
Sammanfatta detta blogginlägg med:
Lågkods-/ingenkodsplattformar åtgärdar flaskhalsar inom datateknik genom att förenkla integrationer, automatisera transformationer och bädda in styrning i en enda enhetlig dataarkitektur.
- Varför utvecklades LCNC-plattformar (low-code/no-code) från arbetsflödesbyggare till verksamhetskritisk datainfrastruktur?
- De fyra dolda skatterna dataingenjörer betalar när de förlitar sig på frånkopplade dataplattformar istället för enhetliga LCNC-datatekniska lösningar .
- Hur man eliminerar transformationsflaskhalsen med visuella ETL-pipelines som drivs av datatekniska lösningar med låg/ingen kod.
- Det arkitektoniska beslutet som avgör om AI-agenter accelererar eller kringgår din datastack
Om du fortfarande "funderar på att experimentera" med Low Code No Code (LCNC)-plattformar eftersom du ser det som en "framväxande trend", har du misstagit dig.
För bara några år sedan använde mindre än 25 % av de nya företagsapparna lågkod . Idag har den siffran stigit till 80 % . Vad har förändrats, undrar du? Lågkodsplattformar är inte längre bara arbetsflödesbyggare. Vi har gått från kodningspipelines till att orkestrera intelligenta system (tack vare agentisk AI ) som styr sig själva.
Flaskhalsar inom datateknik är inget nytt. Varje ny SaaS-integration innebar veckor av utveckling av anpassade kopplingar. Eller schemaändringar som bröt pipelines utan förvarning. Affärsteam väntade i månader på enkla datatransformationer eftersom allt krävde manuell kodning.
Därför började LCNC-plattformar initialt som verktyg för medborgarutvecklare att använda avdelningsspecifika applikationer. Med tiden mognade några till infrastruktur i företagsklass som kunde hantera komplex automatisering, datademokratisering och nu även AI-driven orkestrering.
Här är vad som förändrades för dataingenjörer: istället för att bygga anpassade kopplingar för varje API konfigurerar ni förbyggda. Istället för att skriva komplex SQL för standardtransformationer använder ni visuella gränssnitt. Istället för manuell övervakning av schemadrift hanterar plattformarna det automatiskt. Ni fokuserar på komplex affärslogik istället för repetitivt integrationsarbete.
Idag ser vi resultaten av denna utveckling. Med plattformar för lågkodsutveckling levererar 61 % av användarna framgångsrikt anpassade appar i tid, inom omfattning och inom budget. Och lågkod visar potentialen att snabba upp mjukvaruutvecklingen med upp till 10 gånger .
Men här är vad de flesta organisationer missar: att veta vart branschen är på väg betyder ingenting om du inte vet var du står just nu.
Lågkod/ingen kod-mognadsmodell: Var står er organisation?
De flesta företag faller inom en av tre mognadsnivåer:
Insatserna spelar roll eftersom varje nivå kräver fundamentalt olika strategier, styrningsmodeller och riskprofiler.
Vet du var du står? Dags att ta reda på vart du är på väg.
Kom igång med en plattform för datautveckling med låg kod
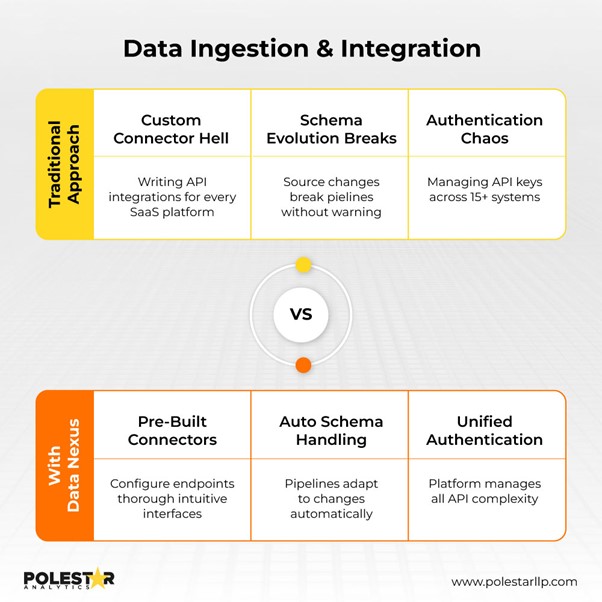
Kom igång med Data Nexus Varje dataingenjör känner till denna verklighet: det som brukade vara ett enkelt ETL-jobb från tre system innebär nu att hantera 15+ API:er, vart och ett med olika hastighetsgränser, autentiseringsscheman och brytande ändringar.
Här är vad du betalar för denna komplexitet:
Den verkliga kostnaden är inte SaaS-prenumerationen; det är ingenjörstimmarna. Varje nytt verktyg kräver utveckling av anpassade kopplingar, hantering av OAuth-flöden och konstant övervakning av schemadrift. Era pipeline-underhållskostnader skalas exponentiellt medan ert team förblir oförändrat.
Teknisk verklighetskontroll:
- API-hastighetsgränser: De flesta SaaS-plattformar begränsas till 100–1000 förfrågningar/minut
- Schemadriftfrekvens-API:er ändrar scheman som inte fungerar inom några månader
- Autentiseringsoverhead: OAuth-tokenhantering ökar utvecklingstiden (beroende på projektets komplexitet)
- Komplexitet vid felhantering: Anpassade kopplingar kräver över 200 rader kod bara för logik vid återförsök
Kostnaden för teknisk skuld ackumuleras snabbare än du kan betala av den.
Data Nexus eliminerar denna integrationsskatt. Genom Nexus ansluter du till vilket system som helst (molndatabaser, ERP:er, platta filer, API:er, datalager) utan anpassad utveckling. Plattformen tillhandahåller förbyggd anslutning som hanterar autentisering, hastighetsbegränsning och schemautveckling automatiskt.
Här är tidsskillnaden. När det gäller att skriva kod och ramverk påskyndar det processen med 70 % . Det betyder att när det gäller uppgiftsval ersätter enkla konfigurationer komplex integrationsutveckling. Och du fokuserar på datatransformationslogik istället för anslutningsoverhead.
Där det finns transformation måste det finnas en flaskhals. Och för datatransformation kan det vara en enkel affärsfråga som: "Hur mycket betalar vi anställda i olika städer?" Tre månader senare brottas du fortfarande med felaktiga scheman och dubbletter av poster.
Det som ser ut som en enkel fråga blir ett integrationsprojekt för flera system – med schemaavstämning, dataduplicering eller kvalitetsvalidering. Var och en av dessa uppgifter kräver specialiserade färdigheter och avsevärd utvecklingstid.
Det är här traditionell datateknik kör fast:
- Skriver oändlig SQL- och PySpark-kod för att hantera edge-fall och deduplicera poster.
- Skapa komplexa mappningstabeller för att avstämma olika data.
- Att börja om när affärsbehoven oundvikligen förändras.
LCNC-plattformar löser detta på ett annat sätt . Drag-och-släpp-transformationer hanterar standardåtgärder som joins, deduplicering och aggregering som konfigurationsalternativ. Du tillämpar affärslogik genom enkla kolumnvillkor utan att skriva kod, vilket gör att du kan lägga tid på komplex affärslogik istället för repetitiv datahantering.
PS Tar nästan 50-70 % av tiden jämfört med manuellt.

Du har löst flaskhalsen i omvandlingen och kan nu svara på "Hur mycket betalar vi anställda i olika städer?" Men här är det djupare problemet: vilken version av "John Smith" är den riktiga?
Behovet av att ha analys- eller AI-klar data är högre än någonsin. Med 1Platforms Data Nexus integrerar vi denna ideologi om att ha analysklar data, genomgående med en medaljongarkitekturbaserad process:
- Data behåller sina ursprungliga format i varje systems bronslager.
- Enhetliga entitetsmappningar i silverlagret genom automatiserade matchningsalgoritmer som inte kräver manuell datahantering.
- Guldlagret ger konsekventa vyer för analyser samtidigt som de operativa datamodeller som avdelningarna faktiskt använder bevaras.
Denna metod hjälper till att förena organisationens övergripande bild av data samtidigt som den förbättrar dess tekniska kapacitet.
Låg kod, ingen kod Data Engineering kan vara lösningen du vill ha för dina data!
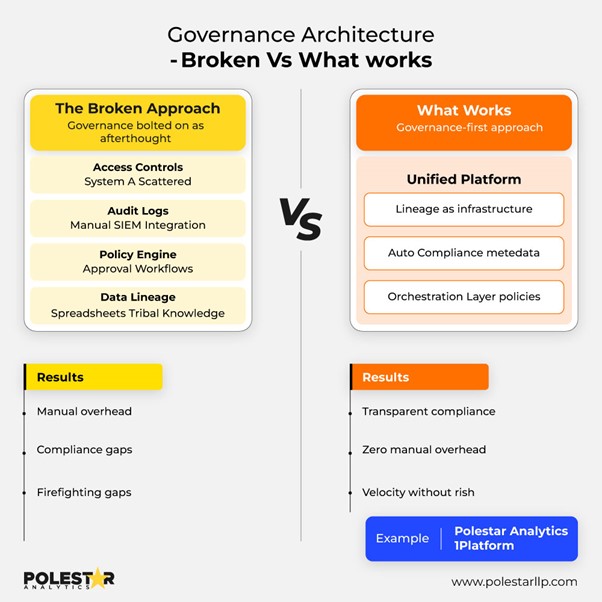
Datastyrning förvandlar dataingenjörer till brandmän. När revisorer frågar efter avstamning, letar man igenom kalkylblad och jagar upp den som byggde den pipelinen. GDPR-förfrågningar innebär att man manuellt letar igenom dussintals system. Affärsteam bygger skuggarbetsflöden, och sedan får IT-avdelningen skulden när compliance upptäcker dem.
Traditionella verktyg sprider styrning över system. Åtkomstkontroller på fem olika platser. Granskningsloggar som kräver manuell korrelation.
LCNC-plattformar som 1Platform centraliserar detta med:
- Linje som visar hela dataflödet från källa till slutrapporter
- Åtkomstkontroller som gäller för alla dataflöden från ett gränssnitt
- Pipelineändringar som godkänns varje gång
- Övervakningsinstrumentpaneler där du spårar statusen för datapipelines
När revisorer ställer frågor frågar ni plattformens metadata istället för att leka detektiv över olika system.
Vi hittade rätt lösning för dina datatekniska behov
Intelligenta plattformar gör styrning till en del av ert tekniska DNA med inbyggd upprätthållning, automatiserad efterlevnad och skalbara åtkomstkontroller.
Upptäck LCNC för datateknik Med 93 procent av IT-cheferna som rapporterar att de har för avsikt att införa autonoma AI-agenter inom de kommande två åren, och nästan hälften har redan gjort det – spelar ert arkitekturbeslut större roll än någonsin.
Det finns inte bara dataagenter som upptäcker schemaändringar, anpassar pipelines automatiskt och löser datakonflikter utan mänsklig inblandning.
Men du skulle också behöva rena data för att låta de branschspecifika agenterna arbeta med maximal effektivitet.
Så dina dataapplikationer, AI-agenter och analyser måste fungera från en enda grund. Inte bara API-kopplingar mellan verktyg – en faktisk arkitektonisk enhet där data flödar från inmatning till AI-bearbetning till automatiserade åtgärder utan att korsa systemgränser.
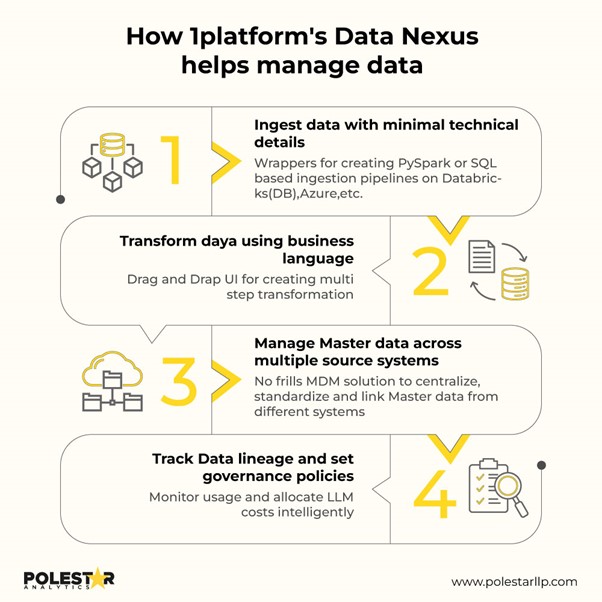 Hur 1Platforms Data Nexus hjälper till att hantera data
Hur 1Platforms Data Nexus hjälper till att hantera data Organisationer som använder Data Nexus och 1Platform idag bygger infrastrukturen för morgondagens autonoma verksamheter.
Skillnaden ligger inte i sofistikeringen – utan i om din arkitektur fungerar för dig eller emot dig. Det handlar om huruvida du bygger på en plattform eller hanterar tio?
Beslutet är ditt.
Ledare bör utvärdera beslutslatens, integrationskomplexitet och teknisk bandbredd. Om team lägger mer tid på att underhålla pipelines än på att leverera insikter blir LCNC strategiskt. Beslutet handlar inte om att ersätta ingenjörer, utan om att omfördela arbete från repetitivt integrationsarbete till högvärdig affärslogik och AI-driven innovation.
Den största risken är att öka den tekniska skulden och sakta ner beslutsfattandet. I takt med att dataekosystem växer skapar frånkopplade verktyg exponentiell underhållskostnad. Detta försenar insikter, minskar förtroendet för data och försvagar AI-initiativ. Ledare måste se implementeringen av LCNC inte som ett verktygsval, utan som ett arkitekturbeslut som påverkar långsiktig skalbarhet.
Chefer bör prioritera plattformar med inbyggd styrning, avstamning och åtkomstkontroll snarare än att lägga till styrning i lager senare. Beslutet bör fokusera på enhetlig synlighet över pipelines och dataflöden. Att integrera styrning i arkitekturen säkerställer att efterlevnaden skalas upp automatiskt istället för att bli en reaktiv, manuell insats.
CIO:er och CDO:er bör prioritera arkitekturmässig enhetlighet, inte bara användarvänlighet. Plattformen måste stödja heltäckande dataflöden – från inmatning till AI-aktivering – inom ett ekosystem. Det viktigaste beslutet är om plattformen möjliggör framtida agentbaserade AI-arbetsflöden eller skapar ytterligare ett frånkopplat lager i datastacken.