organisations identify lack of data governance as the primary challenge inhibiting AI initiatives.
KPMG,2025
- A 2024 IBM survey found that only 24% of AI projects currently in use are governed by the organisation deploying them
IBM, 2024
The governance gap is the defining obstacle between AI experimentation and AI at scale.
The architectural resolution is Unity Catalog — Databricks' unified governance layer for data, analytics, and AI assets. Unity Catalog provides row-level and column-level access controls, complete data lineage from raw source to model input, attribute-based access policies, and a single governance interface that spans structured data, unstructured documents, ML models, and notebooks. Critically, it is not a post-deployment addition — it must be the first production resource provisioned, before pipelines are built or models are trained. Retrofitting it is significantly harder than architecting it from the start.
Across these use cases, three architectural principles consistently determine whether a Databricks implementation reaches sustainable production or accumulates technical debt.
- Compute governance from Day 1, not Day 60.
The Databricks Data Intelligence Platform's elasticity is an asset when managed deliberately. Without auto-termination policies, cluster standardisation, and infrastructure-as-code enforcement from the start, compute costs become the first crisis an enterprise faces — usually within the first two months.
- Declarative pipelines over manual orchestration.
The move from hand-coded PySpark streaming to Delta Live Tables is not a tooling preference — it is an architectural decision that changes the failure surface. Manual orchestration places the entire burden of reliability on the engineering team. Declarative pipelines place it on the platform. At scale, that difference translates into faster mean time to recovery, lower on-call load, and pipelines that degrade gracefully rather than catastrophically.
- Unity Catalog as foundation, not finish.
Every enterprise that deploys Unity Catalog as a final step — after pipelines are operational and models are training — encounters a forcing function that resets it as the priority. Governance is not a layer added on top of a working system. It is the substrate that makes a working system trustworthy enough to deploy in production.
These are not observations from isolated projects. They are patterns that repeat across Databricks data intelligence platform architectures built at scale, across industries, under real production constraints.
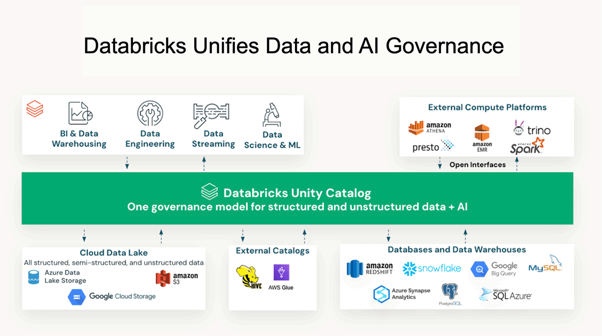 Source: Databricks Unity Catalog governance value levers
Source: Databricks Unity Catalog governance value levers
The Databricks data intelligence platform is not a technology bet on the future. It is a production-grade architecture that enterprises across industries are running today — for Lakehouse consolidation, real-time streaming, and governed generative AI. The use cases are proven. The outcomes are documented. The failure modes are well understood.
What remains variable is the implementation.
The enterprises that extract the most from Databricks data intelligence are rarely the ones with the biggest budgets or the most aggressive AI roadmaps. They are the ones that made the right architectural decisions early: governed their compute before it governed their budget, chose declarative pipelines before manual orchestration became a liability, and provisioned Unity Catalog before a compliance question forced them back to the start.
If you are evaluating where your organisation sits relative to these use cases — whether you are scoping a first migration, trying to stabilise a streaming architecture that has hit its ceiling, or working through a governance gap that is blocking an AI initiative — these are common points in the journey. Most enterprises arrive at one of them before they find the right path forward.
The question worth asking is not whether the Databricks Data Intelligence Platform can solve your problem. In most cases, it can. The more useful question is whether your current approach — your architecture, your governance model, your implementation sequencing — is set up to let it.
If that question does not have a clear answer yet, it is worth a conversation with someone who has navigated these decisions across multiple production environments.