
Summarize this blog post with:
Most enterprise data engineering teams are not failing for lack of tools. They are failing because the tools accumulated over the last decade were never designed to work together.
A warehouse for reporting. A lake for scale. A separate ML environment. A streaming layer bolted on when batch could not keep up. Each decision made sense at the time. The architecture they produced together does not.
Do You Know?
- Poor data quality costs organisations an average of $12.9 million annually.
- Enterprises operating separate lake and warehouse environments spend up to 30% of their total data infrastructure budget on redundant data movement and storage — before generating a single insight.
The Databricks Lakehouse replaces the fragmented stack with a single open platform. This blog works through the specific data engineering challenges the Databricks data Lakehouse architecture solves — and the mechanics of how it solves them.
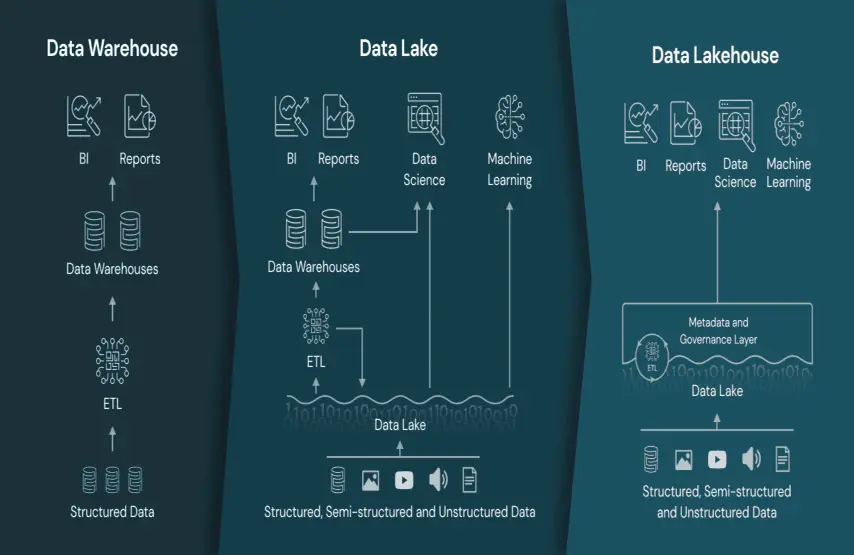
Before examining individual challenges, it is worth being precise about what the Databricks Lakehouse platform is — because that definition shapes every implementation decision downstream.
The Databricks data Lakehouse is not a warehouse with lake features added, or a lake with warehouse governance bolted on. It is a single open platform that provides the transactional reliability, schema enforcement, and query performance of a warehouse while preserving the scale, openness, and ML compatibility of a data lake. The Lakehouse architecture on Databricks runs on open table formats — Delta Lake and Apache Iceberg — which means there is no vendor lock-in at the storage layer, and every compute engine that supports open standards can read from and write to the same tables.
 Source - Databricks
Source - Databricks
When a warehouse and a data lake coexist as separate systems, the same data is ingested twice, transformed twice, and quality-checked twice — by different teams, producing different numbers. Every new data source multiplies this overhead. It is a structural problem, not a data quality one.
What the Databricks Lakehouse Does?
The Lakehouse Databricks architecture eliminates this by design. A single open platform — built on Delta Lake and the medallion architecture — supports BI, streaming, and AI workloads on the same underlying data without movement or replication.
Data flows once through the pipeline layers:
- Bronze — raw ingestion, preserved exactly as received from source systems, with no transformation applied
- Silver — cleansed, validated, and enriched; schema-enforced and quality-checked before any analytical consumption
- Gold — aggregated and optimised for the specific reporting, dashboarding, or model training use case it serves
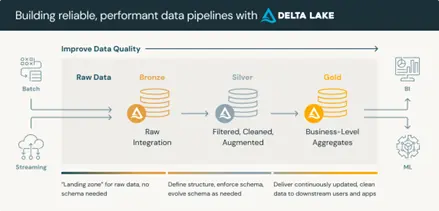
One ingestion pipeline. One transformation logic. One version of the metric.
The elimination of duplicate pipelines reduces the failure surface and simplifies debugging significantly. When a metric discrepancy surfaces in a business review, there is one pipeline to investigate and one transformation logic to audit — not three. That reduction in diagnostic complexity is where engineering hours are recovered most consistently in production Lakehouse environments.
Organisations that implement layered data architectures with clear quality enforcement zones report a 3x improvement in data pipeline reliability compared to those using flat, unstructured lake architectures.
Traditional data lakes lack transactional guarantees. Concurrent writes produce partial updates. Failed jobs leave tables in indeterminate states. Schema changes propagate silently, corrupting downstream analytics. In regulated industries, the absence of an auditable data history is a compliance exposure, not just an engineering inconvenience.
What the Databricks Data Lakehouse Does?
Delta Lake resolves the transactional problem at the storage format level. Every write either completes fully or does not happen at all — no partial states, no silent corruption. Schema enforcement prevents upstream changes from propagating into analytical datasets without explicit validation at the pipeline layer. Time-travel allows engineers to query or restore any previous version of a table — what previously took hours takes minutes.
Apache Iceberg extends these guarantees into multi-engine environments through an open specification, ensuring the same transactional properties apply regardless of which compute engine is reading or writing the table.
What the Databricks Data Lakehouse Does?
Delta Lake resolves the transactional problem at the storage format level. Every write either completes fully or does not happen at all — no partial states, no silent corruption. Schema enforcement prevents upstream changes from propagating into analytical datasets without explicit validation at the pipeline layer. Time-travel allows engineers to query or restore any previous version of a table — what previously took hours takes minutes.
Apache Iceberg extends these guarantees into multi-engine environments through an open specification, ensuring the same transactional properties apply regardless of which compute engine is reading or writing the table.
By 2026, 60% of organisations that fail to govern their data at the storage layer will experience at least one material compliance incident related to AI or analytics outputs."
Business Impact:
When a compliance audit requires data provenance documentation, or when an AI initiative hits a CISO governance review, the time-travel and lineage capabilities of the Databricks data Lakehouse architecture provide structured, query-able evidence that manual documentation processes cannot. Audit preparation time drops from days to hours — not because the process changed, but because the evidence was captured automatically at every step.
In fragmented architectures, governance is applied separately in each environment — warehouse permissions in one system, lake controls in another, ML access managed independently. Lineage tracks within environments, not across them. When an AI initiative hits a CISO review asking which data the model trained on, who had access, and what controls were in place — an ungoverned architecture cannot answer it. Projects halt.
72% of business leaders express concern about the trustworthiness of AI outputs. The governance gap is not a peripheral concern — it is the central obstacle between AI experimentation and AI at scale.
What the Databricks Lakehouse Does?
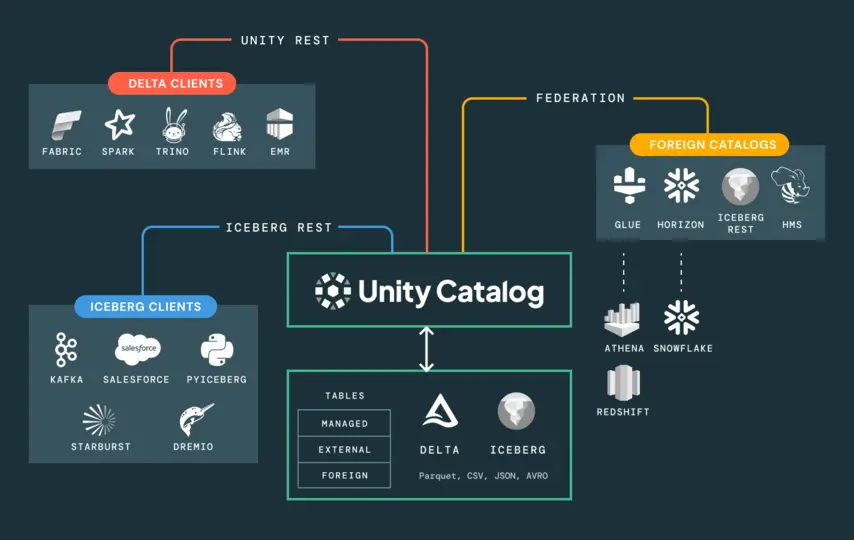
Unity Catalog provides a single governance layer across the entire Lakehouse platform — data, analytics, ML models, notebooks, and dashboards managed under one metastore with consistent access policies. Row-level and column-level controls are applied using standard ANSI SQL. End-to-end lineage tracks every transformation from raw source through every pipeline layer to the final model or report output — in a queryable graph.
Unity Catalog must be provisioned before pipelines are built and before models are trained. Retrofitting governance onto a working system cost significantly more — in engineering time and stakeholder trust — than architecting it correctly from the start.
 Source - Databricks Unity Catalog
Source - Databricks Unity Catalog
Hand-coded streaming pipelines require engineers to maintain every failure mode explicitly — checkpoint management, state recovery, schema evolution, retry logic. At scale, this becomes a maintenance liability that consumes capacity needed to build anything new. Pipeline failures are not edge cases. They are the recurring events that on-call rotations are built around.
What the Databricks Lakehouse Does?
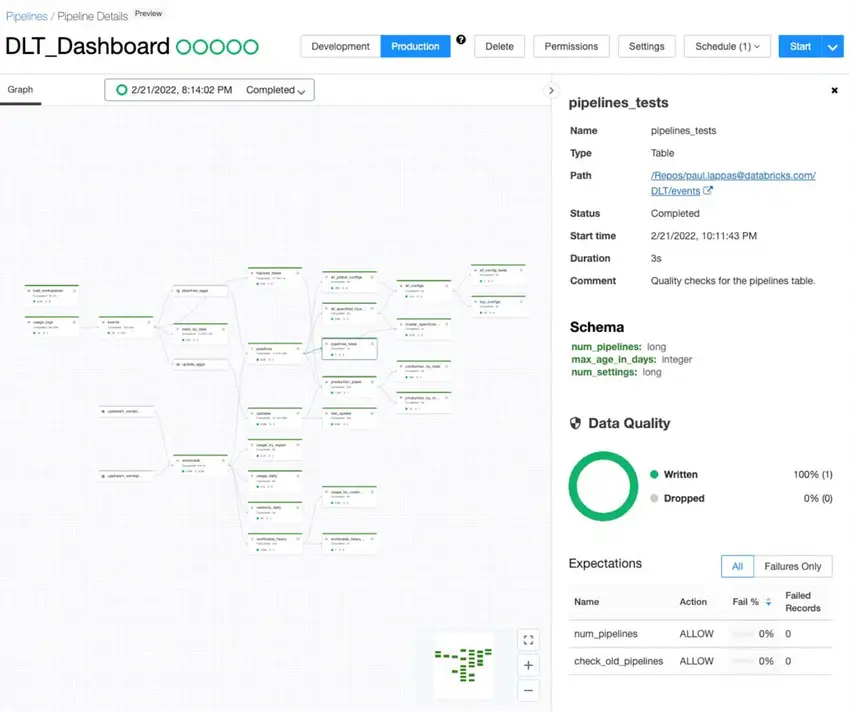
Delta Live Tables (DLT) inverts the pipeline development model from imperative to declarative. Engineers define what the data should look like and what quality standards it must meet. DLT manages dependency resolution, auto-scaling, error handling, retry logic, and data quality enforcement automatically — through configurable expectations that warn, quarantine, or halt on quality violations.
Databricks Workflows extends this to multi-step orchestration: scheduling complex pipelines that combine notebooks, DLT tasks, and ML models, with built-in repair and rerun capabilities that resume from the point of failure rather than restarting from scratch.
 Source - Databricks DLT
Source - Databricks DLT
Manual cluster management creates a persistent cost and overhead problem. Size for peak load and you pay for idle compute at off-peak. Size for average and jobs queue at peaks. Manual tuning — VACUUM, OPTIMIZE, partition adjustments — is time-consuming and inconsistent across workload types.
What the Databricks Lakehouse Does?
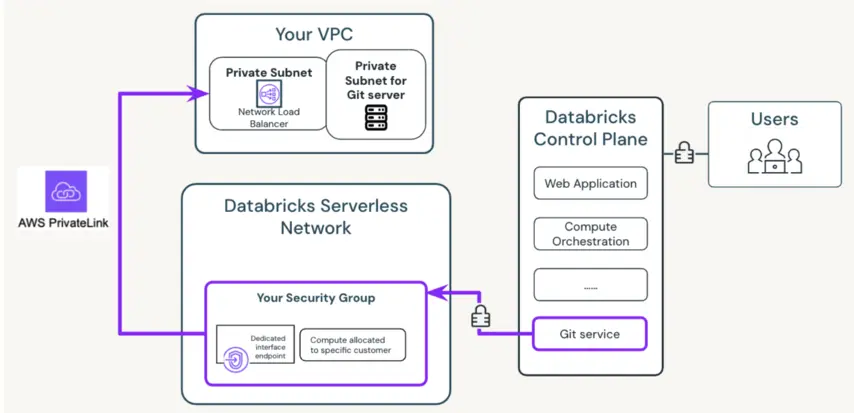
Serverless compute on the Databricks Lakehouse platform abstracts infrastructure management entirely. Compute is provisioned instantly when a workload starts and released when it finishes — no cluster configuration, no idle resource management, no cold-start delays. The security architecture separates the control plane from the data plane, ensuring customer data remains in the customer's own cloud account, encrypted at rest and in transit — whether deployed as an AWS data Lakehouse or an Azure Databricks Lakehouse.
Predictive Optimisation closes the manual tuning loop: AI-driven algorithms analyse query patterns continuously and run background maintenance — VACUUM, OPTIMIZE — only when performance analysis indicates a meaningful improvement. Manual tuning is replaced by automated, ROI-justified maintenance.
Do You Know?
Databricks Lakehouse platform with structured compute governance achieved a 247% ROI over three years, with a payback period of under seven months!
 Source - Databricks
Source - Databricks
Lower total cost of ownership, faster workload execution, and consistently high query performance without manual tuning intervention. Engineering capacity is redirected from infrastructure management to pipeline development — the work that compounds in value over time!
The sequencing of implementation decisions determines whether the Databricks Lakehouse architecture delivers or accumulates a new category of technical debt. Provision Unity Catalog first. Enforce compute governance before workloads scale. Adopt Delta Live Tables before manual orchestration becomes the liability your on-call rotation is built around. These decisions are harder to retrofit than to get right from the start — and the cost of getting them wrong shows up quickly in cloud bills, compliance reviews, and engineering morale.
This is precisely where having navigated these decisions across multiple production environments makes the difference. Polestar Analytics has built Lakehouse architectures across logistics, manufacturing, and financial services — implementing Unity Catalog governance frameworks, DLT pipeline architectures, and compute policies that hold up under real production pressure. We do not consult from a distance. We have made these calls under deadline, in production, with real stakes.
If your organisation is evaluating the Databricks Lakehouse platform for the first time or trying to unlock more from an existing deployment that has not delivered on its architectural promise — the right starting point is a conversation about where your architecture currently stands and what sequencing makes sense given your data estate, team, and AI roadmap.