
Sammanfatta detta blogginlägg med:
Redaktörens anmärkning: Förstå hur Data Mesh-arkitekturer kan undanröja hinder för det centrala datateamet och införa en decentraliserad metod som gör det möjligt för team att själva utföra domänöverskridande dataanalyser.
Enligt Gartner kommer endast 20 % av dataanalysprojekt att leverera affärsresultat. Med tanke på att de nuvarande dataarkitekturerna behöver vara bättre rustade för att hantera datas allestädes närvarande och alltmer utmanande sammankopplade natur är detta inte förvånande. Så, i ett försök att ta itu med detta problem, kvarstår frågan i varje företags styrelserum – hur kan företag på rätt sätt bygga dataarkitektur för att intensifiera dataeffektiviteten för den växande komplexiteten hos data och dess användningsområden?
Data mesh-konceptet, som först definierades 2018 av Zhamak Dehghani , är det senaste tillvägagångssättet för företagsdataarkitektur med syfte att ta itu med traditionella dataplattformars fallgropar. Företag som söker en dataarkitektur som möter deras ständigt föränderliga dataanvändningsfall bör överväga data mesh-arkitekturen för att driva sina affärsarbetsbelastningar och analyser.
Data Mesh är ett relativt nytt sätt att hantera data i stora, komplexa organisationer. Enkelt uttryckt innebär det att bryta ner datasilos och organisera data på ett mer decentraliserat och samarbetsinriktat sätt.
Tanken bakom Data Mesh är att data ska behandlas som en produkt, med ägarskap och ansvar fördelat över hela organisationen. Istället för att ha ett centralt team som hanterar all data för organisationen, är varje team eller avdelning ansvarig för den data de skapar och använder.
Låt oss till exempel säga att du arbetar för ett stort e-handelsföretag. I den traditionella metoden kan det finnas ett centralt datateam som ansvarar för att hantera all kunddata, produktdata och transaktionsdata för hela organisationen. Men med en Data Mesh-metod skulle varje avdelning vara ansvarig för att hantera data relaterad till sitt specifika område.
Så kundtjänstavdelningen skulle ansvara för att hantera kunddata, produktteamet för att hantera produktdata och ekonomiteamet för att hantera transaktionsdata. Var och en av dessa team skulle skapa sina egna dataprodukter, såsom en kunddatabas eller en produktkatalog, och göra dessa produkter tillgängliga för andra team inom organisationen.
Genom att bryta ner datasilos och fördela ägarskap och ansvar är tanken att data enklare kan hanteras och delas inom hela organisationen, vilket kan leda till bättre samarbete, snabbare beslutsfattande och mer innovation.
Vill du få värde från data i stor skala?
Vi hjälper dig att driftsätta företagsklassade lösningar för dina kritiska data för att frigöra den verkliga potentialen hos företagsdata.
Här är tabellen nedan som jämför funktionerna hos traditionella datahanteringsplattformar med data mesh-arkitekturer.
| Traditionella datahanteringsplattformar | Data Mesh-arkitektur |
|---|
| Betjäna ett centraliserat datateam som stöder ett flertal domäner | Betjäna autonoma domänteam |
| Hantera kod, policyer och data som en enda enhet | Hantera kod och pipelines oberoende |
|---|
| Behöver separata stackar för operativa och analytiska arbetsbelastningar | Erbjuder en enda plattform för operativa och analytiska arbetsbelastningar |
|---|
| Centralisera plattformen för optimerad kontroll | Decentralisera plattformen för optimerad skalning |
|---|
| Tvinga fram domänmedvetenhet | Förbli domänagnostisk |
|---|
Istället för att ta data som ett centraliserat arkiv, tillåter ett datanäts decentraliserade natur dataägande till domänspecifika team som kontrollerar, hanterar och levererar data som en produkt, vilket möjliggör enkel åtkomst och sammankoppling av data i hela verksamheten.
Idag kan många organisationers dataanvändningsfall delas upp i analytisk och operativ data. Operativ data representerar data från organisationens applikationers dagliga verksamhet. Till exempel innebär användning av en e-handelsbutik kund-, transaktions- och lagerdata. Denna operativa datatyp lagras vanligtvis i databaser och används av utvecklare för att skapa olika API:er och mikrotjänster för att driva affärsapplikationer.
Operativt kontra analytiskt dataplan
Å andra sidan representerar analytiska data historisk företagsdata som används för att förbättra affärsbeslut. I e-handelsbutiker besvarar analytiska data till exempel frågor som "hur många konsumenter har beställt den här produkten under de senaste åren?" eller "vilka produkter kommer kunder sannolikt att köpa under vintersäsongen?". Analytiska data transporteras vanligtvis från flera operativa databaser med hjälp av ETL-tekniker till centraliserade datalager som lager och datasjöar. Dataanalytiker och forskare använder det för att driva sina analysarbetsbelastningar, och marknadsförings- och produktteam kan fatta effektiva beslut med informationen.

En data mesh-metod förstår den centrala skillnaden mellan de två breda typerna av data och försöker koppla samman dessa två typer av data under en annan struktur – en decentraliserad metod för datahantering.
Ta en titt på Microsofts erbjudande Azure Synapse Analytics, tillsammans med både Data Lake Storage Gen2 och SQL-databas, som centrala komponenter för att implementera en data mesh-arkitektur.
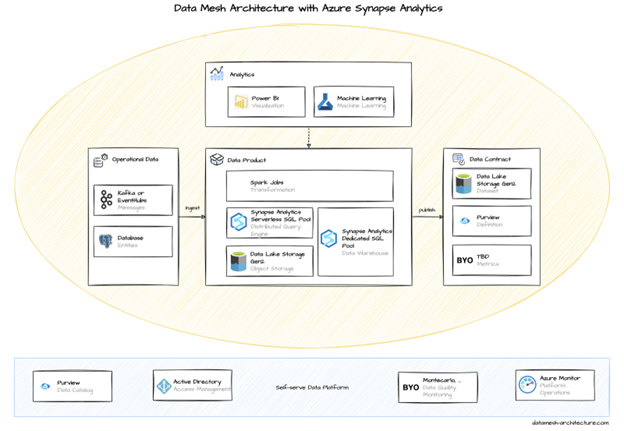
Ett ramverk för datanät bygger på fyra principer som förändrar hur dataanalys möjliggörs i företaget :

Domändrivet ägande och arkitektur
Den främsta principen för ett datanät är att flytta äganderätten och datamakten till domänteamen. De äger data från början till slut – från att säkerställa att de har lämpliga källor eller inmatad data att arbeta med, till att underhålla och bygga eventuella nödvändiga bearbetningspipelines, till att leverera data till andra domänteam att utnyttja som produkter (mer om det senare) med utmärkta kvalitetsgarantier och styrningskontroller på plats. Domänteamen kan definieras av avdelningen, affärsenheten eller andra liknande motiverade grupperingar. Om de implementeras korrekt bör nya domänteam kunna läggas till smidigt och avsevärt när data korreleras till nya dataprodukter.
Data som en produkt
Som antyds i den första principen är domänteam inte bara ansvariga för data och de resulterande dataprodukterna. Och dataprodukter måste behandlas som alla andra produkter. Konsumenter och andra domänteam måste upptäcka och använda dataprodukter. Domänägaren ansvarar för att underhålla och uppdatera (eller avskriva) dessa produkter för att säkerställa noggrannhet och kvalitet. Hur kan detta se ut i praktiken? Tänk dig ett leveranskedjeteam som sammanställer en lagerdataprodukt som marknadsförare kan använda för att utveckla nya rabattkampanjer eller som kan användas av regionala team för att lägga nya beställningar.
Självbetjäningsinfrastruktur
Den tredje principen är att göra all denna självbetjäning enkel för domänteamen. Komplexa teknologier och nischkompetenser är inte hållbara i en data mesh-design. Det krävs en gemensam plattform och uppsättning verktyg som alla domänteam kan använda för att hantera och bygga sina dataprodukter utan att fastna i begränsningar vad gäller infrastrukturresurser eller underhåll.
Federerad styrning
Den sista delen av ett framgångsrikt datanät är styrning. En datanätarkitektur kan inte ske på bekostnad av åtkomstkontroller och dataskydd. Det måste finnas en balans mellan globala styrningspolicyer och kontroller och säkerställa att varje domänteam kan definiera och implementera dessa policyer när de utvecklar och delar sina dataprodukter. Denna federerade styrning är avgörande för att säkerställa datasekretess och efterlevnad samt för att underlätta identifiering i stor skala.
Tillsammans möjliggör dessa principer ett decentraliserat men robust och omfattande dataramverk utformat för att leverera affärsresultat. Den resulterande analytiska dataarkitekturen och verksamhetsmodellen behandlar data som en produkt som kan ägas av de team som har den mest ingående kunskapen om deras konsumtions- och analysbehov.
Ta nu en titt på några av de betydande fördelarna med Data Mesh i bilden nedan.

Att implementera ett datanätverk kan effektivt förbättra din organisations åtkomst till och kontroll över data. Det är dock avgörande att överväga bästa praxis för implementering för att säkerställa att du får ut det mesta av denna teknik.
- Börja med affärsfunktionerna: Identifiera först affärsfunktionerna och deras databehov och utforma datanätarkitekturen kring dem.
- Decentralisera ägarskap: Tilldela dataägarskap till enskilda team, som ansvarar för datakvalitet, säkerhet och styrning.
- Använd domändriven design: Tillämpa domändrivna designprinciper för att skapa domänspecifika dataprodukter som kan användas av andra team.
- Använd API:er för dataprodukter: Skapa API:er för dataprodukter för att göra dem lätta att upptäcka och förbruka.
- Betona datakvalitet: Säkerställ att data är av hög kvalitet genom att implementera datakvalitetskontroller, övervaka datapipelines och ge feedback till dataproducenter.
- Använd en datakatalog: Implementera en centraliserad datakatalog för att tillhandahålla en enda sanningskälla för dataupptäckt. Implementera datasäkerhet: Implementera datasäkerhetspraxis för att säkerställa att känsliga data skyddas från obehörig åtkomst.
- Implementera datastyrning: Implementera datastyrningsrutiner för att säkerställa efterlevnad av regler och standarder.
- Omfamna molnbaserade tekniker: Använd molnbaserade tekniker för att möjliggöra skalbarhet, tillförlitlighet och flexibilitet.
- Främja en datadriven kultur: Uppmuntra en datadriven kultur där data används för att driva beslutsfattande och där data betraktas som en värdefull tillgång.
Genom att följa dessa bästa metoder för att implementera ett datanät kan du därför se till att ditt företag har rätt infrastruktur, mål och behov för att bygga en effektiv datanätlösning.
Hur kan vi hjälpa dig att förändras och växa?
Vår metod kan hjälpa dig att ta in, berika, transformera och hantera data via en centraliserad plattform.
Även om distribuerade datanätarkitekturer fortfarande blir alltmer populära, hjälper de team att uppnå skalbarhetsmål för vanliga användningsområden för stordata. Dessa inkluderar:
Business Intelligence-instrumentpaneler: När nya initiativ uppstår behöver team ofta anpassade datavyer för att förstå resultatet av dessa projekt. Data mesh-arkitekturer kan stödja detta behov av flexibilitet och anpassning genom att göra data mer tillgänglig för datakonsumenter.
Kundupplevelse: Kunddata gör det möjligt för företag att förstå sina användare bättre, vilket gör att de kan erbjuda mer personliga upplevelser. Detta har observerats inom olika branscher, från marknadsföring till hälso- och sjukvård.
Maskininlärningsprojekt: Genom att standardisera domänagnostiska data kan dataforskare enklare sammanfoga data från flera olika datakällor, vilket minskar tiden som läggs på databearbetning. Denna tid kan påskynda antalet modeller som flyttas till en produktionsmiljö, vilket möjliggör uppnåendet av automatiseringsmål.
I takt med att företag samlar in, lagrar och analyserar mer data blir decentraliserat dataägande tydligt. I slutändan är det rätta vägen att gå att lägga tillbaka data i händerna på dem som förstår. Att utveckla en distribuerad självbetjäningsarkitektur med centraliserad styrning kräver kontinuerligt engagemang.
Att övergå från en monolitisk till en distribuerad modell kräver omorganisation av företaget och kulturella förändringar. Ansträngningen är dock värd besväret eftersom detta transformativa paradigm har potential att stärka ett företags datacentrerade vision.
Polestar Analytics är ett ledande IT-konsultföretag som har hjälpt ett flertal organisationer att transformera sina dataoperationer. Datagenerering ökar exponentiellt, och tillgången till monolitiska datamängder blir svårare med tiden. Boka en konsultation idag!