
Sammanfatta detta blogginlägg med:
Redaktörens anmärkning:
I den här artikeln om Data Lakehouse besvarar vi miljondollarfrågan om Data Warehouse kontra Data Lakehouse kontra Data Lake genom att ge en kort sammanfattning av varför och hur det uppstod. Fortsätt läsa om du vill förstå nyanserna hos Lakehouse när det gäller Databricks och Fabric !
Är du i det här tillståndet: Uttråkad av att alla pratar om generationens AI, när det i verkligheten bara är det verkliga hindret bakom det som syns? Data. Beviset på det förvirrade dataekosystemet är det nuvarande data-, maskininlärnings- och AI-landskapet, som ser ut ungefär så här:
 Tack till Mattturk & Firstmark för denna fantastiska forskning.
Tack till Mattturk & Firstmark för denna fantastiska forskning. TLDR: MAD-landskapet är lika kaotiskt som neurala nätverks dolda lager.
Men med tanke på att 72 % av de högst presterande VD:arna (enligt IBM) säger att konkurrensfördelar beror på vem som har den mest avancerade generativa AI:n och artificiella intelligensen; och att maskininlärning är företagens högsta prioritet (flera rapporter) – anser vi att det är viktigt att ställa frågan: Kan era data faktiskt stödja allt detta?
För att besvara denna fråga, låt oss ta en resa tillbaka i datatidslinjen för att se hur databehoven och datahanteringsbehoven har utvecklats:
- Era 1.0: Företag ville ha insikter från sina data, så de skaffade datalager ovanpå sina data med schema-on-write-funktioner för att stödja business intelligence. Men problemet uppstod med växande typer av ostrukturerade datamängder, betalning för toppbelastningar och ett växande behov av komplex analys. Eftersom inget av de ledande ML-systemen, som TensorFlow, PyTorch och XGBoost, fungerar bra ovanpå lager. ML-system behöver bearbeta stora datamängder med komplex icke-SQL-kod.
- Era 2.0: För att stödja avlastning av rådata i lågkostnads- och öppna format som Parquet, samtidigt som system kunde bearbeta icke-SQL-kod, gick vi in i eran av datasjöar med schema-on-read-arkitektur. Men de förlorade de omfattande datahanteringsfunktionerna som behövdes för ACID-transaktioner, indexering etc. som fanns på datalager.
- Era 3.0: Kombinationen av Datalake + Data Warehouse – eller tvåskiktsarkitekturen – där en delmängd av data från datasjön ETL-läggs till ett nedströms datalager för efterföljande analys och Business Intelligence-applikationer. Även om detta gynnar både BI och AI, kan komplexiteten i tillagda ETL-steg, förändringen i semantik, SQL-dialekter och de datatyper som stöds skilja sig åt. Även den ökade sannolikheten för fel och buggar.
- Era 4.0: Den nuvarande eran av Data Lakehouse – att kombinera den semantiska flexibiliteten och lagringen av data lake med beräkning och leverans av ett datalager, dvs. att eliminera eller minska friktionen mellan dataanvändning och inmatning.
Data Lakehouse är en hybridplattform för datalagring och bearbetning som kombinerar det bästa från både traditionella datasjö- och datalagertekniker: billig lagring i ett öppet format som är tillgängligt via en mängd olika system från den förra, och kraftfulla hanterings- och optimeringsfunktioner från den senare.
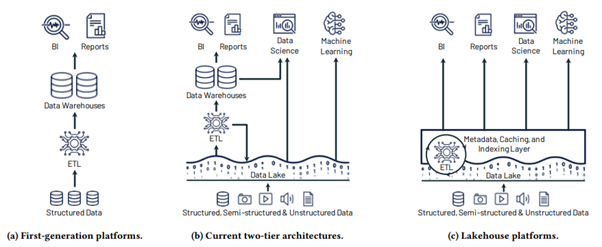 Utvecklingen från en tvåskiktsarkitektur till Data Lakehouse
Utvecklingen från en tvåskiktsarkitektur till Data Lakehouse Lakehouse-arkitekturen, som du kan se i Databricks, Microsoft Fabric etc., syftar till att minska kostnaden, driftskostnaderna och komplexiteten i att överföra data för flera syften, från Business Intelligence till Artificiell Intelligens.
Även om resan för data Lakehouses började med Uber och sedan Netflix, har nu majoriteten av Fortune 500-företagen redan börjat sin resa med dem. Tre av de viktigaste märkbara fördelarna med att använda Data Lakehouse är:
- Minskad föråldrad data: Ungefär 70–80 % av analytikerna använder föråldrad data – med all data lagrad på ett ställe och i ett format får du mer kontroll över dina data.
- Enhetlig plattform för all dataanalys: Data Lakehouses kan tillhandahålla en plats för BI, SQL-analys och mer avancerad analys, inklusive maskininlärning, eftersom många ML-bibliotek, som TensorFlow och Spark MLlib, redan kan läsa Data Lake-filformat som Parquet.
- Minskad kostnad: Ni kan eventuellt eliminera behovet för organisationer att betala för att lagra samma data två gånger, vilket de ofta måste göra när de använder både datalager och en datasjö. Dessutom låser kommersiella datalager ofta data i proprietära format, vilket kan vara dyrt – medan Data Lakehouses använder öppna format.
Vill du kontrollera den aktuella hälsan hos dina datapipelines och datahanteringsprocesser? Få ett kostnadsfritt discovery-samtal med våra data engineering-experter!
Få expertråd om datahantering Även om vi har pratat om alla tre och hur utvecklingen inom datahantering har gjort det nödvändigt att ha mer än en av dem, ska vi försöka jämföra dem på enklast möjliga sätt.
Från det framväxande behovet av att förbli flexibel till att anpassa sig snabbt – behovet av att balansera kostnader med det växande behovet av datahantering balanseras med Data Lakehouse.
Skillnader mellan datalager, datasjö och datasjöhus
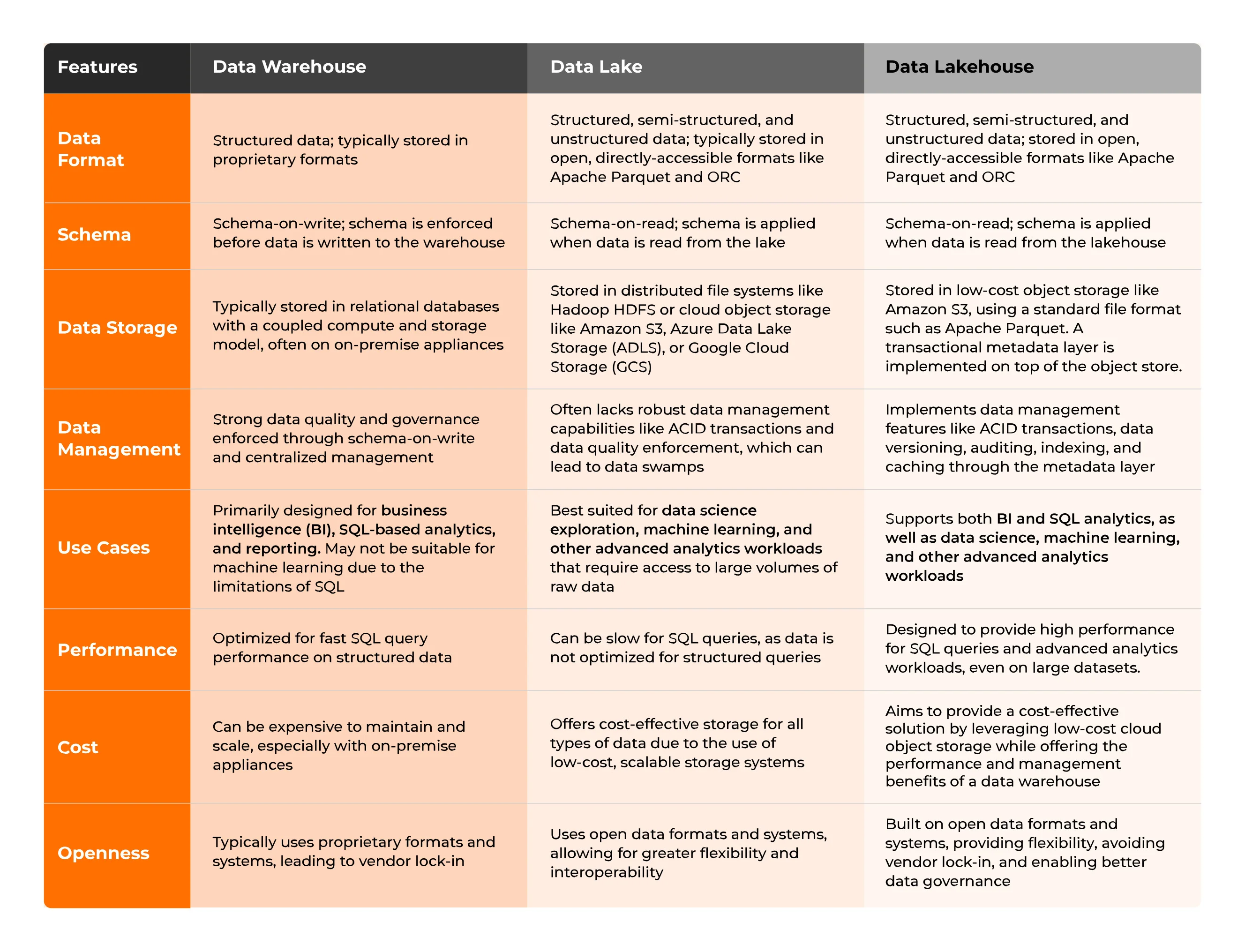 Visar upp skillnaderna mellan olika parametrar som dataformat, schema, öppenhet, prestanda etc.
Visar upp skillnaderna mellan olika parametrar som dataformat, schema, öppenhet, prestanda etc. TL;DR: Data Lakehouse lagrar data i ett liknande format som Data Lake, men det transaktionella metadatalagret definierar vilka objekt som ingår i en tabellversion, som ett datalager. Från den större flexibiliteten i interoperabilitet som Data Lakes och möjligheten till ACID-transaktioner som Data Warehouse – Data Lakehouse är en sammanslagning av båda idéerna.
Syftet bakom varför Data Lakehouse måste vara tydligt vid det här laget. Så, låt oss dyka in i "hur". En vanlig Data Lakehouse-arkitektur består av 5 lager, nämligen:
- Inmatningslager: Samlar in data från flera källor som transaktionsdata, CRM, inga SQL-databaser och omvandlar den till lagringsbart format.
- Lagringslager: Vanligtvis lagrat i ett billigt lagringsformat, vilket innebär typisk molnobjektlagring, såsom Amazon S3, Azure Data Lake Storage (ADLS) eller Google Cloud Storage (GCS) – i öppna, direkt tillgängliga format som Apache Parquet och ORC.
- Metadatalager: Detta lager, unikt för Data Lakehouse, ligger ovanpå Lake Storage. Lagret hanterar tabellformatet och spårar filerna – samtidigt som det möjliggör funktioner som schematillämpning, dataversionshantering, granskning etc. Exempel på metadatalager inkluderar Delta Lake, Apache Hudi och Apache Iceberg.
- API-lager: Detta möjliggör datafrågor med SQL-API:er för traditionell BI- och SQL-analys och deklarativa DataFrame-API:er för datavetenskap och maskininlärningsarbetsbelastningar.
- Datakonsumtionslager: Från BI-verktyg för dashboarding, datavetenskap och maskininlärning för modellering av data, realtidsapplikationer för strömmande data och datadelning mellan samarbetspartners – detta lager gör det möjligt för användare att konsumera och interagera med data på flera sätt.
 Belyser de 5 lagren i en Data Lakehouse-arkitektur
Belyser de 5 lagren i en Data Lakehouse-arkitektur
Med tillkomsten av Microsoft Fabric och One Lake, dvs. Azure Data, har Lakehouse blivit mer mainstream än det var tidigare. Det är värt att nämna att det "kurerade lagret" (i en Microsoft Fabric-arkitektur) kan ersättas med ett datalager vid behov. Lakehouse i Fabric kan skapas mycket enkelt med följande alternativ på plats.
Du kan hitta mer information om Azure Data Lakehouse-arkitektur och var du kan komma igång här .
Databricks Lakehouse gör det enkelt att automatisera och orkestrera ETL-pipelines. Tidigare har du säkert stött på Azure Databricks (som vanligtvis används med Azure Synapse ) eller deras Delta Live-tabeller för att navigera i komplexiteten inom infrastrukturhantering, uppgiftsorkestrering, felhantering etc.
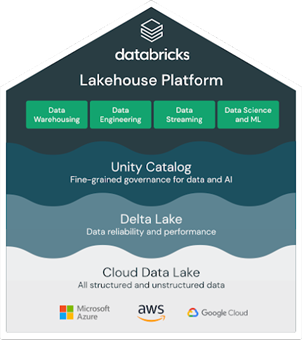 Källa: Databricks
Källa: Databricks Det finns uppenbarligen andra aktörer på marknaden, bland annat Amazon Redshift, Google Cloud BigQuery, Salesforce Data Cloud, Apache Hudi och fler. De viktigaste övervägandena vid valet mellan dem kan vara: prestanda, kostnad, datamängd, skalbarhet, integrationsmöjligheter och styrning.
Vi har sett fördelarna med Data Lakehouse, från att vara mer ekonomiskt än tvåskiktsarkitekturen, en förenklad arkitektur för databearbetning, ökad tillförlitlighet genom att minska problem med datakvalitet och dubbelarbete, förbättrad styrning med konsolidering, till ökad skalbarhet för framtiden.
I takt med att organisationer inser värdet bakom det, särskilt i denna era av AI, skulle det vara avgörande för att spela en central roll i att driva datadrivet beslutsfattande och innovation. Framtiden för datasjöhus är ljus, och deras fortsatta utveckling kommer utan tvekan att forma nästa generations dataplattformar – allt som återstår är att du anammar det väl.
Prata med våra datateknikexperter för att se var och hur detta passar in i er datahanteringsstrategi.