
Sammanfatta detta blogginlägg med:
Redaktörens anmärkning: I en tid där det finns verktyg för allt från datalager och dataanalys till business intelligence, etc., uppstår det största problemet med att integrera alla dessa. Det är vad Data Fabric löser. Lär dig mer om Data Fabric, vilka de viktigaste funktionerna är och hur du kommer igång med det i den här artikeln.
Tänk om det fanns ett lag bestående av spelare som Michael Jordan, LeBron James, Magic Johnson, Larry Bird, Shaquille O'Neal, Kobe Bryant, etc.? Redan tanken låter väldigt spännande, eller hur?
Tänk nu på samma sak för din datahantering – tänk om det fanns ett sätt att kombinera datasjö, dataanalys, AI och visualiseringar? Det är vad Microsoft Fabric gör. Vi ska utforska vilka nyckelaktörer som är involverade i detta och vad deras bidrag är.
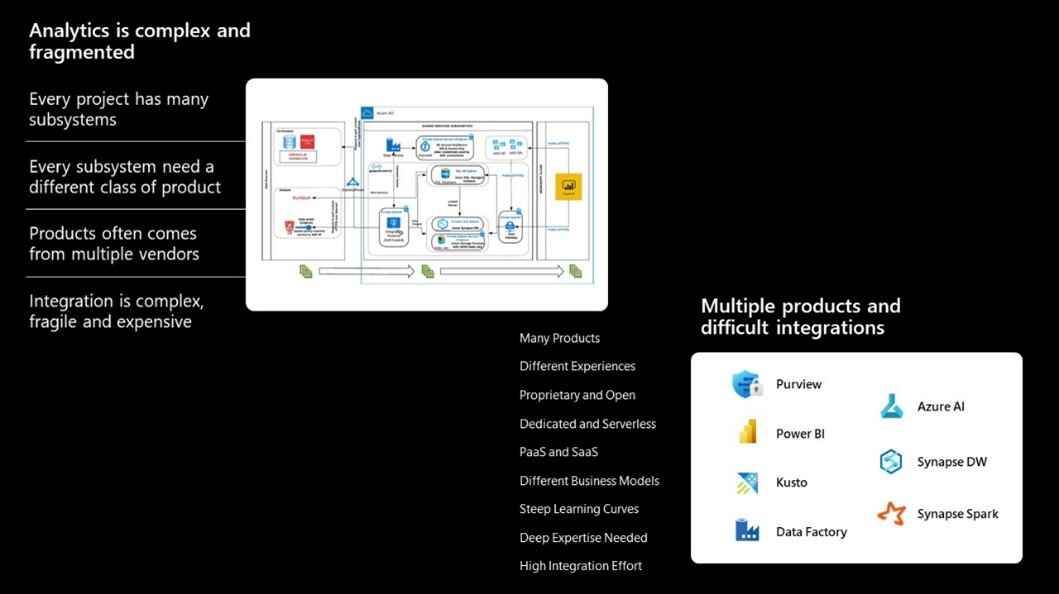
Inte bara behöver flera plattformar användas för en rad olika aktiviteter, från datalagring och transformation, analys och visualisering – utan de komplexa integrationerna och kopplingarna mellan dem gör det hela ännu svårare.
I takt med att organisationer i allt högre grad inser vikten av data, och med 91 % av ledarna som rapporterar ökade investeringar i data och analys1, kommer komplexiteten i datahantering och integration bara att öka. Hur kan man förenkla detta?
Gå in i Microsoft Fabric.
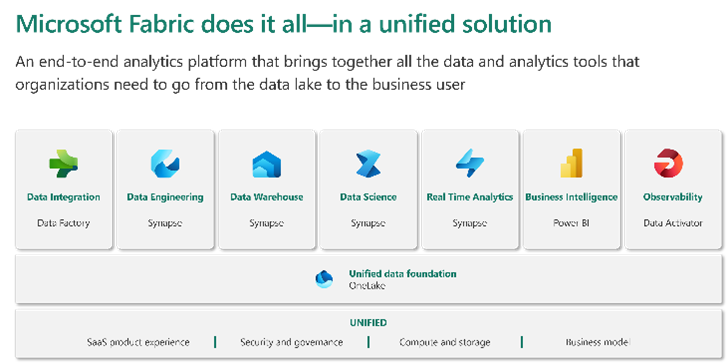
Microsoft definierar Fabric som en allt-i-ett-analyslösning för företag som täcker allt från dataflytt till datavetenskap, realtidsanalys och business intelligence.
Med Satya Nadellas ord är det den bästa plattformsinnovationen sedan SQL Server introducerades. Även om det förmodligen är för tidigt att säga om det är sant eller inte, kan det ses som ett välbehövligt ingripande mot de växande integrationskomplexiteterna.
Det är inte något helt nytt. För Kuroko-fans som inte gillar att spela basket är det som att skapa teamet Generation of Miracles (Vorpal Swords). Hur som helst är syftet att frigöra det affärsvärde ni förväntar er och uppnå mer med mindre genom att förena era hybrid- och multimolndata för snabbare, sammankopplad intelligens. Här är några fördelar med att använda Microsoft Fabric som ert dataekosystem:
100 % SaaS-baserat
Idén med SaaS-ifiering är att göra saker och ting mindre tekniska och mer tillgängliga för personer som inte behöver oroa sig för hårdvara, infrastruktur eller administration. Enligt Gartners forskning kommer 75 % av organisationerna år 2026 att anta en digital transformationsmodell baserad på molnet som den grundläggande underliggande plattformen. Det enklaste sättet att förklara detta är att Microsoft Fabric kommer att vara lika enkelt som att etablera en Power BI-arbetsyta.
Sjöcentrerad
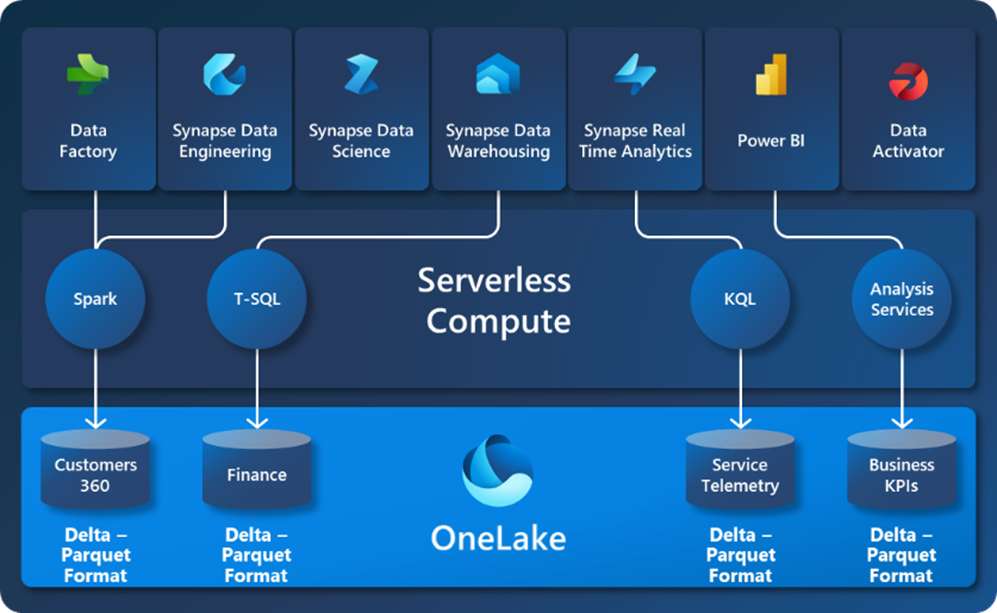
OneLake är hjärtat i Microsoft Fabric. Det är det centraliserade arkivet där Fabrics data och arbetsbelastningar lagras. Det är en multimolnbaserad datasjö där data från datalager och andra datasjöar bevaras i ett gemensamt Delta Parquet-format. Detta gör det möjligt att optimera alla serverlösa beräkningsmotorer i Microsoft Fabric och låter externa resurser skriva data till din OneLake i ett lättförståeligt format.
Det enklaste och vanligaste sättet att förklara det: OneLake är OneDrive för din organisationsdata. När data har lagrats i Lake är de direkt tillgängliga för alla sökmotorer utan behov av import/export och indexeras automatiskt för identifiering, MIP-etiketter, härkomst, PII-skanningar, delning, styrning och efterlevnad.
Kostnadsreducerande
Några anledningar till varför kostnaderna för företagsmoln ökar är datorkostnader, dataöverföring, hämtningskostnader, integrations-, underhållskostnader etc.
Med One Lake och Data Fabric kan du avsevärt minska slöseri med beräkningsresurser och integrationsavgifter eftersom flera leverantörer är tillgängliga under ett enda fönster och beräkningskapaciteten kan användas av en annan arbetsbelastning.
Du kan också minska dataförflyttningen på din plattform och därmed minska kostnaderna samt förenkla din dataorkestrering. Och du behöver inte oroa dig för dataintegration och underhåll eftersom det är SaaS-baserat.
Stärker användare inom alla domäner
Microsoft Fabric är djupt integrerat i Microsoft 365 för att ge användare tillgång till data i realtid och från samma plats. Dessutom är varje roll utrustad med en uppsättning personliga analysverktyg som hjälper dem att självständigt generera insikter i realtid.
Med en hub-and-eker-data mesh-metod som bortser från arbetsytor och artefakter kan du analysera, blanda och omvandla data utan dataförflyttning.
Lågkod och professionell utvecklare
Förutom att ha lite till ingen kod, ger Fabric-miljön ett mervärde för utvecklare. Spark-baserad funktionalitet i VS-kod, Git-integration och anteckningsböcker med bättre samarbetsfunktioner är ett bra tillskott. Jämfört med Synapse, som tar ungefär 3 till 4 minuter, skulle det i Fabric ta ungefär 20 till 30 sekunder att installera Spark-infrastrukturen.
Idén med low-code är att ge slutanvändarna möjlighet att fortsätta med sina analyser utan behov av Synapse /Spark-utvecklare. Det är en win-win-situation där utvecklarna kan fokusera på data, kodning och administration medan affärsanvändarna kan utföra sina analyser.
AI-driven
Med Azure Open AI integrerat i Microsoft Fabric på varje lager kan användare utnyttja kraften i generativa AI- tekniker där det behövs. Med Azure Copilot kan användare bygga maskininlärningsmodeller och datapipelines, generera kod och visualisera resultat i konversationsspråk. Copilot kan till exempel omvandla ord till dataflöden och datapipelines för att hjälpa användare att integrera data varifrån som helst. För användare som skriver kod kan Copilot automatiskt föreslå kod och hela funktioner i realtid i sin redigerare.
Sömlös integration
Fabric tillhandahåller ett enhetligt centraliserat datalager (baserat på ADLS Gen 2) med data från flera källor och plattformar. Data från ADLS Gen 2, AWS S3 och Google Storage (kommer snart) kan länkas direkt via en virtualiseringsfunktion som kallas "genvägar".
Integreras inte bara med datasjöar och datalager, utan kan även integreras sömlöst med Microsoft 365-appar som Excel, PowerPoint, Teams, Outlook etc., och analysplattformar som Power BI.
Utöver dessa, eftersom hela arkitekturen och data är baserade på Microsoft Security och styrning är en självklarhet, pratar vi inte om det i detalj. Nu när du förstår fördelarna som Microsoft Fabric erbjuder, låt oss dyka in i de komponenter som vi fortsätter att prata om och hur alla dessa bildar en sammanhängande plattform med Fabric.
Redan före Microsoft Fabric kunde man göra datatransformation och -analys med flera Microsoft-applikationer som dataintegration med Data Factory, datateknik med Spark, datalager med Synapse DW, realtidsanalys med Kusto, datavetenskap med Azure ML och Business Intelligence med Power BI.
Men magin med Fabric är att du kan göra allt detta och lägga till observerbarhet i mixen genom att utnyttja tre välkända aktörer: Data Factory, Synapse och Power BI – kombinerat med en ny aktör: Data Activator. Om vi fortsätter vår basketanalogi och skapar – ”Drömlaget”.
Azure Data Factory: För en modern, kodfri och autonom ETL-dataintegrationsupplevelse används Data Factory för att hämta, förbereda och transformera data från flera datakällor, som databaser, lager, datasjöar, sjöhus, realtidsdata etc. Detta görs vanligtvis med två primära Data Factory-implementeringar på hög nivå, nämligen dataflöden (för att utnyttja mer än 300 transformationer) och datapipelines (för att utnyttja de färdiga, omfattande dataorkestreringsfunktionerna).
Azure Synapse: Microsoft Fabric använder Synapse-miljön för datateknik, datalager, datavetenskap och realtidsanalys. Detta gör det möjligt för dataingenjörer att omvandla data för att stödja analys baserad på Spark i kombination med ett SQL-baserat datalager som helt separerar beräkning från lagring, vilket möjliggör oberoende skalning av båda komponenterna. För observationsdata i realtid, främst i JSON- eller textformat med skiftande scheman med Kusto Query Language, eller KQL. För datavetenskap kan du börja direkt från problemidentifiering till att få insikter baserade på Apache Spark och Python för dataförberedelse till SynapseML för skapande av massivt skalbar maskininlärningspipeline.
Power BI: Det finns ingen anledning att presentera vad Power BI är. Även år 2016 hade de fler än 5 miljoner prenumeranter – just nu skulle antalet ha vuxit exponentiellt. Med Power BI kan användare bygga och skala upp en datahubb över hela organisationen med kraftfulla visuella element och analyser. Användare kan förstå data, skapa rapporter och dela insikter med hjälp av konversationsspråk och ansluta mellan flera Microsoft 365-appar.
- Mervärde med Co-pilot: Användare kan helt enkelt beskriva de visuella element och insikter de letar efter så gör Copilot resten. Användare kan skapa och skräddarsy rapporter på några sekunder, generera och redigera DAX-beräkningar, skapa narrativa sammanfattningar och ställa frågor om sina data, allt på ett konversationsspråk.
Data Activator: För bearbetning av strömmar i realtid genom ett detekteringssystem som automatiskt meddelar ditt team med relevant information. Data Activator (för närvarande endast i förhandsvisning) tillhandahåller dataövervakning i realtid för att koordinera mänskliga och automatiserade åtgärder, som att ställa in konfigurerbara varningsvillkor som automatiskt utlöser svar i olika system som team, Outlook etc., allt i en kodfri upplevelse. 
”År 2026 kommer 70 % av organisationer som framgångsrikt tillämpar observerbarhet att uppnå kortare latens för beslutsfattande, vilket möjliggör konkurrensfördelar” på marknaden. På grund av detta finns det en stor möjlighet att bygga mer mogna data- och analysfunktioner inom – och över – er verksamhet.
Källa: De viktigaste strategiska teknologitrenderna
Efter att ha läst allt detta kanske du undrar. Om alla dessa fanns tidigare (exklusive Data Activator), hur skiljer sig Microsoft Fabric från befintliga plattformar som Azure Synapse eller Data Factory?
För att utveckla detta måste vi prata om två saker: För det första, hur detta skiljer sig från Synapse, och för det andra, hur OneLake spelar en viktig roll.
Utveckling från Azure Synapse
Istället för att titta på båda separat, bör Microsoft Fabric ses som efterträdaren till Synapse (precis som Synapse var efterträdaren till SQL Data Warehouse) .
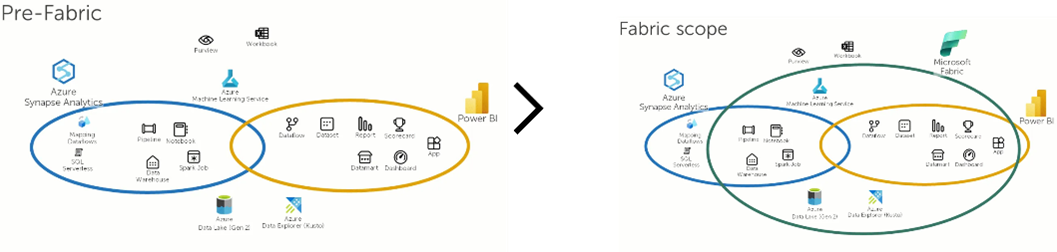
Här är en direkt jämförelse mellan funktionerna i Synapse och Fabric:
| Befintlig synapsfunktion | Tygfunktion |
|---|
| SQL Serverlös | SQL-slutpunkt |
| SQL Dedikerad (SQL Data Warehouse) | Lager |
| Apache Spark-pooler | Hanterade Spark-pooler |
| Apache Spark-anteckningsböcker | Anteckningsbok |
| Apache Spark-jobb | Definition av Spark-jobb |
| Data Explorer (KQL-skript) | KQL-frågeuppsättning |
| Data Explorer-databas | KQL-databas |
| Synapslänk | Inte ännu tillgänglig i tyg. |
| Synapse Studio | Ersatt av ett nytt Power BI-baserat gränssnitt. |
| Git-integration | Git-integration |
| ML / MLOps | Datavetenskap |
| Kartläggning av dataflöden | Stöds inte av Fabric. |
| Rörledningar | Datapipelines |
Vi pratade om OneLake för ett tag sedan, men vi ville belysa vikten av det och hur denna till synes lilla förändring faktiskt är ryggraden i Microsoft Fabric (och Microsoft Purview).
Några av de viktigaste funktionerna inkluderar:
- All data är organiserad i ett intuitivt hierarkiskt namnutrymme
- Alla arbetsbelastningar lagrar automatiskt sina data i OneLake-arbetsytans mappar
- Data indexeras automatiskt
- Data lagras i ett enda gemensamt format – Delta Parquet, vilket alla serverlösa motorer har optimerats för att fungera med.
- När data lagras i sjön är de direkt tillgängliga för alla motorer utan behov av import/export.
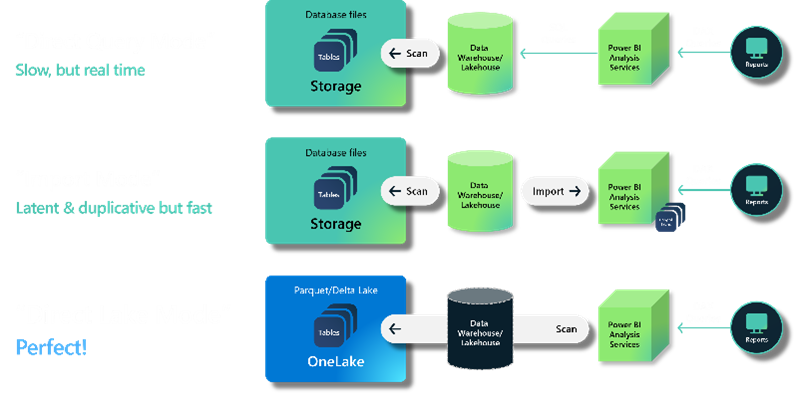
Källa: Microsoft
Kort sagt, du kan eliminera integrationsproblemen mellan applikationer och få en datasjö som innehåller all information, dvs. att dela data i OneLake är lika enkelt som att dela filer i OneDrive, vilket eliminerar behovet av dataduplicering. Om det behövs anpassade data/applikationer kan de nås direkt med stöd för branschstandardiserade API:er.
Nu till den sista frågan.
Var ska man börja?
Du kan enkelt komma igång med en 60-dagars provperiod av Microsoft Fabric med Power BI. I den här förhandsvisningen får du tillgång till alla Fabric-upplevelser och funktioner med OneLake-lagring på upp till 1 TB. Du kan läsa mer om det här. Eller så kan du bara skicka ett meddelande till oss så hjälper vi dig att konfigurera din Fabric-process och guidar dig genom alla funktioner.
Synopsis: En allt-i-ett-analyslösning med en SaaS-grund
Microsoft Fabric kombinerar Data Factory, Synapse Analytics, Data Explorer och Power BI till en enda, enhetlig upplevelse i molnet. Den öppna och styrda Data Lakehouse-grunden är en kostnadseffektiv och prestandaoptimerad struktur för Business Intelligence, maskininlärning och AI-arbetsbelastningar i alla skalor. Det är grunden för att migrera och modernisera befintliga analyslösningar, oavsett om det är dataenheter eller traditionella datalager.
1. Finns det en direkt uppgradering/koppling för att flytta från Synapse till Fabric?
Nej, det finns ingen direkt uppgraderingsväg eller kopplingar som automatiskt kan migrera dina data. För att flytta dina Synapse-arbetsbelastningar till Fabric måste du manuellt migrera och ändra kod, inklusive men inte begränsat till anteckningsböcker, SQL-skript och pipelines, för att den ska kunna köras.
2. Hur hanterar Microsoft Fabric dataintegration från flera källor?
Microsoft Fabric erbjuder sömlös integration med olika datakällor, inklusive databaser, datasjöar, molntjänster och till och med realtidsströmmande data genom att lagra all data i OneLake i Delta Parquet-format. Det innebär att användare och appar kan komma åt data från samma plats, vilket eliminerar behovet av import och export.
3. Är det obligatoriskt för Azure Data-kunder att flytta till Microsoft Fabric?
Nej, Microsoft Fabric är inte obligatoriskt för kunder som har etablerat Azure Data Services. Kunder kan välja att flytta sin befintliga dataarkitektur och sina tjänster till Microsoft Fabric – men med tanke på kostnadsfördelen och den effektivitet det ger vore det ett logiskt val att uppgradera eller åtminstone få förhandsvisningen.