
Sammanfatta detta blogginlägg med:
För varje dag som går står organisationer runt om i världen inför utmaningar kring datahantering – mycket mer än någonsin tidigare. Sedan användningen av data började på 1980-talet har mycket förändrats, särskilt med molntjänsternas framväxt, vilket har medfört massiva förändringar i hur data används, konsumeras och förstås.
Idag genereras datamängder varje sekund, och det är av yttersta vikt att hitta lagringslösningar för dessa enorma volymer. När det gäller att hantera data överväger datahanterare och yrkesverksamma att använda antingen datalager eller datasjöar som arkiv.
Så, vad betyder dessa termer, vad skiljer dem från varandra, och vilken är den bästa lösningen för din organisation?
Här fördjupar vi oss i likheterna och skillnaderna mellan datalager och datasjöar, med avsikt att lösa några frågor för företag med tanke på de begränsningar de står inför när det gäller sin miljö och sina budgetar.
En datasjö är ett system eller arkiv av data som lagras på ett ostrukturerat sätt och i sitt naturliga/råa format; dvs. den bearbetas eller analyseras inte. En datasjö gör det möjligt för organisationer att lagra högar av olika datamängder utan att först behöva bygga en modell.
Det är vanligtvis en enda lagringsplats för all företagsdata, inklusive råa kopior av källsystemdata och transformerad data som används för uppgifter som rapportering, visualisering, avancerad analys och maskininlärning.
Tänk på det så här, en datasjö kan förstås som en stor vattenmassa, säg en sjö i sitt naturliga tillstånd. Datasjön skapas med dataströmmar från olika källor, och sedan kan olika användare komma till sjön för att undersöka den och ta prover.
En datasjö kan innehålla strukturerad data från relationsdatabaser (rader och kolumner), semistrukturerad data (CSV, loggar, XML, JSON), ostrukturerad data (e-postmeddelanden, dokument, PDF-filer) och binär data (bilder, ljud, video). Det är särskilt användbart när datahanterare letar efter sätt att samla in och lagra data från en mängd olika källor i olika format. I många fall anses datasjöar vara kostnadseffektiva och används med avsikt att lagra data för utforskande analys.
Ett datalager , å andra sidan, samlar all din data och lagrar den på ett organiserat/strukturerat sätt. Det hjälper till att konsolidera data på ett ställe med avsikten att få fram verkliga affärsinsikter som sedan kan användas för att fatta bättre affärsbeslut – det hjälper dig i huvudsak att få värde från informationen.
När användningen av data har identifierats laddas den sedan in i ett datalager, vilket sedan gör det möjligt för organisationer att få insikter genom analytiska dashboards, operativa rapporter och/eller avancerad analys.
Datalager förbättrar helt enkelt kvaliteten på affärsintelligens , så att chefer inte längre behöver fatta affärsbeslut baserat på begränsad/begränsad data eller baserat på sin magkänsla.
Med alla typer av data lagrad på ett ställe gör datalager det möjligt för organisationer att snabbt fatta välgrundade beslut om viktiga initiativ.
På senare tid har det skett en ökning av diskussioner om både datalager och datasjöar, där folk försöker förstå fördelarna med båda, och till och med hur de delar företagsfasen. Det handlar inte om att ställa det ena mot det andra, utan snarare om att förstå hur båda kan fungera tillsammans.
FÖRSLAG PÅ LÄSNING: DATA LAKES VS DATA WAREHOUSE! VILKA ÄR SKILLNADERNA?
Datakällor: Datakällor är där originaldata, en mängd olika interna och externa källor, finns. Det kan antingen vara operativa datakällor som ERP, CRM etc. eller data från sociala medier som webbplatsbesök, innehållspopularitet etc. eller till och med tredjepartsdata som demografi, undersökningar, folkräkningar etc. eller till och med icke-strukturerad data som bilder, videor etc.
Rå-/landningslager: Data extraheras från olika källsystem och lagras i ett råformat i landningslageret i datasjön. Landningslagret taggar datan för källsystemet.
Standardiserat lager: Eftersom data finns i olika format (relationella, JSON, binära, etc.) måste data standardiseras till rad- och/eller kolumnformat. Detta lager omvandlar också data och tillämpar affärslogik.
Kuraterat lager: Detta lager skapas enligt affärskrav och kan innehålla datamarts för rapportering och analys. Det kan innehålla avnormaliserad data för dataforskare, beroende på vem som har åtkomst till det kuraterade lagret.
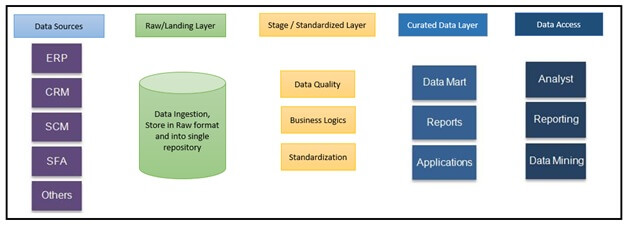
Till skillnad från datalager följer datasjöar ELT-metoden eller extraherings- och loadtransform-metoden. Så här fungerar det:
Dataextraktion och inläsning: Extraktionsaktiviteten för källdata inkluderar dataextraktionsrutiner som läser data och flyttar den till ett landningsområde i ett format. Dataextraktionsprocessen är indelad i:
- Läsa data från systemen – Anslut till olika system via kopplingar eller API-anrop för att komma åt data;
- Tagga inkommande källdata – Inkommande data från olika källsystem taggas så att de kan hänvisas till i framtiden.
Datatransformation: Detta inkluderar datarening, datastandardisering, affärslogik etc.
Kvaliteten (perfektion, validitet och noggrannhet) hos informationen bör dimensioneras och underbyggas så att beslutsfattarna kan utvärdera informationens tillförlitlighet och först därefter besluta vilka åtgärder som ska vidtas.
Data från olika källor kan komma i olika format som är standardiserade till tabellformat för rader och kolumner, t.ex. genom att konvertera JSON-data till tabeller. Affärslogik tillämpas enligt krav. Data lagras i ett kurerat lager från vilket data är tillgängligt för alla enligt krav.
Tänk på dataarkitektur som en herdepaj eller en lasagne – med lager. Varje lager spelar en roll, i det här fallet – i att omvandla rådata till värdefull data redo att användas för konsumtion – analys och business intelligence. För att rådata ska bli värdefull måste den gå igenom en process av lagerläggning, sortering, strukturering och rensning, först då når den mest relevanta informationen toppen. Ett datalager gör i huvudsak detta möjligt.
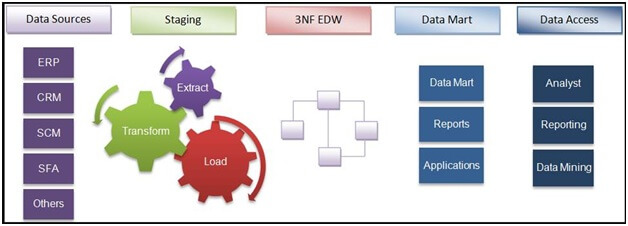
Datakällor: Datakällor är där originaldata, en mängd olika interna och externa källor, finns. Det kan antingen vara operativa datakällor som ERP, CRM etc. eller data från sociala medier som webbplatsbesök, innehållspopularitet etc. eller till och med tredjepartsdata som demografi, undersökningar, folkräkningar etc. eller till och med icke-strukturerad data som bilder, videor etc.
Staging-lager: Data behöver extraheras från olika källsystem och sedan hamna på staging-lagret. I EDW är staging-lagret Truncate Load Staging Layer där inkrementella data behöver extraheras från källsystemet.
Transformation: Data behöver transformeras enligt datamodell och affärslogik. Det är viktigt att notera att transformationslager kan variera från system till system och från krav till krav.
Laddar: Transformerade data måste sedan laddas in i EDW enligt bästa praxis och krav.
Data Marts: Data Marts skapas ovanpå EDW för att matcha rapporteringskraven och för att få bästa möjliga prestanda vid rapportering.
Bästa praxis eller beslut att fatta för datalager:
- Ha en datamodell
- Sätt ihop ett dataflödesdiagram
- Bestäm tidsvariantegenskaper eller attribut
- Anta en erkänd standard för datalagerarkitektur enligt krav, såsom 3NF, Star Modelling, etc.
- Överväg att använda en agil datalagermetodik
Datalager följer ETL- eller Extract transform load-metoden. Så här fungerar det:
1). Dataextraktion: Extraktionsaktiviteten för källdata inkluderar dataextraktionsrutiner som läser data, konverterar dessa data till ett mellanliggande schema och flyttar dem till ett område, vilket är ett tillfälligt arbetsområde där data underhålls i mellanliggande scheman. Dataextraktionsprocessen är indelad i:
- Läsa data från systemen – anslut till olika system via Connectors eller API-anrop för att komma åt data
- Att fastställa ändringar för att identifiera nya data, dvs. att identifiera data som ska laddas in i DW:n, minskar dramatiskt mängden data som kommer att migreras till den. Modifierade datainsamlingstekniker kan delas in i två allmänna kategorier: statiska och inkrementella. Statisk datainsamling förknippas vanligtvis med att ta en ögonblicksbild av data vid en viss tidpunkt. I vissa fall kan hela datamängden återställas, men förmodligen kommer endast en delmängd att användas. Å andra sidan är ökad datainsamling en tidsberoende modell för att fånga ändringar i operativsystem. Denna teknik tillämpas bäst under omständigheter där dataförändringen är betydligt mindre än datamängdens storlek under en viss tidsperiod. Tre olika tekniker kan tillämpas: insamling, triggerbaserad insamling och insamling av transaktionslogg.
- Generaliseringsnyckeln är en nyckelhanteringsapplikation som måste implementeras. Operativa ingångsväxlar behöver vanligtvis omstruktureras innan inspelning. Mycket sällan förblir en ingångsnyckel oförändrad när den läses i operativmiljön och skrivs in i datalagermiljön. I enkla fall läggs ett tidselement till i nyckelstrukturen. I komplexa fall måste hela ingångsnyckeln genomgå en ny hashprocess eller omstruktureras;
- Kombinera poster från flera källor: I de flesta datalager kommer informationen från flera olika och oberoende källsystem. I sådana fall blir det nödvändigt att etablera en mellanliggande datalagringsmiljö.
2). Datatransformation: Detta är en av de viktigaste processerna i ETL. Datatransformation inkluderar även datarensning. Kvaliteten (perfektion, validitet och noggrannhet) på datalagerdata bör dimensioneras och informeras så att beslutsfattarna kan utvärdera datatillförlitligheten och först därefter besluta vilka åtgärder som ska vidtas.
De vanligaste typerna av smutsdata är:
- Dummyvärden
- Brist på data
- Flerfunktionella fält
- Inkonsekventa uppgifter
- Återanvändning av primärnycklar
- Icke-unika identifierare
De andra datatransformationerna inkluderar:
- Byt namn enligt logiska namn snarare än tekniska namn
- Sammanslagning av två datamängder
- Avnormalisering av dimensioner
3). Datainläsning: Efter att datatransformationen har utförts följer inläsningsprocessen – där informationen placeras på datalagerservern. När informationen finns i EDW skapas specifika datamarts enligt rapporterings- eller affärskrav.
Datasjöar och datalager är två sidor av samma mynt – de är olika verktyg som används för olika syften – beroende på vad en organisation försöker uppnå. Datasjöar lagrar all data, medan datalager lagrar rengjord, bearbetad och strukturerad data.
Datasjöar är kostnadseffektiva och relativt enkla att göra ändringar i, medan det är svårare att göra ändringar i strukturen i ett datalager, helt enkelt på grund av antalet lager och processer som är kopplade till det.
I slutändan, i takt med att företagsdata blir mer mångsidig, har organisationer möjlighet att välja vad som fungerar bäst för dem, och förstå de funktionella aspekterna av både lager och sjöar och arbeta mot en modell som får det bästa av båda för dem.
Den snabba takten i vilken företag antar en data-first-strategi för att leda sin digitala transformation drivs av dataanalys. Kompetenta datametoder kommer till användning för att åtgärda de saknade bitarna för organisationer som står inför begränsningar, fördomar och misslyckanden.
När det gäller implementering av datalager och datasjöar har var och en förmågan att bidra till att omvandla operativa, historiska och till och med realtidsdata för att förbättra effektiviteten, förbättra affärsprestanda och så småningom förbättra kundupplevelsen.
Medan många organisationer fortfarande kämpar med att experimentera med datalager och datasjöar, har det blivit ett standardkrav för organisationer att anpassa sig till den ständigt föränderliga dataanalysmiljön.
Sammantaget finns det mycket optimism kring analys inom en snar framtid, där vi kommer att se organisationer i alla spektrum och storlekar integrera det i sin dagliga affärsverksamhet.
I slutändan hoppas vi på Polestar kunna ge organisationer inom olika branscher tillgång till kraften i data och hjälpa dem att analysera miljarder datapunkter och datamängder för att ge insikter i realtid och göra det möjligt för dem att fatta viktiga beslut för att expandera sin verksamhet.
Håll dig uppdaterad om dina favoritämnen