 Kshitij GuptaDatastrateg
Kshitij GuptaDatastrateg
Registrera dig för att få de senaste insikterna och uppdateringarna inom teknik, AI och dataanalys, datavetenskap och innovationer från Polestar Analytics.
De flesta datatekniska team inom företag misslyckas inte på grund av brist på verktyg. De misslyckas eftersom de verktyg som ackumulerats under det senaste decenniet aldrig var utformade för att fungera tillsammans.
Ett lager för rapportering. En sjö för skalning. En separat ML-miljö. Ett streaminglager som installerades när batchen inte höll jämna steg. Varje beslut var logiskt vid den tidpunkten. Arkitekturen de producerade tillsammans gör det inte.
Vet du?
- Dålig datakvalitet kostar organisationer i genomsnitt 12,9 miljoner dollar årligen.
- Företag som driver separata sjö- och lagermiljöer spenderar upp till 30 % av sin totala datainfrastrukturbudget på redundant dataförflyttning och lagring – innan de genererar en enda insikt.
Databricks Lakehouse ersätter den fragmenterade stacken med en enda öppen plattform. Den här bloggen går igenom de specifika datatekniska utmaningar som Databricks data Lakehouse-arkitektur löser – och mekanismerna bakom hur den löser dem.
~ Bablu Chakraborty, senior vice VD – Kompetens, Polestar Analytics
Innan man undersöker enskilda utmaningar är det värt att vara exakt om vad Databricks Lakehouse-plattformen är – eftersom den definitionen formar varje implementeringsbeslut nedströms.
Databricks data Lakehouse är inte ett lager med tillagda sjöfunktioner, eller en sjö med påbyggd lagerstyrning. Det är en enda öppen plattform som tillhandahåller transaktionell tillförlitlighet, schematillämpning och frågeprestanda för ett lager samtidigt som skalan, öppenheten och ML-kompatibiliteten hos en datasjö bibehålls. Lakehouse-arkitekturen på Databricks körs på öppna tabellformat – Delta Lake och Apache Iceberg – vilket innebär att det inte finns någon leverantörslåsning på lagringslagret, och varje beräkningsmotor som stöder öppna standarder kan läsa från och skriva till samma tabeller.
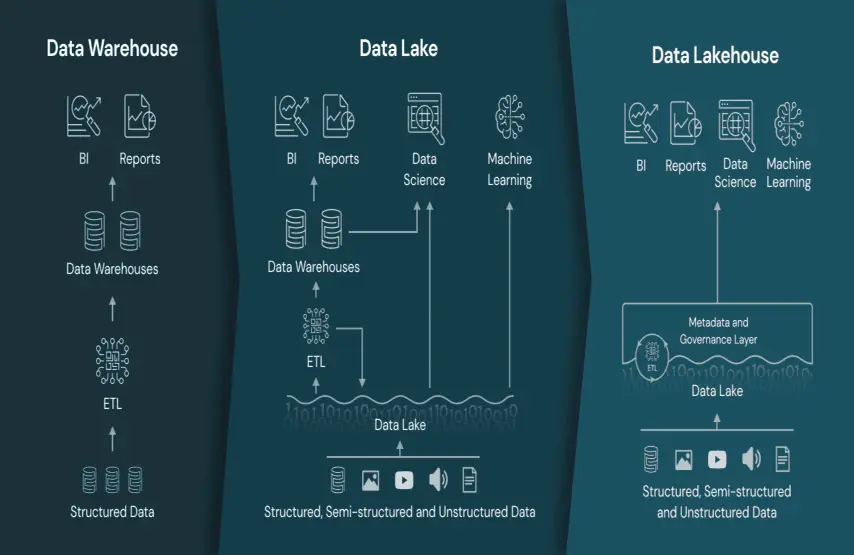
När ett lager och en datasjö samexisterar som separata system, matas samma data in två gånger, transformeras två gånger och kvalitetskontrolleras två gånger – av olika team, vilket producerar olika siffror. Varje ny datakälla multiplicerar denna omkostnad. Det är ett strukturellt problem, inte ett problem med datakvalitet.
Lakehouse Databricks-arkitekturen eliminerar detta genom sin design. En enda öppen plattform – byggd på Delta Lake och Medallion-arkitekturen – stöder BI-, streaming- och AI-arbetsbelastningar på samma underliggande data utan förflyttning eller replikering.
Data flödar en gång genom pipeline-lagren:
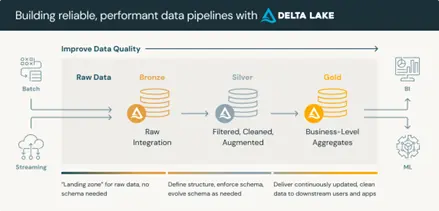
En inmatningspipeline. En transformationslogik. En version av måttet.
Elimineringen av dubbla pipelines minskar felytan och förenklar felsökning avsevärt. När en metrisk avvikelse uppstår i en verksamhetsgranskning finns det en pipeline att undersöka och en transformationslogik att granska – inte tre. Det är den minskningen av diagnostisk komplexitet som gör att ingenjörstimmar återvinns mest konsekvent i produktionsmiljöer i Lakehouse.
Organisationer som implementerar skiktade dataarkitekturer med tydliga kvalitetskontroller rapporterar en 3 gånger förbättring av tillförlitligheten i datapipelines jämfört med de som använder platta, ostrukturerade sjöarkitekturer.
Traditionella datasjöar saknar transaktionsgarantier. Samtidiga skrivningar producerar partiella uppdateringar. Misslyckade jobb lämnar tabeller i obestämda tillstånd. Schemaändringar sprids tyst och korrumperar analyser nedströms. I reglerade branscher är avsaknaden av en granskbar datahistorik en efterlevnadsrisk, inte bara en teknisk olägenhet.
Delta Lake löser transaktionsproblemet på lagringsformatnivå. Varje skrivning antingen slutförs helt eller sker inte alls – inga partiella tillstånd, ingen tyst korruption. Schematillämpning förhindrar att uppströmsändringar sprids till analytiska datamängder utan explicit validering på pipeline-lagret. Tidsresor gör det möjligt för ingenjörer att fråga eller återställa vilken tidigare version av en tabell som helst – det som tidigare tog timmar tar minuter.
Apache Iceberg utökar dessa garantier till miljöer med flera motorer genom en öppen specifikation, vilket säkerställer att samma transaktionella egenskaper gäller oavsett vilken beräkningsmotor som läser eller skriver tabellen.
Delta Lake löser transaktionsproblemet på lagringsformatnivå. Varje skrivning antingen slutförs helt eller sker inte alls – inga partiella tillstånd, ingen tyst korruption. Schematillämpning förhindrar att uppströmsändringar sprids till analytiska datamängder utan explicit validering på pipeline-lagret. Tidsresor gör det möjligt för ingenjörer att fråga eller återställa vilken tidigare version av en tabell som helst – det som tidigare tog timmar tar minuter.
Apache Iceberg utökar dessa garantier till miljöer med flera motorer genom en öppen specifikation, vilket säkerställer att samma transaktionella egenskaper gäller oavsett vilken beräkningsmotor som läser eller skriver tabellen.
År 2026 kommer 60 % av organisationer som inte hanterar sina data på lagringslagret att uppleva minst en väsentlig efterlevnadsincident relaterad till AI- eller analysresultat.
När en efterlevnadsrevision kräver dokumentation av dataproveniens, eller när ett AI-initiativ träffar en CISO-styrningsgranskning, ger tidsrese- och härkomstfunktionerna i Databricks data Lakehouse-arkitektur strukturerade, frågebara bevis som manuella dokumentationsprocesser inte kan. Förberedelsetiden för revisioner minskar från dagar till timmar – inte för att processen ändrades, utan för att bevisen samlades in automatiskt i varje steg.
I fragmenterade arkitekturer tillämpas styrning separat i varje miljö – lagerbehörigheter i ett system, sjökontroller i ett annat, ML-åtkomst hanteras oberoende. Härstamningsspårning inom miljöer, inte mellan dem. När ett AI-initiativ träffar en CISO-granskning som frågar vilka data modellen tränade på, vem som hade åtkomst och vilka kontroller som fanns på plats – kan en ostyrd arkitektur inte svara på det. Projekten stannar av.
72 % av företagsledarna uttrycker oro över tillförlitligheten hos AI-resultat. Styrningsgapet är inte en perifer oro – det är det centrala hindret mellan AI-experiment och AI i stor skala.
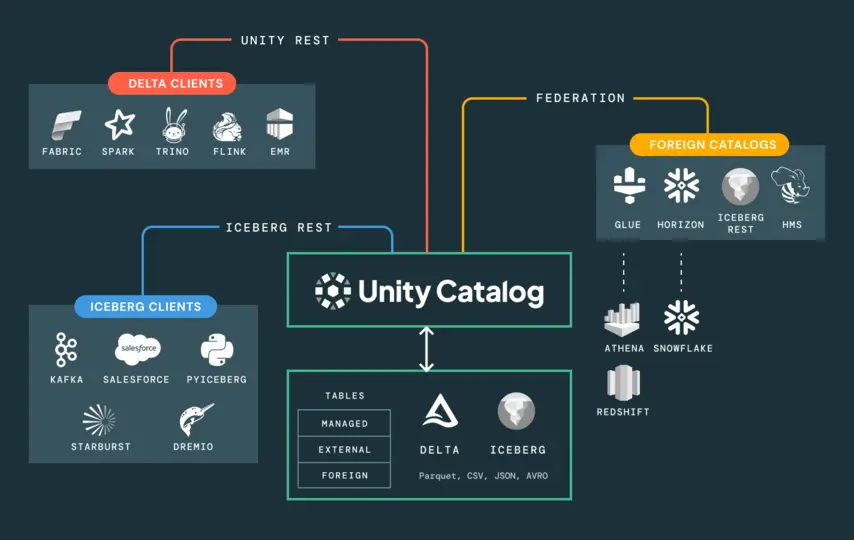
Unity Catalog tillhandahåller ett enda styrningslager över hela Lakehouse-plattformen – data, analyser, ML-modeller, anteckningsböcker och instrumentpaneler som hanteras under en metaarkiv med konsekventa åtkomstpolicyer. Kontroller på rad- och kolumnnivå tillämpas med standard ANSI SQL. End-to-end-avstamning spårar varje transformation från råkälla genom varje pipeline-lager till den slutliga modellen eller rapportutdata – i ett frågbart diagram.
Unity Catalog måste etableras innan pipelines byggs och innan modeller tränas. Att eftermontera styrning i ett fungerande system kostar betydligt mer – i form av ingenjörstid och intressenternas förtroende – än att utforma det korrekt från början.
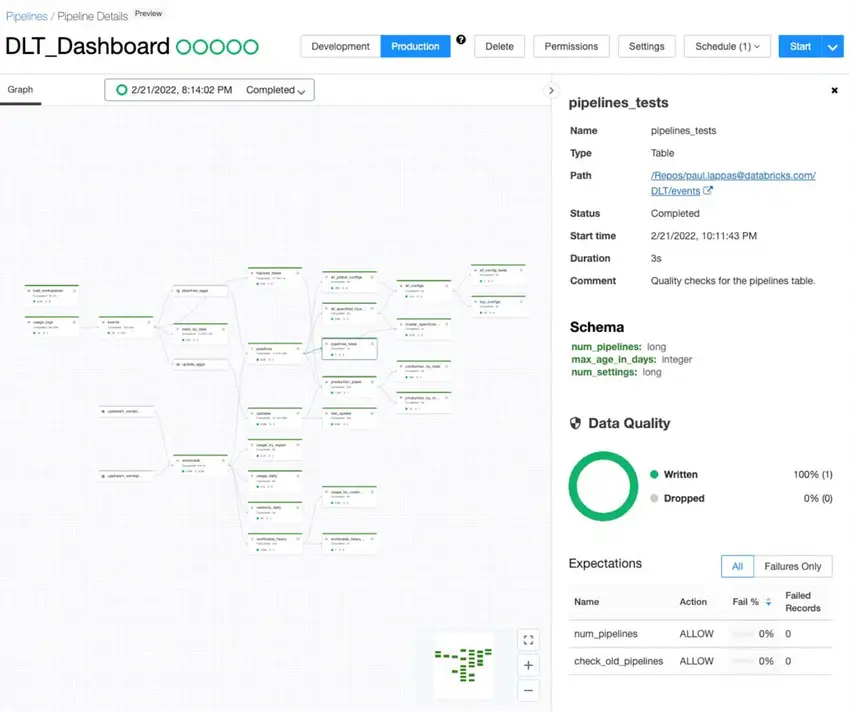
Handkodade strömmande pipelines kräver att ingenjörer explicit underhåller varje felläge – kontrollpunktshantering, tillståndsåterställning, schemautveckling, logik för återförsök. I stor skala blir detta en underhållsskyldighet som förbrukar den kapacitet som behövs för att bygga något nytt. Pipelinefel är inte edge-fall. De är de återkommande händelser som jourrotationer byggs kring.
Delta Live Tables (DLT) inverterar pipeline-utvecklingsmodellen från imperativ till deklarativ. Ingenjörer definierar hur data ska se ut och vilka kvalitetsstandarder den måste uppfylla. DLT hanterar beroendelösning, automatisk skalning, felhantering, logik för återförsök och tillämpning av datakvalitet automatiskt – genom konfigurerbara förväntningar som varnar, sätter i karantän eller stoppar vid kvalitetsöverträdelser.
Databricks Workflows utökar detta till flerstegsorkestrering: schemaläggning av komplexa pipelines som kombinerar anteckningsböcker, DLT-uppgifter och ML-modeller, med inbyggda reparations- och omkörningsfunktioner som återupptas från felpunkten istället för att starta om från grunden.
Manuell klusterhantering skapar ett ihållande kostnads- och omkostnaderproblem. Storlek för toppbelastning och du betalar för inaktiv beräkning vid lågtrafik. Storlek för genomsnitt och jobbkö vid toppar. Manuell finjustering – VACUUM, OPTIMIZE, partitionsjusteringar – är tidskrävande och inkonsekvent mellan olika arbetsbelastningstyper.
Serverlös beräkning på Databricks Lakehouse-plattformen abstraherar infrastrukturhanteringen helt. Beräkningen provisioneras direkt när en arbetsbelastning startar och släpps när den är klar – ingen klusterkonfiguration, ingen hantering av inaktiva resurser, inga kallstartsfördröjningar. Säkerhetsarkitekturen separerar kontrollplanet från dataplanet, vilket säkerställer att kunddata finns kvar i kundens eget molnkonto, krypterade i vila och under överföring – oavsett om de distribueras som ett AWS Data Lakehouse eller ett Azure Databricks Lakehouse.
Prediktiv optimering stänger den manuella justeringsslingan: AI-drivna algoritmer analyserar frågemönster kontinuerligt och kör bakgrundsunderhåll – VACUUM, OPTIMIZE – endast när prestandaanalyser indikerar en meningsfull förbättring. Manuell justering ersätts av automatiserat, ROI-motiverat underhåll.
Vet du?
Databricks Lakehouse-plattform med strukturerad beräkningsstyrning uppnådde en avkastning på investeringen på 247 % under tre år, med en återbetalningstid på under sju månader!
Lägre total ägandekostnad, snabbare arbetsbelastningskörning och konsekvent hög frågeprestanda utan manuell finjustering. Ingenjörskapacitet omdirigeras från infrastrukturhantering till pipelineutveckling – det arbete som ökar i värde över tid!
Sekvensen för implementeringsbesluten avgör om Databricks Lakehouse-arkitekturen levererar eller ackumulerar en ny kategori av teknisk skuld. Etablera Unity Catalog först. Tillämpa beräkningsstyrning innan arbetsbelastningar skalas. Använd Delta Live-tabeller innan manuell orkestrering blir den belastning som din jourrotation är byggd kring. Dessa beslut är svårare att eftermontera än att göra rätt från början – och kostnaden för att göra fel syns snabbt i molnräkningar, efterlevnadsgranskningar och ingenjörsmoral.
Det är just här som skillnaden görs när man har navigerat dessa beslut över flera produktionsmiljöer. Polestar Analytics har byggt Lakehouse-arkitekturer för logistik, tillverkning och finansiella tjänster – och implementerat styrningsramverk för Unity Catalog, DLT-pipelinearkitekturer och beräkningspolicyer som håller även under verklig produktionspress. Vi konsulterar inte på distans. Vi har fattat dessa beslut under deadline, i produktion, med verkliga insatser.
Om er organisation utvärderar Databricks Lakehouse-plattformen för första gången eller försöker få ut mer av en befintlig implementering som inte har levt upp till sitt arkitektoniska löfte – är rätt utgångspunkt en diskussion om var er arkitektur står för närvarande och vilken sekvensering som är vettig med tanke på er datatillgång, team och AI-färdplan.
Om författaren
Datastrateg
De flesta data besvarar frågor. Rätt data ändrar riktning.
Relaterad blogg
Kshitij Gupta
 Ali Kidwai
Ali Kidwai