
Vat dit blogbericht samen met:
Noot van de redactie: Naarmate de wereld van cloud-datawarehouses zich blijft ontwikkelen, kunnen er innovaties en veranderingen ontstaan. In deze blog hebben we de transformerende mogelijkheden van de beste cloud-datawarehouse-oplossingen onderzocht: Amazon Redshift, Google BigQuery, Snowflake en het Azure Data Platform. Deze technologieën vormen de pijlers van cloudgebaseerde datawarehousing en bieden elk unieke sterke punten en functionaliteiten die inspelen op uiteenlopende zakelijke behoeften.
Invoering
Data is tegenwoordig de meest cruciale hulpbron voor elk bedrijf. Een algemene verschuiving in het bedrijfsmodel door de jaren heen heeft aangetoond dat opslag en rekenkracht een steeds belangrijkere rol spelen in de omvang en intensiteit van de bedrijfsmodules.
Als we het over opslag hebben, kennen we allemaal het concept van datawarehousing. Dit biedt bedrijven de mogelijkheid om data te analyseren en te filteren, zodat ze waardevolle inzichten kunnen opdoen en weloverwogen zakelijke beslissingen kunnen nemen.
Een datawarehouse fungeert tevens als centrale opslagplaats voor alle gegevens die een onderneming verzamelt via diverse interne en externe bronnen. Het helpt bij rapportage en data-analyse.
Omdat het datawarehouse gegevens verwerkt die afkomstig zijn van verschillende bronnen en media, waaronder relationele databases, NoSQL-databases en API's van derden, is de hoeveelheid onduidelijke gegevens uitzonderlijk hoog. Daarom moeten alle verzamelde gegevens worden gecombineerd tot één samenhangende dataset en geoptimaliseerd om snelle oplossingen te bieden voor cruciale databasequery's.
Een moderne aanpak voor cloudmigratiestrategie: de 6 R's
Voorheen was het datawarehouse alleen beschikbaar als on-premise oplossing, die meestal applicatiegebaseerd is, waardoor het lastig was om datawarehouses uit te breiden.
Gezien de behoeften van de markt, presenteren we hier een aantal robuuste datawarehouse-platformen .

Amazon Redshift is een datawarehouseproduct dat deel uitmaakt van het grotere cloudcomputingplatform Amazon Web Services . Het is een eenvoudige en kosteneffectieve datawarehouseoplossing die alle gebruikersgegevens analyseert in hun on-premise datawarehouses en data lakes.
Amazon Redshift is in staat om tot tien keer snellere prestaties te leveren dan traditionele oplossingen en benut de kracht van machine learning, massaal parallelle query-uitvoering en kolomopslag op een krachtige schijf. Gebruikers kunnen in enkele minuten eenvoudig een nieuw datawarehouse opzetten en implementeren, en query's uitvoeren op petabytes aan data in het Redshift-datawarehouse en exabytes aan data in hun data lake, gebouwd op Amazon S3.
Laten we nu eens kijken naar de architectuur van Amazon Redshift . In dit gedeelte worden de componenten van de AWS Redshift-architectuur belicht, zodat u voldoende aanknopingspunten krijgt om te bepalen of deze geschikt is voor uw specifieke toepassing. Hieronder vindt u een diagram van de Redshift-architectuur:
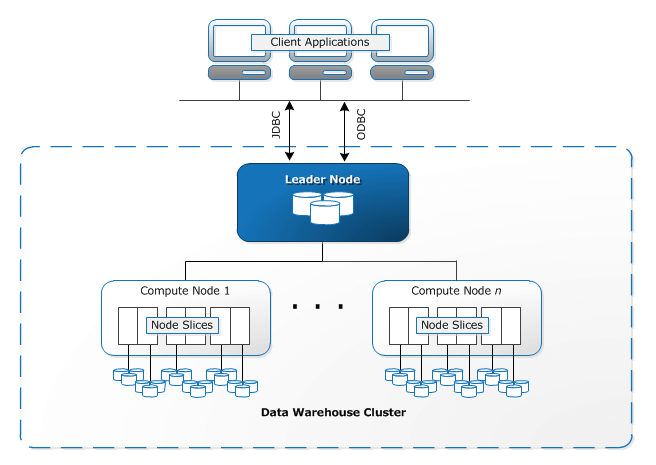
Redshift-cluster: Redshift gebruikt een cluster van knooppunten als de kern van de infrastructuur. Een cluster bestaat meestal uit één hoofdknooppunt (leader node) en meerdere rekenknooppunten (compute nodes). In gevallen waarin er slechts één rekenknooppunt is, is er geen extra hoofdknooppunt.
Rekenknooppunten: Elk rekenknooppunt heeft zijn eigen CPU, geheugen en opslagschijf. Clienttoepassingen merken het bestaan van rekenknooppunten niet op en hoeven er nooit rechtstreeks mee te communiceren.
Hoofdknooppunt: Het hoofdknooppunt is verantwoordelijk voor alle communicatie met clientapplicaties. Het hoofdknooppunt beheert ook de coördinatie van de rekenknooppunten. Het parseren van query's en het ontwikkelen van uitvoeringsplannen behoren eveneens tot de verantwoordelijkheden van het hoofdknooppunt. Bij ontvangst van een query maakt het hoofdknooppunt het uitvoeringsplan aan en wijst de gecompileerde code toe aan de rekenknooppunten. Een deel van de data wordt aan elk rekenknooppunt toegewezen. De uiteindelijke aggregatie van de resultaten wordt door het hoofdknooppunt uitgevoerd.
Functies
Massaal parallel
Amazon Redshift levert snelle queryprestaties op datasets van gigabytes tot exabytes. Redshift maakt gebruik van kolomopslag, datacompressie en zone-mapping om de hoeveelheid I/O die nodig is voor query's te verminderen. Het maakt gebruik van massively parallel processing (MPP) datawarehouse-architectuur om SQL-bewerkingen te paralleliseren en te verdelen, zodat alle beschikbare resources optimaal worden benut. De onderliggende hardware is ontworpen voor hoogwaardige dataverwerking , waarbij lokaal aangesloten opslag de doorvoer tussen de CPU's en schijven maximaliseert en een mesh-netwerk met hoge bandbreedte de doorvoer tussen knooppunten maximaliseert.
Machine learning
Amazon Redshift gebruikt machine learning om een hoge doorvoer te garanderen, ongeacht de werklast of het gelijktijdige gebruik. Het maakt gebruik van geavanceerde algoritmen om de verwachte uitvoertijd van binnenkomende query's te voorspellen en wijst deze toe aan de optimale wachtrij voor de snelste verwerking. Zo worden query's zoals dashboards en rapporten met een hoge gelijktijdigheidsvereiste naar een express-wachtrij geleid voor onmiddellijke verwerking.
Geautomatiseerde inrichting
Amazon Redshift is eenvoudig in te stellen en te beheren. U kunt een nieuw datawarehouse met slechts een paar klikken implementeren in AWS Management Redshift, waarna de console automatisch de infrastructuur voor gebruikers configureert. De meeste complexe taken, zoals back-ups en replicatie, worden geautomatiseerd, zodat u zich kunt concentreren op uw data in plaats van op het beheer. Redshift biedt opties waarmee u de controle over uw specifieke workloads kunt behouden. Nieuwe functionaliteiten worden transparant uitgebracht, waardoor het niet nodig is om upgrades en patches in te plannen en toe te passen.
Fouttolerant
Amazon Redshift beschikt over diverse functies die de betrouwbaarheid van uw datawarehousecluster verhogen. Redshift bewaakt continu de status van het cluster, repliceert automatisch gegevens van defecte schijven en vervangt knooppunten indien nodig voor fouttolerantie.
Flexibele zoekopdrachten
Amazon Redshift biedt u de flexibiliteit om query's uit te voeren in de console of om verbinding te maken met SQL-clienttools, bibliotheken of Business Intelligence-tools die u gebruikt. De Query Editor in de AWS-console biedt een krachtige interface voor het uitvoeren van SQL-query's op Redshift-clusters en het bekijken van de queryresultaten en het uitvoeringsplan (voor query's die op rekenknooppunten worden uitgevoerd) naast uw query's.
Lijst met enkele tevreden Amazon Redshift-klanten
- Yelp
- Duolingo
- Comcast
- Equinox
- Dow Jones

Google BigQuery is een cloudgebaseerd datawarehouse van enterprise-kwaliteit. Het werd voor het eerst gelanceerd als een service in 2010 en was vanaf november 2011 algemeen beschikbaar. Sinds de introductie is BigQuery uitgegroeid tot een voordeliger en volledig beheerd datawarehouse dat razendsnelle interactieve en ad-hoc query's kan uitvoeren op datasets van petabyte-formaat. Bovendien integreert BigQuery nu met diverse Google Cloud Platform (GCP)-services en tools van derden, waardoor het nog nuttiger is geworden.
BigQuery is serverloos, of preciezer gezegd, een datawarehouse als een service . Er zijn geen servers om te beheren of databasesoftware om te installeren. De BigQuery-service beheert de onderliggende software en infrastructuur, inclusief schaalbaarheid en hoge beschikbaarheid. BigQuery biedt een eenvoudige clientinterface waarmee gebruikers interactieve query's kunnen uitvoeren. Het beschikt ook over ingebouwde mogelijkheden voor machine learning.
Laten we nu eens dieper ingaan op de architectuur van Google BigQuery.
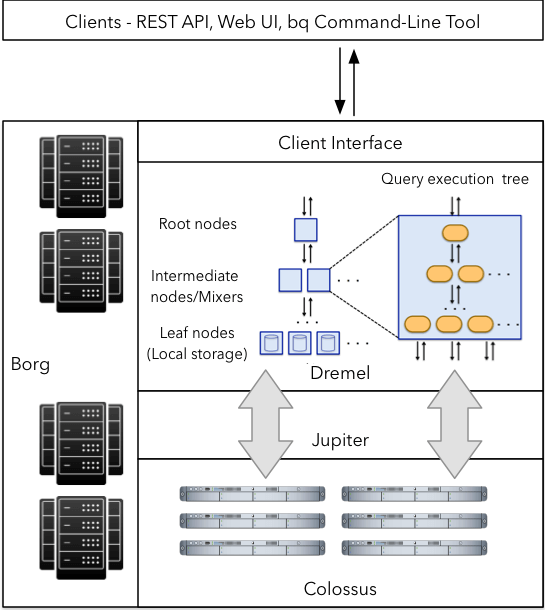
Dremel: Dremel is de query-uitvoeringsengine die BigQuery aandrijft. Het is een zeer schaalbaar systeem dat is ontworpen om query's uit te voeren op datasets van petabytes. Dremel gebruikt een combinatie van kolomgeoriënteerde datastructuren en een boomstructuur om binnenkomende queryverzoeken te verwerken. Deze combinatie stelt Dremel in staat om triljoenen rijen in seconden te verwerken. In tegenstelling tot veel database-architecturen is Dremel in staat om rekenknooppunten onafhankelijk van elkaar op te schalen om te voldoen aan de eisen van zelfs de meest veeleisende query's.
Colossus: Colossus is het gedistribueerde bestandssysteem dat Google gebruikt voor veel van zijn producten. In elk datacenter van Google draait een cluster van opslagschijven die opslagcapaciteit bieden voor de verschillende diensten. Colossus zorgt ervoor dat er geen gegevensverlies optreedt op de schijven door de juiste replicatie- en noodherstelstrategieën te kiezen.
Jupiter Network: Het Jupiter Network vormt de brug tussen de Colossus-opslag en de Dremel-uitvoeringsengine. De netwerkmogelijkheden in de datacenters van Google bieden ongekende niveaus van bidirectioneel verkeer, waardoor grote hoeveelheden data tussen Dremel en Colossus kunnen worden verplaatst.
Functies
BigQuery ML
Dit helpt experts zoals analisten en wetenschappers bij het bouwen en beheren van machine learning-modellen op verschillende datastructuren met behulp van eenvoudige SQL. Vervolgens kunnen de modellen worden geëxporteerd naar AI-platformen voor verdere voorspellingen en andere bewerkingen.
BigQuery BI-engine
Een van de beste eigenschappen van BigQuery is de snelheid. Het is erg snel, waardoor gebruikers zelfs de meest complexe datagroepen in slechts enkele seconden kunnen analyseren, en dat ook nog eens met een hoge mate van nauwkeurigheid. De BI Engine van BigQuery maakt ook integratie met verschillende tools zoals Data Studio mogelijk en helpt experts bij diverse data-analyses en -verkenningen.
Geografische analyse met BigQuery GIS
BigQuery GIS combineert specifiek de serverloze architectuur van BigQuery met native ondersteuning voor geospatiale analyses, waardoor analyseworkflows kunnen worden verrijkt met locatie-intelligentie. Vereenvoudig uw analyses, bekijk ruimtelijke data op nieuwe manieren en ontdek geheel nieuwe zakelijke mogelijkheden met ondersteuning voor willekeurige punten, polygonen, lijnen en multi-polygonen in standaard geospatiale dataformaten.
Machine learning en voorspellende modellen met BigQuery ML
BigQuery ML stelt data-analisten en datawetenschappers in staat om machine learning-modellen te bouwen en te implementeren op wereldwijde, semi-gestructureerde of gestructureerde data, rechtstreeks binnen BigQuery, met behulp van eenvoudige SQL – in een fractie van de tijd. Gebruikers kunnen BigQuery ML-modellen exporteren voor online voorspellingen naar Vertex AI of hun serverlaag met deze functie.
Multicloud-data-analyse met BigQuery Omni
BigQuery Omni is een flexibele, volledig beheerde, multi-cloud analyseoplossing waarmee gebruikers op een veilige en kostenefficiënte manier data kunnen analyseren in clouds zoals Azure en AWS. Met behulp van standaard SQL en de vertrouwde interface van BigQuery kunnen gebruikers snel vragen beantwoorden en resultaten delen vanuit één overzichtelijk dashboard voor al hun datasets.
Verbonden vellen
Gebruikers zonder SQL-kennis kunnen toch grote hoeveelheden data analyseren met behulp van gekoppelde spreadsheets in BigQuery. Diverse tools, zoals grafieken, draaitabellen en vele andere, kunnen worden gebruikt om inzichten uit de data te halen.
Naast deze vele functies is het datawarehouse uitgerust met nog veel meer mogelijkheden, zoals realtime analyses, logische dataopslag, gematerialiseerde weergaven, automatische back-up, datatransferservices, flexibele kostenmodellen, hoge beveiliging, programmatische interactie en nog veel meer.
Enkele prominente klanten van Google BigQuery
- UPS
- Twitter
- De Home Depot
- Dow Jones

Snowflake Inc. is een cloudgebaseerde datawarehouse-startup die in 2012 is opgericht. Snowflake biedt een cloudgebaseerde dienst voor dataopslag en -analyse, over het algemeen aangeduid als "datawarehouse as a service". Hiermee kunnen zakelijke gebruikers data opslaan en analyseren met behulp van cloudgebaseerde hardware en software.
Het Snowflake-datawarehouse maakt gebruik van een nieuwe SQL-database-engine met een unieke architectuur die speciaal voor de cloud is ontworpen. Snowflake vertoont veel overeenkomsten met andere enterprise-datawarehouses, maar biedt daarnaast extra functionaliteit en unieke mogelijkheden.
Laten we eens kennismaken met Snowflake Architecture .
De unieke architectuur van Snowflake bestaat uit drie essentiële lagen:
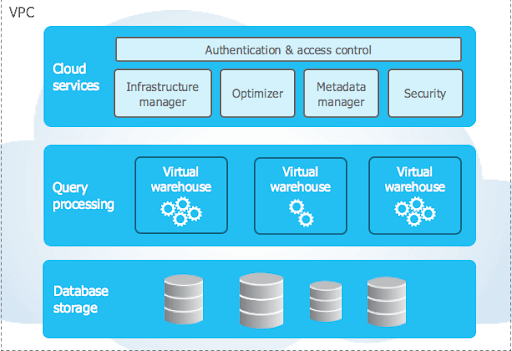
- Databaseopslag
- Queryverwerking
- Cloudservices
Databaseopslag
Wanneer gegevens in Snowflake worden geladen, reorganiseert Snowflake deze gegevens naar een intern geoptimaliseerd, gecomprimeerd, kolomgeoriënteerd formaat. Snowflake slaat deze geoptimaliseerde gegevens op in cloudopslag.
Snowflake beheert alle aspecten van de opslag van deze gegevens: de organisatie, bestandsgrootte, structuur, compressie, metadata, statistieken en andere aspecten van de gegevensopslag. De door Snowflake opgeslagen dataobjecten zijn niet direct zichtbaar of toegankelijk voor klanten; ze zijn alleen toegankelijk via SQL-query's die met Snowflake worden uitgevoerd.
Queryverwerking
De query-uitvoering vindt plaats in de verwerkingslaag. Snowflake verwerkt query's met behulp van "virtuele warehouses". Elk virtueel warehouse is een MPP-computercluster dat bestaat uit meerdere rekenknooppunten die door Snowflake worden toegewezen vanuit een cloudprovider.
Elk virtueel datawarehouse is een onafhankelijk computercluster dat geen computerbronnen deelt met andere virtuele datawarehouses. Hierdoor heeft elk virtueel datawarehouse geen invloed op de prestaties van andere virtuele datawarehouses.
Cloudservices
De cloudservicelaag is een verzameling services die activiteiten binnen Snowflake coördineren. Deze services verbinden alle verschillende componenten van Snowflake om gebruikersverzoeken te verwerken, van inloggen tot het verzenden van query's. De cloudservicelaag draait ook op compute-instances die door Snowflake worden geprovisioneerd vanuit de cloudprovider.
Geef uw bedrijf een boost met het Snowflake Cloud-dataplatform.
Functies
Enkel platform
Een van de beste eigenschappen van Snowflake, die vaak wordt benadrukt, is de mogelijkheid om verschillende activiteiten op één platform uit te voeren. Gebruikers kunnen een breed scala aan activiteiten uitvoeren, zoals app-ontwikkeling, data mining in de data lake, onderzoek door datawetenschappers en nog veel meer.
Beveiligde gegevens
Het datawarehouse biedt gebruikers de mogelijkheid om gegevens veilig te delen met verschillende afdelingen binnen het bedrijf of zelfs met klanten, zonder zich zorgen te hoeven maken over de beveiliging. Of het nu gaat om gestructureerde of semi-gestructureerde data, gebruikers kunnen deze live delen zonder zich zorgen te hoeven maken over mogelijke problemen.
Schaalbaarheid
De Snowflake multi-cluster gedeelde data-architectuur elimineert de noodzaak voor opslag- en rekenresources. Deze strategie stelt gebruikers in staat om resources op te schalen wanneer ze enorme hoeveelheden data sneller moeten laden en weer af te schalen wanneer het hele proces is voltooid, zonder dat de service hierdoor wordt beïnvloed. Gebruikers kunnen beginnen met een extra klein virtueel datawarehouse en naar behoefte op- en afschalen.
Geen onderhoud nodig
De gebruiker krijgt de mogelijkheid om verschillende infrastructuurproviders te kiezen, terwijl Snowflake het dataplatform beheert. Het datawarehouse staat bekend als een van de beste opties om de efficiëntie van de bedrijfsvoering en de soevereiniteit van de data te waarborgen.
Beveiliging
Van de manier waarop gebruikers toegang krijgen tot Snowflake tot hoe gegevens worden opgeslagen, Snowflake beschikt over een breed scala aan beveiligingsfuncties. U kunt netwerkbeleid beheren door IP-adressen op een whitelist te plaatsen om de toegang tot het account te beperken. Snowflake ondersteunt tal van authenticatiemethoden, waaronder ondersteuning voor SSO via federatieve authenticatie en tweefactorauthenticatie. Toegang tot objecten in het account wordt geregeld via een hybride model van discretionaire toegangscontrole (elk object heeft een eigenaar die toegang tot het object verleent) en op rollen gebaseerde toegangscontrole. Deze hybride aanpak biedt een aanzienlijke mate van controle en flexibiliteit.
Snowflake-object herstellen met Undrop
Dit is een van de unieke eigenschappen van Snowflake. Je kunt een Snowflake-object dat per ongeluk is verwijderd, herstellen. Een verwijderd object kan worden hersteld met het commando `undrop` in Snowflake, zolang het object zich nog binnen het herstelvenster bevindt.
Sommige klanten van Snowflake
- Micron
- Yamaha
- Nielsen
- Overstock
- HubSpot
- Adobe

Azure Data Platform is een cloudgebaseerde service voor gegevensintegratie waarmee u datagestuurde workflows in de cloud kunt creëren voor het orkestreren en automatiseren van gegevensverplaatsing en gegevenstransformatie.
Het stelt u in staat om datagestuurde workflows te creëren voor het orkestreren van de verplaatsing van gegevens tussen ondersteunde gegevensopslaglocaties en de verwerking van gegevens met behulp van computerdiensten in andere regio's of een on-premise omgeving. Het biedt u tevens de mogelijkheid om workflows te bewaken en te beheren via zowel programmatische als gebruikersinterface-mechanismen.
Met Azure Data Factory kunt u datagestuurde workflows (ook wel pipelines genoemd) maken en plannen die gegevens uit verschillende gegevensopslaglocaties kunnen ophalen. U kunt complexe ETL-processen bouwen die gegevens visueel transformeren met behulp van dataflows.
Bovendien kunt u uw getransformeerde gegevens publiceren naar gegevensopslaglocaties zoals Azure SQL Data Warehouse, zodat business intelligence (BI)-toepassingen deze kunnen gebruiken. Uiteindelijk kunnen ruwe gegevens via Azure Data Factory worden georganiseerd in zinvolle gegevensopslaglocaties en data lakes voor betere zakelijke beslissingen.
AANBEVOLEN LEESVOORWERP: HET SAMEN BESTAAN VAN DATAWAREHOUSES EN DATA LAKES VOOR BEDRIJVEN
Laten we nu eens dieper ingaan op de architectuur van het Azure Data-platform.
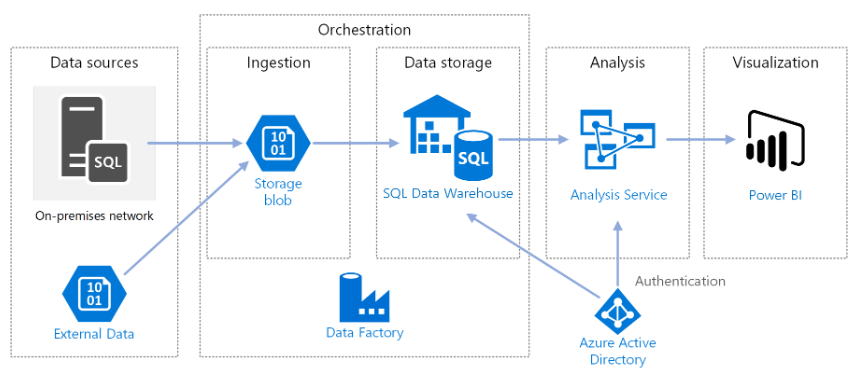
Gegevensbronnen
Externe data - Een veelvoorkomend scenario voor datawarehouses is het integreren van meerdere databronnen. Deze referentiearchitectuur laadt een externe dataset met bevolkingsaantallen per stad per jaar en integreert deze met de data uit de OLTP-database. U kunt deze data gebruiken voor inzichten zoals: "Is de omzetgroei in elke regio gelijk aan of groter dan de bevolkingsgroei?"
Gegevensinvoer en -opslag
Blob-opslag - Blob-opslag wordt gebruikt als een tijdelijke opslagplaats voor de brongegevens voordat deze in Azure Synapse worden geladen.
Azure Synapse is een gedistribueerd systeem dat is ontworpen voor het uitvoeren van analyses op grote hoeveelheden data. Het ondersteunt Massively Parallel Processing (MPP), waardoor het geschikt is voor het uitvoeren van krachtige analyses.
Azure Data Factory - Data Factory is een beheerde service die het verplaatsen en transformeren van gegevens automatiseert. In deze architectuur coördineert het de verschillende fasen van het ELT-proces.
Analyse en rapportage
Azure Analysis Services - Analysis Services is een volledig beheerde service die mogelijkheden biedt voor datamodellering. Het semantische model wordt in Analysis Services geladen.
Power BI is een suite van tools voor bedrijfsanalyse waarmee gegevens kunnen worden geanalyseerd om zakelijke inzichten te verkrijgen. In deze architectuur wordt het semantische model dat is opgeslagen in Analysis Services geraadpleegd.
Authenticatie
Azure Active Directory (Azure AD) verifieert gebruikers die via Power BI verbinding maken met de Analysis Services-server.
Data Factory kan ook Azure AD gebruiken om zich bij Azure Synapse te authenticeren met behulp van een serviceprincipal of Managed Service Identity (MSI). Voor de eenvoud gebruikt de voorbeeldimplementatie SQL Server-authenticatie.
Functies
Gegevensbestendigheid
Het allereerste waar elk bedrijf naar kijkt bij een cloud-datawarehouse is beveiliging. In het geval van Microsoft Azure worden alle gegevens veilig opgeslagen in de datacenters van Microsoft. Microsoft Azure biedt extra beveiliging voor de gegevens als gebruikers kiezen uit de verschillende beveiligingsopties die beschikbaar zijn in het datawarehouse. Dit maakt Azure tot een van de veiligste cloud-datawarehouses en een van de redenen waarom steeds meer bedrijven ervoor kiezen.
BCDR-integratie
Azure Storage biedt niet alleen beveiliging voor uw gegevens, maar zorgt er ook voor dat u altijd klaar bent voor eventuele gegevenshersteloperaties. Dit betekent dat het ook de juiste back-upfuncties voor uw gegevens biedt. Veel klanten en bedrijven maken gebruik van Microsoft Azure, juist omdat het een van de beste back-upoplossingen biedt die uw gegevens ondersteunt.
Capaciteitsmanagement
Capaciteitsplanning en -beheer kunnen zeer tijdrovend zijn. Microsoft Azure biedt daarentegen een hybride architectuur voor opslagoplossingen. Dankzij deze architectuur biedt het datawarehouse tal van opties, zoals archivering, datatiering, compressie en nog veel meer, om de capaciteit optimaal te beheren.
Bediening via één venster
Naast de andere functies die Microsoft Azure biedt, is een andere belangrijke functie de mogelijkheid om vanuit één centraal punt te werken. Dit helpt gebruikers om een beter overzicht te krijgen van de gegevens en deze beter te beheren.
Enkele bekende klanten die Microsoft Azure gebruiken
- EY
- Kennametal
- H&R Block
- Kinderziekenhuis van Cincinnati
Nu data een essentieel onderdeel van het bedrijfsleven is geworden, is het cruciaal om er zo efficiënt mogelijk mee om te gaan. De juiste cloudgebaseerde datawarehouse-diensten bieden hiervoor de perfecte oplossing. Het kiezen van het juiste platform kan een uitdaging zijn, maar door de beste provider te selecteren, kunnen bedrijven het juiste platform vinden.