
Sammanfatta detta blogginlägg med:
Symtom finns alltid där, men det krävs en läkare för att "koppla ihop symtomen" och diagnostisera sjukdomen. Bevis finns alltid där, men det krävs en Sherlock för att "bearbeta all den informationen" och lösa pusslet. Dessa, bland många andra, sammanfaller med en viktig punkt – "information är livsviktig, men det behövs intelligens för att den ska bli begriplig".
Idag har tekniken tänjt på gränserna i en sådan utsträckning att människor är de viktigaste mottagarna av den "människoliknande" intelligens som utvinns ur datorer. Det finns namn som – artificiell intelligens, maskininlärning, stordataanalys, prediktiv intelligens och mycket mer. Flera exempellösa problem löses idag – vare sig det gäller hälsa, ekonomiska frågor, företag, social analys eller till och med politiska händelser och valkampanjer.
Inte förvånande är stordataanalys och val nära besläktade, eftersom det omdefinierar hur valkampanjer utformas, vilket bara är en aspekt av historien. Utöver detta bidrar just denna egenskap hos data – att kunna utstråla mening ur den – idag till att kontinuerligt kalibrera kampanjplanering och genomförande i realtid. Här är några exempel på datadriven och maskinbaserad intelligens som förvånansvärt bekräftar datas vitalitet.
Detta sträcker sig från att analysera de senaste trenderna inom sociala medier och sökmotorer till att utföra sentimentanalys av vad folk pratar om och om vem. Till exempel engagemangsanalys för Twitter och Facebook och analysera sentimenten i den enorma mängden massgenererad data från sociala medier.
Till exempel drar exempelbilden nedan slutsatser om länder varifrån varje kandidat får flest tweets under XY-perioden. Den visar också en sentimentanalys av Twitter-omnämnandena av kandidaterna.
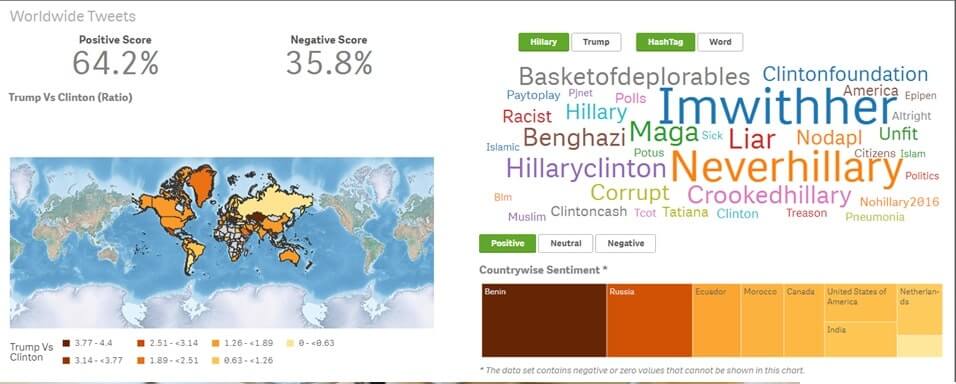
Det är verkligen osannolikt för en människa att sluka hundratals intervjuer och relaterade artiklar och samla in en uppsättning kognitiva och informativa slutsatser. Naturligtvis kan maskiner, när de ska ta en mänsklig roll, göra just det inom en otroligt kort tidsperiod. Att analysera både talbaserade intervjuer och textbaserade transkript kan hjälpa till att härleda aspekter som:
- Omnämnanden av valagenda, andra länder, teman etc.
Flesch Reading Ease Index är ett av de sätt som hjälper till att förstå talkomplexitet och nivån på tal – vilket i sin tur säkerställer att talen är mer populistiska och lämpar sig för att nå en bredare massa.
Att rendera realtids-N-gram, ordmoln, tidsskalade trender och annat är några mycket populära sätt att sortera ut "relaterade" eller "närmast i närheten" ord, vilket hjälper den politiska analytikern att dra rätt slutsatser.
FÖRSLAG TILL LÄSNING: DET KRAFTFULLA LANDSKAPET AV NATURLIG SPRÅKBEARBETNING
# Talanalys
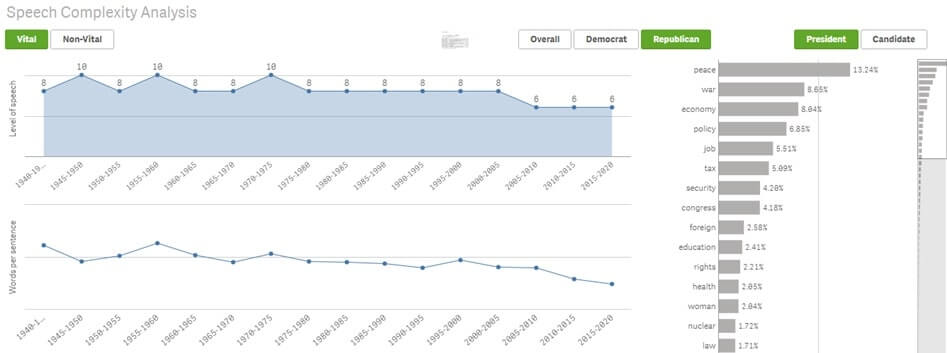
Det finns plattformar och lösningar som kan tråla igenom valrelaterade mediebevakningar och intervjuer och generera en grundlig analys av vilka som är de viktigaste valämnena, vilken kandidat som betonar vilka teman, anpassning och mappning till valmanifestet och vilken som inte.
Till exempel antyder exempelbilden nedan att medan demokraterna har varit mer oroliga över de sociala och ekonomiska faktorerna, har republikanerna varit mer oroliga över USA:s relationer med världen och utrikespolitiken.
FÖRSLAG TILL LÄSNING: Steg för att få värde från stordata
Att lägga till geografiska dimensioner till sentimentanalysen eller andra attribut på sociala medier (omnämnanden, hashtaggar etc.) ger ett starkt verktyg för att härleda den allmänna opinionen i olika regioner eller geografiska områden. Här är till exempel en exempelbild av prognoser för presidentvalet 2020.
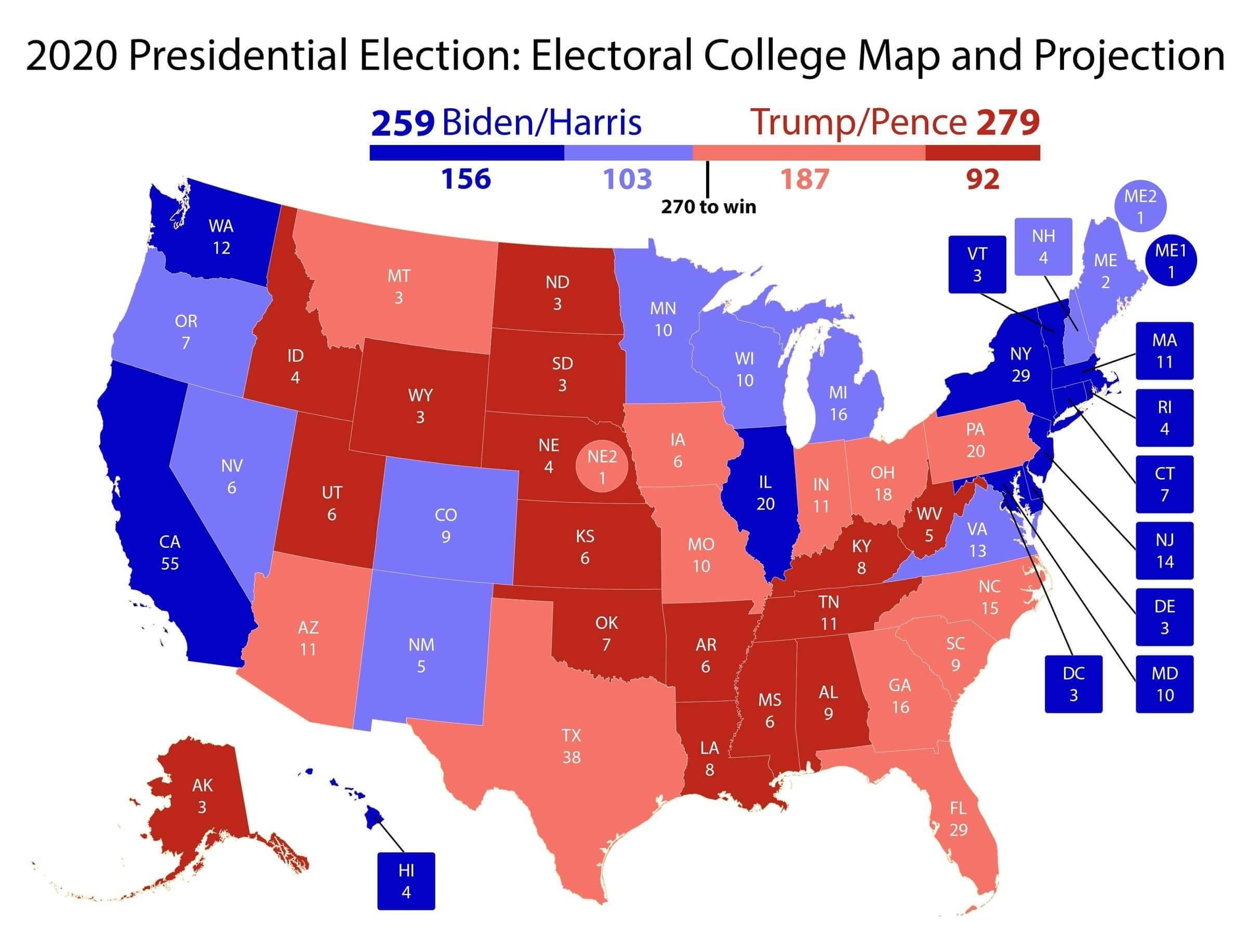
Källa: (PRNewsfoto/Jumptuit)
Data utan möjligheter att dra insiktsfull mening är inget annat än en vit elefant. Det är rimligt att anta att dagens valpartier inte lämnar några stenar ovända när det gäller att använda data och vara lyhörda för de slutsatser som härleds.
Så enkelt som det kan se ut kan styrkan hos big data-analys enkelt sammanfattas som – information föder insikter, insikter föder kunskap och kunskap föder handlingar!