
Sammanfatta detta blogginlägg med:
I dagens konkurrensutsatta affärsmiljö är det inte bara ett IT-projekt att införa ett Enterprise Data Warehouse – det är en strategisk nödvändighet. Med den dagliga ökande datagenereringen, som sannolikt kommer att nå över 394 zettabyte världen över år 2028, måste du se till att Enterprise Data Warehousing-systemet är förberett inte bara för att stödja lagring utan även den ökande efterfrågan på analyser.
Du vet redan vad det är. Ett Enterprise Data Warehouse (EDW) är som Marie Kondo i ditt datalandskap, som skapar mening i oorganiserat kaos genom att aggregera information från olika system till ett snyggt, analysstödjande centraliserat arkiv. Det är inte bara ytterligare en databas, det är en arkitektonisk lösning som underlättar Business Intelligence-funktioner och välgrundat beslutsfattande.
Tidiga företagsdatalager (EDW:er) var centraliserade. De använde relationssystem byggda på SQL-databaser med funktioner som SELECT, JOIN och GROUP BY för att bearbeta historiska rapporter och grundläggande business intelligence.
Moderna Enterprise Data Warehousing (EDW)-tjänster är distribuerade och molnbaserade plattformar. De använder tekniker som MPP-databaser (Massively Parallel Processing) , datasjöar och strömmande inmatning som hanterar olika datatyper – strukturerad, semistrukturerad och ostrukturerad data. De stöder även realtidsanalys, ACID-transaktioner, komplexa SQL-funktioner och integration med AI/ML-verktyg för att fatta operativa beslut med hjälp av ELT och datavisualisering.
Men låt oss vara ärliga, utan effektiv implementering slutar de flesta företagsdatalager som inget annat än glorifierade lagringssystem.
Vad skiljer högpresterande företag åt? Det är sällan tekniken i sig, utan hur de implementerar och utvecklar sina företagsplattformar för datalagring genom strategiska bästa praxis.
För att få ut mesta möjliga av ditt datalager, följ dessa fem bästa metoder med en logisk implementeringsplan:
Bästa praxis: Fastställ mätbara affärsresultat innan du ens funderar på teknikval.
De flesta implementeringar av företagsdatalager misslyckas eftersom de förblir IT-projekt som mäts utifrån drifttid och frågeprestanda snarare än affärsresultat. Istället bör strategin utgå från ett affärsresultat. Definiera till exempel specifika, mätbara resultat såsom:
Beslutshastighet: Genom att minska veckovisa lagerplaneringscykler från 5 dagar till 2 dagar (vilket kräver 2,5x effektivitetsvinster), kan den grova uppskattningen se ut så här (förutsatt 1 TB aktuell veckovis data) – en ökning av datorkraften med 20–40 %.
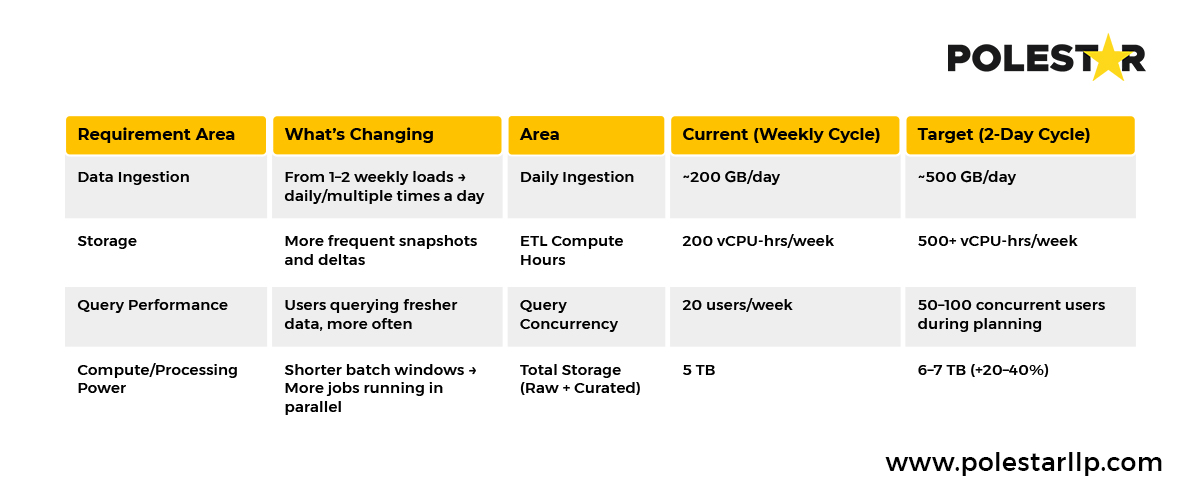 Presentation av hur affärsanpassning påverkar lagerstrategin
Presentation av hur affärsanpassning påverkar lagerstrategin Oavsett om ert fokus är kundlojalitet, operativ effektivitet eller regelefterlevnad, bör er optimering eller egenskaper för Enterprise Data Warehouse direkt möjliggöra dessa resultat genom tydliga mätvärden.
Bästa praxis: Implementera omfattande datakvalitetspraxis i själva staging-lagret
De flesta datalager har nu en mellanlagringsmiljö som fungerar som din kritiska kontrollpunkt, mellan källsystem och produktionsmiljöer för datakvalitet. Men det här handlar inte bara om datavalidering, det handlar om att bygga systematisk kvalitetssäkring som skalar med din datavolym och komplexitet. Några av de bästa metoderna att behålla i detta lager inkluderar:
| Område | Bästa praxis |
|---|
| Datafidelity | Behåll rått material; inga omvandlingar |
|---|
| Belastning | Endast tillägg; tidsstämplad |
|---|
| Partitionering | Efter datum/källa |
|---|
| Metadata | Lagra tidsstämplar för laddning, filnamn och batch-ID:n |
|---|
| Kvalitetskontroller | Endast lättviktsvalideringar |
|---|
| Säkerhet | Kryptera + begränsa åtkomst |
|---|
| Retention | Ange utgångspolicyer (t.ex. 30–90 dagar) |
|---|
| Spårbarhet | Aktivera spårning av härstamning och batcher |
|---|
| Lagringsformat | Föredra kolumnformat som Parquet/Delta |
|---|
PS Dessa metoder skulle vara mer specifika när du går in i typer som GCP , AWS eller Databricks. Exempel: Tillämpa vakuumpolicyer (VACUUM Delta-tabeller efter 7–30 dagar) för att frigöra lagring, eller aktivera datalivscykelhantering (DLM) om du använder Unity Catalog med molnlagring för Databricks-implementering .
Övning: Hybridintegrationsmetoder som matchar kraven på affärshastighet
Det strategiska värdet i Enterprise Data Warehouse uppstår genom att integrera olika informationskällor till sammanhängande affärsperspektiv. Moderna implementeringar av Enterprise Data Warehouse måste stödja traditionell batchbehandling för historisk analys samtidigt som de möjliggör realtidsdataflöden för operativt beslutsfattande. Några av de vanligaste bästa praxis som organisationer använder sig av idag är:
- Integrering genom att distribuera ändringsdatainsamling (CDC) för kontinuerlig synkronisering och konfigurera orkestrering för blandad bearbetning
- Rätt integrationsmetod – ETL för arbetsflöden med hög efterlevnad, ELT för skalbarhet eller realtidsströmning för liveanalys – beror på företagets behov.
- Implementera intelligent pipeline-orkestrering
- Implementera avancerad beroendehantering
- Implementera automatisk skalning av pipeline-körning
- Konfigurera intelligent felhantering och övervakning
- Eller till och med använda datainmatning i realtid med hjälp av verktyg som Apache Kafka eller AWS Kinesis för strömmande datakällor.
Men för att verkligen ha den bästa dataintegrationen i AI-eran – behöver du automatisera repetitiva uppgifter som datautvinning, transformation, inläsning och modellskapande för att förbättra effektiviteten och minska fel. Och vi har en av de bästa lösningarna för det, Data Nexus !
Bästa praxis: Designa OLAP-motorn inom en 3-nivås Enterprise Data Warehouse-arkitektur i linje med analytiska konsumtionsmönster
Er Enterprise Data Warehouse-arkitektur avgör organisationens flexibilitet. Så de mest effektiva implementeringarna av Enterprise Data Warehouse använder trenivåarkitekturstrategier som balanserar prestandakrav med företagets tillgänglighetsbehov.
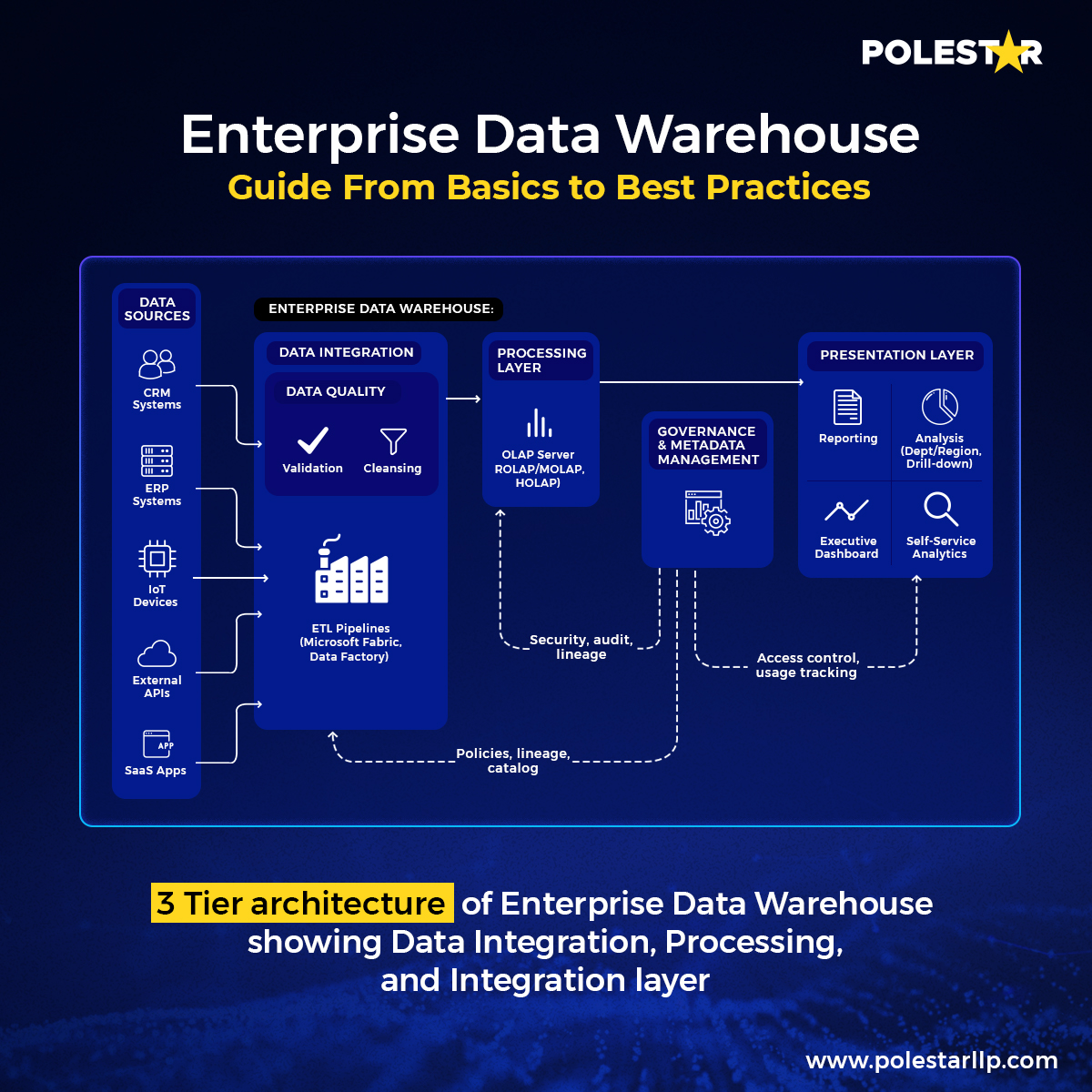 3-nivåarkitektur för Enterprise Data Warehouse
3-nivåarkitektur för Enterprise Data Warehouse Processing Layer bör konfigureras för OLAP-motorer baserat på specifika analyskrav och affärskrav:
- ROLAP (Relational OLAP): Det är avsett för detaljerad, undersökande analys där dataaktualitet och detaljerade funktioner är avgörande. Till exempel skulle finansiella tjänster använda ROLAP för efterlevnadsutredningar som kräver 10–30 sekunders svarstider på detaljerad transaktionsdata.
- MOLAP (Multidimensionell OLAP): Optimal för chefsdashboards som kräver svarstider på under en sekund för fördefinierade mätvärden. Precis som detaljhandelsföretag använder MOLAP för dagliga försäljningsdashboards, där de lagrar föraggregerad datavolym samtidigt som de ger omedelbara insikter.
- HOLAP (Hybrid OLAP): Kombinerar båda metoderna för organisationer som behöver snabba ledningsuppdrag och analytiskt djup. Till exempel skulle ett tillverkningsföretag implementera en HOLAP-arkitektur där produktionschefer får tillgång till utrustningsstatus i realtid via ROLAP-frågor, medan chefer ser föraggregerade dagliga produktionssammanfattningar via MOLAP-kuber.
Moderna plattformar som Microsoft Fabric exemplifierar denna flexibla arkitektur med OneLake som datalager, Synapse Data Warehouse för OLAP-lagrets (med stöd för HOLAP) funktioner och Power BI för presentation – vilket gör det möjligt för organisationer att utnyttja både styrning av datalager och flexibilitet i datasjöar inom en enhetlig plattform.
Praktik: Förutom att säkerställa dataavstamning – bör metadata nu kunna underlätta för LLM:er och agenter
I AI:s era är metadata inte längre bara en katalog; det är bränslet för automatisering, avstamning, styrning och intelligent upptäckt. Effektiv metadatahantering har utvecklats bortom teknisk dokumentation. Moderna metadatametoder fokuserar på affärskontext vid sidan av tekniska specifikationer, särskilt när organisationer förbereder sig för AI och agentiska arbetsflöden.
Så det finns några saker att spåra när det gäller standardisering, versionshantering, affärskontext och övervakning, som:

Ytterligare bästa praxis för metadata för agenter och generativ AI
- Metadatakataloger bör vara LLM-läsbara via API:er eller inbäddningslager.
- Gör det enklare att förse Retrieval-Augmented Generation (RAG)-system och datapiloter med kontextuell metadata.
- Automatisera taggning och klassificering av datamängder (t.ex. ekonomi, kund, PII).
Nya teknologier, ökande datavolymer och förändrade affärsbehov måste alla tillgodoses av ett effektivt företagsdatalager eller till och med ett modernt Lakehouse-system. Och för det är nästa steg i att förändra din datastrategi Polestar Analytics AI-drivna datalagerlösningar!
F: Hur kan generativ AI förbättra driften av företagsdatalager?
A: Generativ AI skulle omvandla Enterprise Data Warehouse-verksamheten inom följande områden:
Automatiserad dataförberedelse: AI genererar ETL-kod, vilket minskar utvecklingstiden samtidigt som datakvalitetsstandarder säkerställs. Till exempel kan AI automatiskt skapa transformationsregler när nya datakällor läggs till.
Frågegenerering: Företagsanvändare kan beskriva analytiska behov på naturligt språk, och AI genererar optimerade SQL-frågor, vilket gör det tillgängligt för alla. Automatiserade insikter: AI övervakar datamönster och genererar affärsinsikter. Den varnar respektive intressenter om avvikelser utan manuell analys.
F: Vad är Lakehouse-arkitektur? Hur skiljer den sig från traditionella Enterprise Data Warehouse-arkitekturer?
A: Data Lakehouse är en hybridplattform för datalagring och bearbetning som kombinerar det bästa från både traditionella datasjö- och datalagertekniker: billig lagring i ett öppet format som är tillgängligt via en mängd olika system från den förra, och kraftfulla hanterings- och optimeringsfunktioner från den senare.
| Särdrag | Traditionell EDW | Lakehouse-arkitektur |
|---|
| Datatyper | Primärt strukturerad | Alla (Strukturerad, Semistrukturerad, Ostrukturerad) |
|---|
| Schema | Schema-on-Write (rigid) | Schema-vid-läsning/skrivning (flexibelt) |
|---|
| Rörlighet | Mindre agil, svår för nya arbetsbelastningar | Mycket agil, stöder olika analyser (BI, ML) |
|---|
| Kosta | Ofta högre (proprietär) | Generellt lägre (öppna format, molnbaserade) |
|---|
| Styrning/ACID | Starka ACID-transaktioner och styrning (inbyggt) | Lägger till ACID och styrning till datasjön (t.ex. Delta Lake) |
|---|
F: Vilka är huvudelementen i ett företagsdatalager?
A: Ett omfattande Enterprise Data Warehouse-system integrerar fyra nyckelelement:
Central databas: Den arkitektoniska grunden som implementerar kolumnär lagring optimerad för analytiska frågor. Dataintegrationsverktyg: Sofistikerade ETL/ELT-pipelines som extraherar, transformerar och laddar information, med moderna plattformar som stöder realtidsströmning och AI-driven dataförberedelse.
Metadataförråd: Omfattande dokumentation inklusive tekniska specifikationer, affärskontext och operativa metadata – alltmer förbättrad med AI för automatiserad klassificering och identifiering.
Dataåtkomstverktyg: Frågegränssnitt, OLAP-system, visualiseringsplattformar och AI/ML-funktioner som gör information tillgänglig för olika användarpersoner och analytiska användningsfall.