
Sammanfatta detta blogginlägg med:
Vänta, inte helt och hållet "Monica". Men du kan definitivt relatera till den, och alla som någonsin har tittat på vänner kan komma ihåg detta:

Låt oss fördjupa det lite, det handlar inte bara om att behaga människor (vilket i slutändan är slutmålet) , utan att förstå vad folk pratar om och reagera på lämpliga sätt. Så det vi ska prata om idag är hur man faktiskt förstår om folk är nöjda eller när man ibland helt enkelt inte kan förstå det.
Grundidén bakom sentimentanalys är kontextuell utvinning eller opinionsutvinning av texter för att avgöra textens ton och känsla som positiv, negativ eller neutral. I verkligheten använder sentimentanalys tekniker för naturlig språkbehandling (NLP) på texter, data från sociala medier eller recensioner för att få insikter om antingen kunden eller produkten.

Lät definitionen enkel? Vill du veta mer om typerna och hur det görs? Vänta några minuter till, först är det viktigt att förstå hur det behöver användas, och fanns det några exempel där resultaten från sentimentanalys inte gick exakt som planerat? Idag ska vi inte börja med ett prisbelönt exempel, utan med ett varningens ord.
Morbius
Sony återutgav Morbius i juni 2022, men var det rätt val? Även om det pågår mycket debatt kring lanseringen är det viktigt att förstå varför de gjorde det. Twitteranvändare berömde sarkastiskt filmen, påhittade citat och "It's Morbin' Time"-citat, och Sony misstolkade dem som beröm. Okej, det betyder inte att vi ber er att INTE göra sentimentanalys, det betyder bara att det inte är absolut (sarkasm kan såra mer än bara känslor, utan även maskinskrivning). Men vad vi menar är att det måste ses försiktigt med mer sammanhang.
Till exempel kunde Morbius-teamet ha kontrollerat ytterligare data som reaktioner och jämfört dem med andra utgåvor, vilket BuzzSumos forskning sammanfattar vackert nedan:
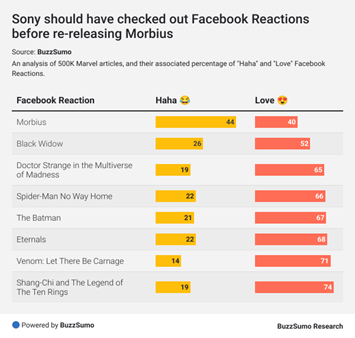
Källa: BuzzSumo Research
Detta visar hur data ibland behöver sammanhang och ses i förhållande till jämförbara objekt. Ovanstående data visar skillnaden i reaktioner mellan Morbius och andra Marvel-filmer.
KPMG
Alla vet att KPMG är en rådgivnings- och revisionsbyrå, vilket gör textanalys mycket viktig för organisationen. Det finns två fall där det är särskilt viktigt för ett företag som KPMG att ha kontextuell mining
Hållbarhetsrapporter är rapporter som är allmänt tillgängliga för allmänheten och investerare i företag som täcker deras ekonomiska, miljömässiga och samhälleliga påverkan. KPMG som revisionsföretag är kvalificerat att analysera om rapporterna kan publiceras eller inte, dvs. de kontrollerar om rapporterna är balanserade (inte bara täcker de positiva aspekterna utan även negativa för att hjälpa människor att göra rätt bedömning). Men de var tvungna att övervinna hindret med positivt formulerade negativa uttalanden, vilket de gjorde med hjälp av Bidirectional Encoder Representation eller BERT från Google. KPMG använder också textanalys för att upptäcka mönster och nyckelord för att flagga efterlevnadsrisker.
Det ökända Johnny Depp-fallet med Amber Heard
Först och främst, utan att ta ställning, utan bara en analys som båda sidor presenterade om tweetsen som innehöll några hashtaggar inklusive #justiceforjohnydepp. I det här fallet presenterade en konsult inom immaterialrätt den "sociala känslan" med
- Antal tweets
- Tidpunkt för tweets
- Innehåll
- Känsla
- Hypotesprövning
Som dataentusiast var sättet han förklarade Twitters API:ers datautvinning och analys mycket spännande. Det ger också en vanlig person möjlighet att fördjupa sig i detaljerna i analysen. De försökte analysera korrelationer mellan påståendena och tid, samt känslan i de övergripande tweetsen.
Oavsett lösningen var det fantastiskt att se att datavetenskap representerades och förstods av alla. Det finns nackdelar, som att man måste använda hela påståendet eller orden exakt när man söker. Återigen kan stavfel inte bara skapa förvirring utan också kringgå systemet. (För "The Office Fans", som när Michael Scott inte kunde ersätta en Dwight med Samuel L. Chang)
Vill du bättre bedöma konsumenternas uppfattning?
Analysera den data som finns tillgänglig för era e-handelsplattformar och härled avsikten bakom dem.
Om du tror att detta är slutet på användningsfallen, har du fel. Det här är bara några exempel från verkligheten. Vi kommer att prata mer om användningsfallen för sentimentanalys efter att vi pratat mer om hur sentimentanalys faktiskt går till.
Byggstenar i sentimentanalys
Naturlig språkbehandling är byggstenen i sentimentanalys och vidare analyser som avsiktsanalys. Baserat på mängden data som behöver analyseras finns det flera sätt att analysera data. De faller huvudsakligen inom två kategorier: regelbaserad och automatisk.
Regelbaserat tillvägagångssätt
Som namnet antyder används den regelbaserade metoden för att identifiera ämnet och åsikten kring det. Några av de faser som ingår i en regelbaserad metod för tweets eller sms, utan någon särskild ordning, är:
- Transformation: Den omvandlar texten till gemener och tar bort HTML, accenter och URL:er som finns i informationen.
- Tokenisering: Det är en metod att dela upp text i mindre ord, vilket inkluderar olika former som ord och interpunktion, mellanslag, mening, regexp och tweet. Vi använder regexp-mönstret här.
- Normalisering: detta inkluderar ordens stamning och lemmatisering. Detta har också flera typer som Porter Stemmer, Snowball Stemmer, WordNet Lemmatizer som tillämpar ett nätverk av kognitiva synonymer på tokens baserat på en stor lexikal databas med engelska, UDPipe tillämpar en förtränad modell för normalisering av data, etc.
- Filtrering och PoS-taggning
Om du vill se alla samtidigt, här är ett exempel på de olika faserna av förbehandling av text i Orange , med bilden nedan:
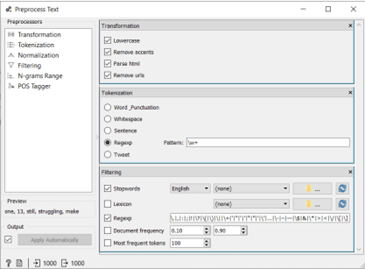
Nackdelarna med att använda ett regelbaserat system är att det inte är tillräckligt avancerat för att bearbeta hur ord kombineras för att bilda meningar, och de kräver finjustering, testning och underhåll för att det ska fungera.
Automatisk tillvägagångssätt
Detta använder maskininlärningstekniker för att modellera texterna som ett klassificeringsproblem för att segmentera dem i positiva, negativa eller neutrala texter. Eftersom modellerna som används är maskininlärning, kommer den data som används först att vara träningsdata, för vilken funktionsutvinning och klassificering sker. Efter att data har tränats hämtas den faktiska datamängden för att ge resultaten.
Fördelen med att använda en maskininlärningsmodell är att den inte bara kan tränas för att passa de tre parametrarna eller taggarna (PNN), utan den kan också tränas för fler parametrar. Till exempel erbjuder Tweet Sentiment Visualization ett brett spektrum av känslor för att kartlägga utdata.

Alla typer av data skulle kräva en viss mängd förberedelser, som vi pratade om i den regelbaserade metoden, som textvektorisering, "bag of words", "bag of n-gram", etc.
Klassificeringsalgoritmerna som används i detta fall kan vara:
- Multipel regression: en mycket välkänd algoritm inom statistik som används för att förutsäga värdet på den oberoende variabeln med flera beroende variabler
- Naive Bayes: Använder Bayes sats för att förutsäga en texts kategori (probabilistisk modell)
- Stödvektormaskiner: en icke-probabilistisk modell som stöder både klassificering och regression, plottar punkter i ett flerdimensionellt rum. Den mappar punkter till hyperplan som differentierar klasserna.
- Neurala nätverk: genom att representera ord med liknande betydelser och liknande vektorvärden med hjälp av tekniker för djupinlärning och ANN
Utöver dessa två modeller kan du även använda en hybridmodell med en kombination av automatiska och regelbaserade metoder. Vi kommer inte att prata om det specifikt, eftersom vi har nämnt i detalj de tekniker och metoder som används i båda. Nu ska vi prata om användningen av sentimentanalys för organisationer.
Även om vi har pratat om några exempel ovan som täcker social sentimentanalys, textutvinning etc., låt oss prata lite om användningsfallen för sentimentanalys för företag vad gäller marknadsföring, varumärkesbyggande, forskning och kundtjänst. Några av tillämpningarna av sentimentanalys är:
1. Avsiktsanalys
Detta är nästa steg i sentimentanalys eftersom det handlar om att förstå avsikten bakom kommentaren, tweeten, sms:et eller frågan. Till exempel handlar avsiktsanalys om att hitta vad meddelandet handlar om, oavsett om det är en nyhet, en åsikt, en annons, ett förslag, en fråga etc. Detta kan hjälpa till att inte bara hitta den relevanta tonen utan också att klassificera vilken typ av meddelanden som tas emot.
2. Varumärkeshantering
Varumärkesimage är viktigt för både företag och människor. För att återgå till Monicas citat (från FRIENDS), du vill att alla ska gilla dig, men hur ser du på det? Att kontrollera betyget på Google kan nu betraktas som gammaldags, särskilt för företag som har en stor närvaro på sociala medier. Nu handlar det om att analysera vad folk faktiskt tänker på, särskilt när det gäller lanseringar av nya produkter och tjänster. All information som delas, som berättelser, bloggar, forum etc., är data och allt detta kan omvandlas till insikter, åtminstone i den utsträckning det går att övervaka den sociala känslan.
3. Kundens röst
Ett enkelt sätt att svara "Varför?" på den här frågan är: Att förbättra sig. Ta till exempel företag som Airbnb eller hotell eller restauranger, deras viktigaste data är kundfeedback, och främst de negativa recensionerna. Kommer du ihåg när Monica gav en negativ recension och försökte visa kocken hur man lagar mat och fick jobbet? (Om du inte är ett Friends-fan, ignorera det!) Kort sagt handlar det om hur du kan förvandla de negativa recensionerna, analysera dem och ändra dem till något handlingsbart när förändringen kan ha en betydande inverkan på framtida beställningar.
4. Feedback från medarbetare
Allt handlar inte om organisationens topp- eller slutresultat, det är också viktigt att titta på organisationens hälsa tillsammans med de anställda. Även om företag kan ha ett Employee Mood Index för att mäta deras humör, eller ett internt NPS, skulle en analys av deras feedback ge a) de områden som de flesta är bekymrade över b) den övergripande känslan i arbetslivet c) fler idéer för att hålla dem produktiva. Inte bara befintliga anställda utan även data från källor som Glassdoor, recensioner etc.
5. Marknadsundersökning
När du lanserar en ny produkt eller tjänst kan du studera, analysera och jämföra din produkt med en befintlig, särskilt med tanke på den stora mängd feedback och recensioner av de flesta produkter som finns tillgängliga online. Du kan också identifiera demografin för användarna som interagerar med produkten eller marknadstrenderna med hjälp av formella tidskrifter och rapporter genom att bedöma dem. Du kan utnyttja nya informationskällor genom att analysera både kvalitativa och kvantitativa källor.
6. Övervakning av sociala medier
Vi har redan pratat om två olika typer av exempel där sociala medier har spelat en roll. Att hålla koll på vad som händer, vad som talas om och hur människor uppfattar dem skulle ge både företagen och människorna en bättre förståelse för hur man ska agera i framtiden. Varför? Tänk på de gånger då folk delade videor om dålig kundservice, eller tänk på den gången då Starbucks oavsiktligt sponsrades efter att några personer hade sett muggarna i några scener, eller när flygbolag fick dåligt rykte för överbokade flyg.
Det här är bara några av de välkända och mest använda exemplen på sentimentanalys. Om du gräver djupare kan du hitta många, som till exempel recensionsanalys för e-handelsbutiker, eller hur Mckinsey utvecklade ett sentimentanalysverktyg som heter City Voices för stadsplaneringsavdelningen i Brasilien. Du kan alltid skapa ett nytt användningsfall också.
Vill du veta vad Retail 4.0 innebär för teknikbranschen?
Med e-boken förstå nästa era av detaljhandelsrevolutionen och dess drivande teknologier.
Lovar, vi närmar oss slutet av den här diskussionen, men istället för att gå den vanliga vägen att prata om fördelarna med sentimentanalys, skulle jag vilja ta några sekunder av er tid till att prata om utmaningarna. (Självklart kommer det att finnas utmaningar när vi försöker få en maskin att förstå känslorna bakom toner och texter).
Ironi och sarkasm: Morbius återutgivning är ett levande exempel på detta. Tror inte att vi behöver återkomma till detta igen! Vi behöver en Chandler som tränar datan.
Kontext: För någon som har sett Vänner: Vad gör du? Har en annan kontext än för någon som inte gjorde det. Därför kan det krävas lite kontext under databearbetning eller förbehandling av data. Till exempel, Nej! Låter negativt, men när frågan skulle vara: Hatade du det? Då skulle kontexten ha varit positiv.
Jämförelse: A är bättre än B om man förstår det. Men när påståendena bara är bättre än att inte ha någonting kan det vara svårt att klassificera det som ett negativt påstående.
Emojis: Välkommen till 1900-talet där fler än text-emojis talar ett högre språk, särskilt med tweets. Du kan behöva antingen ta bort dem eller tilldela deras Unicode-tecken till känslor separat. Ifrågasätter du vårt påstående? Titta på bilden nedan. Vad är den enda skillnaden mellan de två svaren? En emoji. Den andra visar tydligt sarkasm för en människa, men för en bot. Förmodligen tveksamt, om den inte är väl testad.

Definition av neutral: Denna tagg mitt emellan positiv och negativ kan vara knepig att lösa om inte data är vältränad. Data ska vara objektiva och får inte innehålla irrelevant information, förståelse för önskemål etc.
Tack för att du orkade läsa diskussionen till slutet, hoppas att du hade roligt.
Men sammanfattningsvis vill vi säga att sentimentanalys , opinionsutvinning eller kontextuell analys, vad du än vill kalla det, är viktig, särskilt nu med tanke på den guldgruva av data som finns tillgänglig för organisationer att analysera, och med tanke på att API:er är enklare att integrera och hämta data från.
Vad hindrar dig från att göra detta? Vill du ha hjälp? Kontakta oss idag!