
Sammanfatta detta blogginlägg med:
- Vilka Databricks-användningsfall för företag ger den snabbaste och mest mätbara avkastningen på investeringen (ROI)
- Hur Databricks Data Intelligence Platform-arkitektur hanterar strömmande, batch- och AI-arbetsbelastningar i en enda stack
- Varför styrning (och inte bara beräkning) är den avgörande faktorn för de flesta Databricks AI-användningsfall i reglerade branscher
Endast cirka 48 % av AI-projekt går från prototyp till produktion.
Inte för att modellerna är dåliga. För att datainfrastrukturen under dem aldrig byggdes för att stödja dem.
Databricks Data Intelligence Platform har framstått som den självklara arkitekturen för företag som försöker överbrygga den klyftan. Den är byggd för att hantera det som fragmenterade verktygskedjor inte kan: batch och streaming i samma miljö, styrning och beräkning på samma plattform, och AI-arbetsbelastningar som körs ovanpå samma datalager som driver den dagliga verksamheten.
Men plattformen levererar inte resultat av sig själv. De företag som utvinner verkligt värde från Databricks dataintelligens är de som implementerar den med arkitektonisk disciplin – att förstå vilka användningsfall den verkligen är lämpad för, hur de verkliga fellägena ser ut och vilka styrningsbeslut som måste fattas innan en enskild pipeline körs.
Tidpunkten är inte en slump. Tre krafter samverkar samtidigt inom företag som arbetar med datahantering.
- Volymen och variationen av data som organisationer behöver bearbeta har överträffat vad traditionella lagerarkitekturer utformades för att hantera.
- AI- och maskininlärningsinitiativ har gått från experimentella till styrelseprioriteringar. Det skapar press att bygga infrastruktur som kan stödja dem i produktionen.
- Myndighetsgranskning kring dataåtkomst, härkomst och styrning av AI-modeller har gjort ostyrda datamiljöer till ett juridiskt och anseendemässigt ansvar, inte bara ett tekniskt problem.
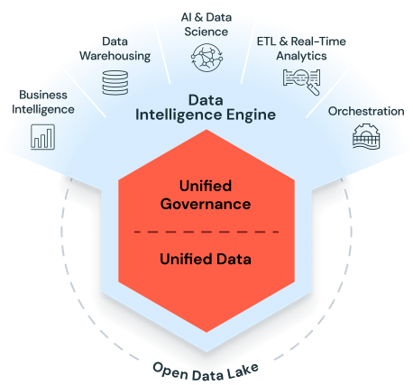 Källa: Databricks Data Intelligence Platform
Källa: Databricks Data Intelligence Platform Vet du?
Företag som skjuter upp moderniseringen står inte stilla – de halkar efter organisationer som redan förstärker fördelarna med enhetlig datainfrastruktur.
Databricks Data Intelligence Platform-arkitektur hanterar alla dessa tre påfrestningar inom en enda stack. Lakehouse-modellen eliminerar den strukturella separationen mellan datasjöar och datalager. Unity Catalog tillhandahåller enhetlig styrning av data, analys och AI-tillgångar. Och plattformens beräkningslager – när det är korrekt konfigurerat – skalar för att hantera allt från historisk batchbehandling till millisekunds IoT-strömning. Användningsfallen nedan illustrerar hur detta ser ut när det tillämpas på verkliga företagsproblem.
Utforska migreringsmönstren som skiljer lyckade Unity Catalog-distributioner från misslyckade!
Se framgångsmönstren När folk pratar om modernisering jämför de det nästan alltid med ett "lyft-och-flytt"-alternativ. Det är där de missar målet.
Det vanligaste och mest omedelbart påverkande användningsfallet för Databricks för företag är att dela upp fragmenterad datainfrastruktur till ett enda, styrt Lakehouse. De flesta stora organisationer driver inte en dataplattform – de driver flera: ett äldre lokalt lager, ett molnobjektlager som används som en ad hoc-datasjö, en separat analysmiljö och en frånkopplad ML-arbetsyta. Var och en av dessa byggdes för att lösa ett specifikt problem vid en specifik tidpunkt. Tillsammans skapar de rapporteringsfördröjning, datainkonsekvens och ett teknikteam som lägger mer tid på underhåll än på värdeskapande.
Databricks Data Intelligence Platform-arkitektur löser detta genom medallion-arkitekturen – en lagerbaserad metod som strukturerar data i:
- brons (rå intag),
- silver (renat och validerat),
- och guldzoner (aggregerade, företagsklara).
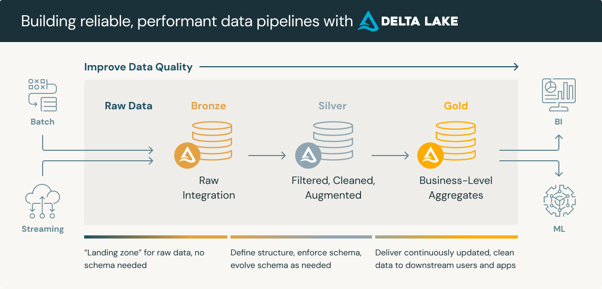 Källa: Databricks
Källa: Databricks Delta Lake ligger under alla tre lager och tillhandahåller ACID-transaktioner, schematillämpning och tidsresefunktioner som traditionella datasjöar inte kan erbjuda. Resultatet är en enda sanningskälla som hanterar både operativ rapportering och AI-arbetsbelastningar utan dubbelarbete eller avstämningskostnader.
Det vanligaste felläget i detta användningsfall är kostnadshantering för beräkningar. Företag som övergår till Databricks för första gången underskattar ofta kostnadsexponeringen som skapas av interaktiva, allsidiga beräkningskluster som körs utan policyer för automatisk avslutning. Lösningen är arkitektonisk, inte reaktiv: standardisering av jobbkluster för automatiserade arbetsbelastningar, tillämpning av automatisk avslutning på infrastruktur-som-kod-nivå med hjälp avTerraform och behandling av klusterstyrning som en ekonomisk kontroll från dag 1 snarare än en konfigurationsdetalj som åtgärdas efter kostnadsökningar.
Utforska vad en fullständig modernisering av datatillgångar egentligen innebär → Migrera och modernisera din datatillgång
Se vad som ingår Realtidsströmning är där Databricks Data Intelligence Platform-arkitektur tydligast skiljer sig från äldre metoder – och där konsekvenserna av att implementera fel märks mest omedelbart. För tillverkning, logistik, energibolag och alla branscher som är beroende av fysisk verksamhet är möjligheten att agera på data i rörelse snarare än data i vila inte en teknisk preferens. Det är skillnaden mellan att förhindra ett fel och att reagera på ett.
Förutsägande underhåll som möjliggörs av realtidsdatabehandling kan minska maskinernas driftstopp med 30 till 50 % och förlänga utrustningens livslängd med 20 till 40 %. Flaskhalsen i de flesta organisationer är inte tillgängligheten av sensordata. Det är pipeline-latens!
Den centrala arkitektoniska utmaningen i industriella IoT-implementeringar är samexistensen av fundamentalt olika datatyper: högfrekventa sensorströmmar mätta i millisekunder, och långsamma ERP- eller MES-batchposter som uppdateras dagligen eller varje timme. Äldre ETL-system byggdes för det ena eller det andra. Databricks Data Intelligence Platform är utformad för att hantera båda samtidigt – men implementeringsmetoden avgör om den potentialen realiseras.
Den kritiska beslutspunkten är mellan manuell PySpark-strukturerad strömning och Delta Live Tables (DLT) . Manuella strömningsjobb kräver att ingenjörer explicit definierar och underhåller varje felläge – kontrollpunktshantering, tillståndsåterställning, hantering av schemautveckling. I stor skala, med flera samtidiga sensorflöden, blir det en ömtålig och dyr underhållsbelastning. Delta Live Tables flyttar denna börda till själva plattformen. Ingenjörer deklarerar måltillståndet för data; DLT hanterar beroendelösning, felhantering, återförsök och tillståndskontrollpunkter automatiskt.
Se hur 1Platform körs direkt på Databricks Data Intelligence Platform
Se det i aktion Organisationer som använder deklarativa pipeline-ramverk rapporterar upp till 60 % minskning av pipeline-underhållskostnader jämfört med de som använder handkodade strömmande jobb. Den återvunna ingenjörstiden leder direkt till snabbare iteration på analys- och AI-lagren ovan.
Det praktiska resultatet av en väl implementerad DLT-arkitektur i industriella miljöer är en datapipeline som kan ta emot högfrekventa sensordata, koppla den till kontextuella ERP-poster och generera handlingsbara prediktiva underhållssignaler – allt inom en latens på under en minut. Den operativa förändring som detta möjliggör är betydande: från reaktiv incidentrespons till proaktiv intervention, innan ett fel inträffar snarare än efter.
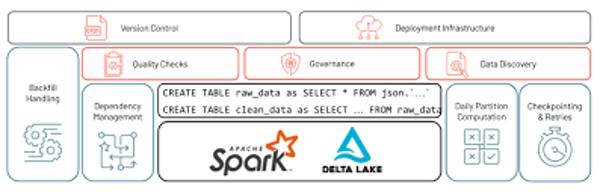 Källa: Databricks
Källa: Databricks Se hur moderniseringen sträcker sig långt bortom migreringsmilstolpen → Vad kommer efter datamigrering?
Upptäck nästa fas Generativ AI på proprietär företagsdata är den kategori med högst begränsning och högst risk bland Databricks AI-användningsfall. Den kommersiella möjligheten är verklig: naturligt språkbaserade frågor om ostrukturerade dokument, AI-assisterad efterlevnadsgranskning, kontraktsinformation och analytiker som eliminerar SQL-beroendet för företagsanvändare. Men inom reglerade branscher – finansiella tjänster, läkemedel, sjukvård, försäkringar – går vägen från prototyp till produktion direkt genom en styrningskontrollpunkt som de flesta organisationer inte är förberedda på när de väl anländer till den.
Mönstret är konsekvent. Ett företag bygger en tekniskt sund generativ AI-applikation med hjälp av Databricks Data Intelligence Engine – finjusterar en stor språkmodell på proprietär dokumentation och integrerar hämtningsförstärkt generering mot interna kunskapsbaser. Sedan ställer CISO:n, det juridiska teamet eller compliance-funktionen en enkel fråga: kan ni visa oss exakt vilka data modellen tränade på, vem som hade tillgång till dem och vilka kontroller som fanns på plats? Utan ett strukturerat svar stannar projektet av.
Visste du?
- KPMG-undersökning visar att 62 % av organisationerna identifierar bristande datastyrning som den främsta utmaningen som hämmar AI-initiativ. KPMG, 2025
- En IBM-undersökning från 2024 visade att endast 24 % av de AI-projekt som för närvarande används styrs av den organisation som driftsätter dem . IBM, 2024
Styrningsgapet är det avgörande hindret mellan AI-experiment och AI i stor skala.
Den arkitektoniska lösningen är Unity Catalog – Databricks enhetliga styrningslager för data, analys och AI-tillgångar. Unity Catalog tillhandahåller åtkomstkontroller på rad- och kolumnnivå, komplett datalinje från råkälla till modellinmatning, attributbaserade åtkomstpolicyer och ett enda styrningsgränssnitt som omfattar strukturerad data, ostrukturerade dokument, ML-modeller och anteckningsböcker. Avgörande är att det inte är ett tillägg efter distribution – det måste vara den första produktionsresursen som provisioneras, innan pipelines byggs eller modeller tränas. Att eftermontera det är betydligt svårare än att arkitekturera det från början.
I dessa användningsfall avgör tre arkitekturprinciper konsekvent om en Databricks-implementering når hållbar produktion eller ackumulerar teknisk skuld.
- Beräkningsstyrning från dag 1, inte dag 60.
Databricks Data Intelligence Platforms elasticitet är en tillgång när den hanteras medvetet. Utan policyer för automatisk avslutning, klusterstandardisering och tillämpning av infrastruktur som kod från börjanblir beräkningskostnader den första krisen ett företag står inför – vanligtvis inom de första två månaderna.
- Deklarativa pipelines framför manuell orkestrering.
Övergången från handkodad PySpark-strömning till Delta Live Tables är inte en verktygspreferens – det är ett arkitekturbeslut som förändrar felytan. Manuell orkestrering lägger hela bördan av tillförlitlighet på ingenjörsteamet. Deklarativa pipelines placerar den på plattformen. I stor skala innebär den skillnaden snabbare medeltid till återställning, lägre jourbelastning och pipelines som degraderas smidigt snarare än katastrofalt.
- Unity Catalog som grund, inte målgång.
Varje företag som driftsätter Unity Catalog som ett sista steg – efter att pipelines är i drift och modeller tränas – stöter på en tvångsfunktion som återställer den till prioritet. Styrning är inte ett lager som läggs ovanpå ett fungerande system. Det är substratet som gör ett fungerande system tillräckligt pålitligt för att driftsättas i produktion.
Detta är inte observationer från isolerade projekt. Det är mönster som upprepas i Databricks arkitekturer för dataintelligensplattformar, byggda i stor skala, över olika branscher och under verkliga produktionsbegränsningar.
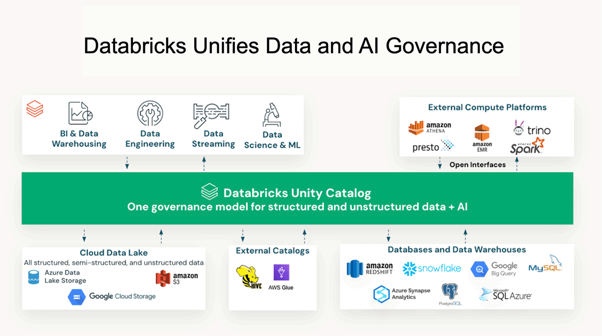 Källa: Databricks Unity Catalog styrningsvärdeshävstång
Källa: Databricks Unity Catalog styrningsvärdeshävstång
Databricks dataintelligensplattform är inte en teknologisk satsning på framtiden. Det är en produktionsklassad arkitektur som företag inom olika branscher använder idag – för Lakehouse-konsolidering, realtidsströmning och styrd generativ AI. Användningsfallen är beprövade. Resultaten är dokumenterade. Fellägena är väl förstådda.
Det som förblir variabelt är implementeringen.
De företag som får ut mest av Databricks dataintelligens är sällan de med de största budgetarna eller de mest aggressiva AI-färdplanerna. Det är de som fattade rätt arkitekturbeslut tidigt: styrde sin beräkning innan den styrde deras budget, valde deklarativa pipelines innan manuell orkestrering blev en belastning och provisionerade Unity Catalog innan en efterlevnadsfråga tvingade dem tillbaka till början.
Om du utvärderar var din organisation befinner sig i förhållande till dessa användningsfall – oavsett om du planerar en första migrering, försöker stabilisera en streamingarkitektur som har nått sitt gränsfall eller arbetar dig igenom ett styrningsgap som blockerar ett AI-initiativ – är detta vanliga punkter på resans gång. De flesta företag når en av dem innan de hittar rätt väg framåt.
Frågan som är värd att ställa sig är inte om Databricks Data Intelligence Platform kan lösa ditt problem. I de flesta fall kan den det. Den mer användbara frågan är om er nuvarande strategi – er arkitektur, er styrningsmodell, er implementeringssekvensering – är utformad för att tillåta det.
Om den frågan inte har ett tydligt svar ännu är det värt ett samtal med någon som har navigerat dessa beslut i flera produktionsmiljöer.