
Sammanfatta detta blogginlägg med:
Redaktörens anmärkning – Ni har informationen. Frågan år 2026 är om infrastrukturen under den byggdes för att agera utifrån den – eller bara rapportera om den. Tekniken har mognat. Arkitekturerna har konvergerat. Nu handlar det om att få det att fungera i stor skala.
Dataanalystrenderna som formar 2026 handlar inte om nya verktyg eller större modeller – de handlar om vad datateam nu ansvarar för, och vad det kostar när de gör fel. Skrivet för dataingenjörer, analysarkitekter och CDO:er som fattar infrastrukturbeslut just nu.
Nästan alla stora företag idag hävdar att de är datadrivna. Endast 37,8 % av Fortune 1000-företagen är det faktiskt – trots att de i genomsnitt spenderar 250 miljoner dollar årligen på datainitiativ. Den skillnaden har funnits i åratal. Det som är annorlunda år 2026 är kostnaden.
När analysinfrastrukturen bara behövde stödja rapportering, innebar en trasig pipeline en trasig instrumentpanel. Återställningsbar. Synlig. Innesluten. Men när AI går från pilot till produktion, utlöser samma infrastruktur nu beslut automatiskt – och dålig data producerar inte längre bara en dålig rapport. Den producerar en dålig åtgärd, i maskinhastighet och i stor skala.
Mer än hälften har slösat bort betydande resurser på utbildningsmodeller på data de inte borde ha litat på.
De organisationer som vidgar klyftan är inte de som har de bästa modellerna eller de största teamen. Det är de som behandlade dataarkitektur som det strategiska beslutet – inte en förutsättning för det strategiska beslutet.
Den globala analysmarknaden förväntas växa från 104 miljarder dollar år 2026 till 496 miljarder dollar år 2034. Vad som avgör vem som fångar upp det värdet avgörs redan av de infrastrukturval som görs just nu. Här är de sex förändringar som skiljer organisationerna åt när det gäller att göra rätt.
I årtionden användes analyser som en pull-modell. Någon formulerade en fråga, öppnade ett verktyg, och systemet returnerade ett svar. Insikten var bara så bra som frågan ställdes – vilket innebar att hela signalkategorier gick obemärkta förbi helt enkelt för att ingen tänkte på att titta.
Agentanalyser bryter mot det kontraktet. Istället för att vänta på att bli tillfrågade, observerar dessa system kontinuerligt – de upptäcker avvikelser innan de blir problem, förklarar siffrorna i ett enkelt språk och agerar direkt på dem där tröskelvärden tillåter. Människor håller sig uppdaterade, men på beslutsnivå, inte på hämtningsnivå.
Så här fungerar AI-agenter -
Det som driver detta är inte bara en sak. Stora språkmodeller (LLM) gav agenter möjlighet att resonera över ostrukturerat sammanhang. Mindre specialiserade modeller (SLM) gjorde det resonemanget överkomligt i stor skala. Tillsammans producerar de något som traditionell regelbaserad automatisering aldrig skulle kunna – bedömningar som anpassar sig. Plattformar som 1Platform bäddar redan in detta i BI-verktyg genom sitt konsumtionslager, vilket innebär att agentanalys inte längre är ett separat system. Det är ett beteende inom de plattformar som team redan använder.

Gartner förutspår att 40 % av företagsapplikationer kommer att bädda in uppgiftsspecifika AI-agenter i slutet av 2026, en ökning från mindre än 5 % år 2025.
För analytiker är den praktiska förändringen följande: mindre tid på att hämta data, mer tid på att tolka den. Rollen krymper inte – den flyttas uppströms.
Traditionella analyspipelines har ett riktningsproblem. Data flödar i en riktning – inhämta, transformera, modellera, servera. En insikt landar i en instrumentpanel, en människa agerar utifrån den, och det som händer sedan försvinner helt enkelt. Resultatet återgår aldrig till modellen. Nästa förutsägelse körs på samma historiska data, blind för vad det senaste beslutet faktiskt producerade.
Sluten beslutsintelligens styr riktningen. Varje beslut blir en datahändelse i sig – den fångas upp, märks och återkopplas som en träningssignal. Modellen lär sig av vad den gjorde, inte bara vad data sa innan den agerade. Noggrannheten ökar. Pipelinen slutar vara en enkelriktad gata.
TL;DR
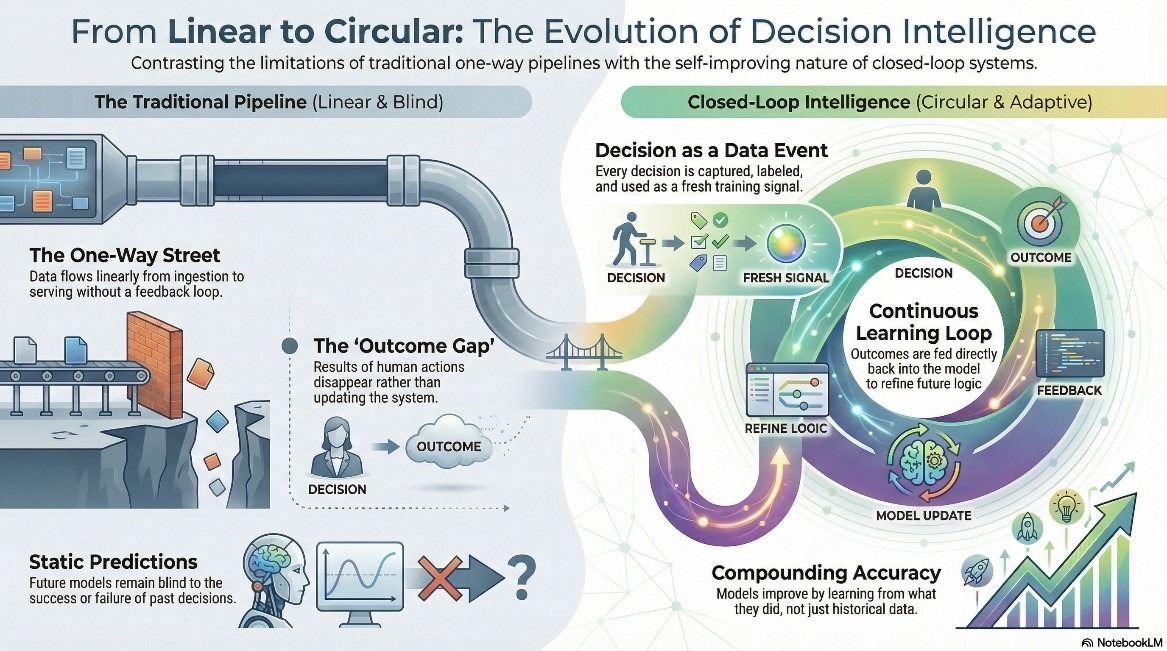
För datateam skapar detta en ny kategori av infrastrukturansvar. Resultatdata är nu en förstklassig enhet – den måste modelleras, styras och övervakas som vilken produktionskälla som helst. Det låter enkelt tills återkopplingsslingan börjar fallera i tysthet. Resultatdata anländer sent. Den anländer felmärkt. Ibland anländer den inte alls. Var och en av dessa producerar modellavvikelser som är betydligt svårare att upptäcka än ett trasigt inmatningsjobb – och 89 % av dataledarna med AI i produktion har redan upplevt vilseledande resultat som ett resultat av just den här typen av uppströmsfel.
Det är här 1Platforms arkitektur gör den slutna slingan operationell snarare än teoretisk. Data Nexus styr hela datatillgången inklusive resultatsignaler, medan Agenthood AI verkställer beslut inom definierade tröskelvärden och skriver varje åtgärd och resultat tillbaka till pipelinen. Avvikelser blir detekterbara. Beslut blir granskningsbara. Feedback-slingan behandlas som infrastruktur – för det är vad den är.
Dataägande flyttas ut från central ingenjörskonst och in i verksamheten – och arkitekturen kommer äntligen ikapp. Lakehouse-företaget enhetlig lagring och beräkning. Vad det inte kunde förena var ägande. I takt med att organisationer skalar upp är den verkliga flaskhalsen inte arkitekturen – det är styrningsvakuumet som uppstår när dussintals domänteam producerar data utan tydlig ansvarsskyldighet.
Datameshen tar vid där Lakehouse slutar. Istället för att centralisera allt till en plattform som ägs av ett team, distribuerar meshen ägarskapet till domänteam under federerad styrning – Lakehouse som tekniskt substrat, Delta Lake, Apache Iceberg och Apache Hudi möjliggör interoperabilitet mellan leverantörer, och meshen som den övergripande operativa modellen. Datakontrakt mellan producenter och konsumenter framträder som den praktiska verkställighetsmekanismen, vilket förvandlar SLA:er från ambitiösa mål till operativa åtaganden.
Marknaden för datanät återspeglar hur seriöst företag tar detta: 1,5 miljarder dollar år 2024, på väg mot 3,5 miljarder dollar år 2030. När domänteam äger sina data med ansvarsskyldighet kopplat till sig, tränas AI-modeller på renare indata, tvärfunktionella frågor slutar vänta i en ingenjörskö och verksamheten får svar som återspeglar vad som faktiskt händer.
Men bara 18 % av organisationerna har den styrningsmognad som krävs för att genomföra detta väl, och 62 % anger fortfarande styrning som sitt enskilt största hinder för AI-implementering . Gapet är sällan arkitekturen – det handlar om huruvida observerbarhet är inbyggd från dag ett och om äganderätten till SLA verkligen överförs till domänteam. Federerat ägande utan ett konvergenslager byter bara ut en flaskhals mot en annan. 1Platform sitter ovanför mesh-systemet för att täppa till det gapet – och förenar datahantering, beslutsintelligens och agentutförande till ett styrt lager så att distribuerat ägande inte fragmenterar analysupplevelsen.
Harmonisering av datanät och DDH för en global ledare inom Alcobev
SLM:er generaliserar inte – det är poängen. Finjustering av proprietära arbetsflöden som ekonomiavstämning, klinisk dokumentation eller hantering av undantag i leveranskedjan kräver märkta, domänspecifika utbildningsdata i stora volymer. Verkliga data levererar sällan detta. Kantfall är strukturellt underrepresenterade, regleringar begränsar vad som är användbart för utbildning och annotering i stor skala är dyrt och långsamt.
Syntetiska data är den tekniska lösningen. Med det på plats kan du nu:
- Generera de edge-fall som aldrig visas i produktionsloggar.
- Skapa regelkompatibla träningsuppsättningar utan att vidröra PII.
- Etikett i skala utan mänskliga annotatorer.
Grand View Research uppskattar marknaden för AI-träningsdataset till 3,2 miljarder dollar år 2025 och att den når 16,3 miljarder dollar år 2033 – syntetisk data är det snabbast växande segmentet med en årlig tillväxttakt på 30,5 %. Gartner förutspår att syntetisk data kommer att överträffa verkliga data som primär källa för AI-träning år 2030.
För datateam är detta en ny yta för ägande. Syntetiska datapipelines kräver distributionsvalidering – genererad data som inte återspeglar verklig varians producerar modeller som klarar utvärderingen och misslyckas tyst i produktion. Schematäckning, klassbalans och avvikelse mellan syntetiska och verkliga fördelningar måste alla instrumenteras och övervakas. Kvalitetsmåttstocken är identisk med alla produktionsdatakällor. Skillnaden är att datateamet nu är upphovsmannen, inte bara förvaltaren.
Organisationer som lyckas med detta behandlar generering av syntetisk data som en förstklassig ingenjörspraxis – versionerad, testad, styrd – inte ett förbehandlingssteg som någon kör före modellträning.
Aktualitet, schema, volym, distribution, avstamning – byggt för BI-dashboards. I agentpipelines, där data driver autonoma beslut, måste observerbarheten överträffa traditionella standarder.
Gapet är uppströms. Salesforce sätter 89 % av dataledarna med AI i produktion efter att ha upplevt vilseledande resultat. De flesta felen har inte sitt ursprung i modellen – de har sitt ursprung i data som matar den. Funktionsförskjutningar mellan utbildning och visning. Schemaändringar som klarar validering men bryter nedströms logiken. Resultatdata som returneras sent och korrumperar feedback-slingan.
2026-stacken lägger till det som klassisk observerbarhet saknar: övervakning av funktionsdistribution mellan utbildnings- och serveringsomgivningar, upprätthållande av dataavtal vid producent-konsumentgränser och observerbarhet av resultatdata för att sluta feedback-loopen. Team som endast instrumenterar modelllagret behandlar symtomet. Sjukdomen är uppströms.
En modell kan ha noggrannhet och ändå vara ostyrbar. Ingen härledning till träningsdata. Ingen dokumentation av hur funktioner konstruerades. Inget sätt att förklara för en tillsynsmyndighet, en revisor eller en affärsintressent varför systemet producerade en specifik utdata. År 2026 är det inte ett efterlevnadsgap – det är ett hinder för implementering.
Förändringen som sker inom datateamen är att styrningen flyttas uppströms i byggprocessen. Datakontrakt definieras innan pipelines går live, inte förhandlas fram efter att något går sönder. Kvalitets-SLA:er som ägs av domänteamet som producerar datan, inte en central funktion som granskar den i efterhand. Träningsdata versionsviseras och dokumenteras på samma sätt som produktionskod – för när en modell beter sig fel är den första frågan alltid vilken data som tränar den.
 Gartner
Gartner EU:s AI-lag som träder i kraft från augusti 2026 formaliserar det som ledande datateam redan behandlar som standard: övergången från råkälla till modellutdata är en förstklassig teknisk leverans. Organisationerna som ligger före detta gör inte mer styrningsarbete – de har bara flyttat det tidigare, till arkitektur och pipelinedesign där det kostar en bråkdel av vad eftermontering kostar senare.
De flesta datateam år 2026 är bara ett arkitekturbeslut ifrån att antingen öka sina AI-investeringar eller undergräva dem. Skillnaden är inte budget eller talang. Det handlar om huruvida datatillgången – pipelines, kontrakt, feedback-loopar, styrning – utformades för autonomt beslutsfattande eller bara rapportering.
Gartners förutsägelser tydliggör riktningen. År 2028 kommer den fragmenterade datahanteringsmarknaden att konvergera till ett enda ekosystem kring data fabric och GenAI. År 2027 minskar AI inbäddad i datatekniska verktyg manuella ingrepp med 60 %. År 2026 blir naturligt språk det dominerande gränssnittet för datakonsumtion. Infrastrukturen byggs inte längre kring AI. Den byggs om av den.
Organisationerna som ligger framför oss gör inte mer. De byggde rätt grund tidigare. 1Platform från Polestar Analytics sammanför datahantering, beslutsintelligens och agentutförande till ett styrt lager – så att avståndet mellan vad datan säger och vad verksamheten gör med den slutar vara ett arkitekturproblem.