 Kshitij GuptaData-strateeg
Kshitij GuptaData-strateeg
Meld u aan om de nieuwste inzichten en updates over technologie, AI & data-analyse, datawetenschap en innovaties van Polestar Analytics te ontvangen.
De meeste data-engineeringteams binnen bedrijven falen niet door een gebrek aan tools. Ze falen omdat de tools die de afgelopen tien jaar zijn verzameld, nooit ontworpen waren om samen te werken.
Een datawarehouse voor rapportage. Een datameer voor schaalvergroting. Een aparte machine learning-omgeving. Een streaminglaag die werd toegevoegd toen batchverwerking de vraag niet meer aankon. Elk van deze beslissingen was op dat moment logisch. De architectuur die ze samen hebben gecreëerd, is dat niet.
Weet je dat?
- Slechte datakwaliteit kost organisaties gemiddeld 12,9 miljoen dollar per jaar.
- Bedrijven die gebruikmaken van aparte data lake- en data warehouse-omgevingen besteden tot wel 30% van hun totale budget voor data-infrastructuur aan redundante dataverplaatsing en -opslag – nog voordat ze ook maar één waardevol inzicht genereren.
Databricks Lakehouse vervangt de gefragmenteerde architectuur door één open platform. Deze blog bespreekt de specifieke data-engineeringuitdagingen die de Databricks Lakehouse-architectuur oplost, en de mechanismen waarmee dit gebeurt.
~ Bablu Chakraborty, Senior Vice President – Capability, Polestar Analytics
Voordat we de individuele uitdagingen bekijken, is het belangrijk om precies te definiëren wat het Databricks Lakehouse-platform is, omdat die definitie bepalend is voor elke implementatiebeslissing die daarop volgt.
Het Databricks Data Lakehouse is geen datawarehouse met toegevoegde lake-functionaliteiten, of een lake met daarop gemonteerde warehouse-governance. Het is een enkel open platform dat de transactionele betrouwbaarheid, schema-handhaving en queryprestaties van een datawarehouse biedt, terwijl de schaalbaarheid, openheid en ML-compatibiliteit van een data lake behouden blijven. De Lakehouse-architectuur op Databricks draait op open tabelformaten – Delta Lake en Apache Iceberg – wat betekent dat er geen vendor lock-in is op de opslaglaag en dat elke rekenengine die open standaarden ondersteunt, dezelfde tabellen kan lezen en ernaar kan schrijven.
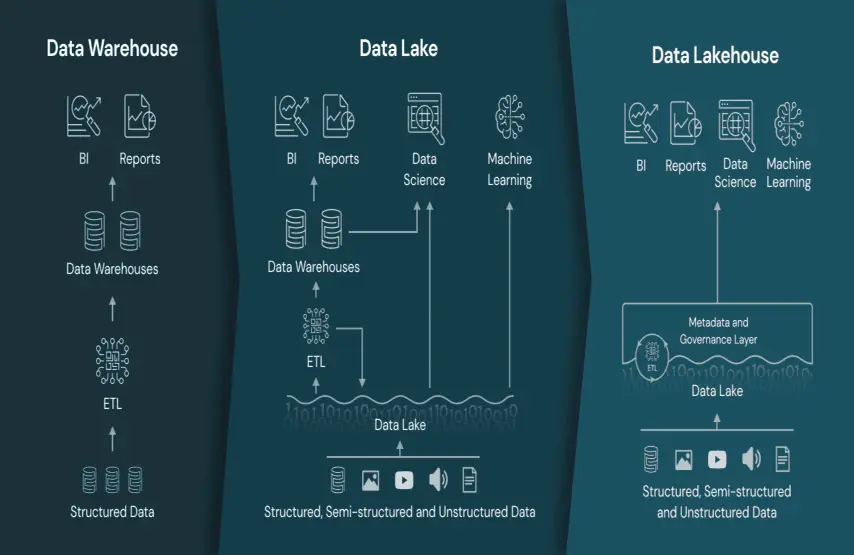
Wanneer een datawarehouse en een data lake als aparte systemen naast elkaar bestaan, worden dezelfde gegevens twee keer ingevoerd, twee keer getransformeerd en twee keer op kwaliteit gecontroleerd – door verschillende teams, wat resulteert in verschillende cijfers. Elke nieuwe gegevensbron verhoogt deze overhead. Het is een structureel probleem, geen probleem met de datakwaliteit.
De Lakehouse Databricks-architectuur elimineert dit probleem van nature. Een enkel open platform – gebouwd op Delta Lake en de medallion-architectuur – ondersteunt BI-, streaming- en AI-workloads op dezelfde onderliggende data, zonder dat er data verplaatst of gedupliceerd hoeft te worden.
De gegevens doorlopen de pipelinelagen eenmaal:
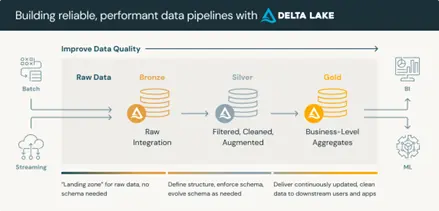
Eén data-invoerpipeline. Eén transformatielogica. Eén versie van de meetwaarde.
Het elimineren van dubbele pipelines verkleint het faalrisico en vereenvoudigt het debuggen aanzienlijk. Wanneer er tijdens een business review een afwijking in de meetwaarden aan het licht komt, hoeft er slechts één pipeline onderzocht te worden en één transformatielogica gecontroleerd te worden – in plaats van drie. Deze vermindering van de diagnostische complexiteit is waar in productieomgevingen van Lakehouse het meest consistent tijd wordt bespaard aan engineeringuren.
Organisaties die gelaagde data-architecturen met duidelijke kwaliteitsborgingszones implementeren, melden een drievoudige verbetering van de betrouwbaarheid van de datapijplijn in vergelijking met organisaties die gebruikmaken van platte, ongestructureerde data lake-architecturen.
Traditionele data lakes missen transactionele garanties. Gelijktijdige schrijfbewerkingen leiden tot gedeeltelijke updates. Mislukte taken laten tabellen in een onduidelijke staat achter. Schemawijzigingen worden ongemerkt doorgevoerd, waardoor latere analyses worden verstoord. In gereguleerde sectoren vormt het ontbreken van een controleerbare datahistorie een risico voor de naleving van wet- en regelgeving, en niet slechts een technisch ongemak.
Delta Lake lost het transactieprobleem op het niveau van het opslagformaat op. Elke schrijfbewerking wordt volledig voltooid of vindt helemaal niet plaats — geen gedeeltelijke resultaten, geen stille corruptie. Schemahandhaving voorkomt dat wijzigingen stroomopwaarts zich verspreiden naar analytische datasets zonder expliciete validatie op pipelineniveau. Time-travel stelt engineers in staat om elke eerdere versie van een tabel op te vragen of te herstellen — wat voorheen uren duurde, duurt nu nog maar minuten.
Apache Iceberg breidt deze garanties uit naar omgevingen met meerdere engines via een open specificatie, waardoor dezelfde transactionele eigenschappen gelden ongeacht welke rekenengine de tabel leest of schrijft.
Delta Lake lost het transactieprobleem op het niveau van het opslagformaat op. Elke schrijfbewerking wordt volledig voltooid of vindt helemaal niet plaats — geen gedeeltelijke resultaten, geen stille corruptie. Schemahandhaving voorkomt dat wijzigingen stroomopwaarts zich verspreiden naar analytische datasets zonder expliciete validatie op pipelineniveau. Time-travel stelt engineers in staat om elke eerdere versie van een tabel op te vragen of te herstellen — wat voorheen uren duurde, duurt nu nog maar minuten.
Apache Iceberg breidt deze garanties uit naar omgevingen met meerdere engines via een open specificatie, waardoor dezelfde transactionele eigenschappen gelden ongeacht welke rekenengine de tabel leest of schrijft.
Tegen 2026 zal 60% van de organisaties die hun data op opslagniveau niet goed beheren, ten minste één ernstig compliance-incident ondervinden dat verband houdt met AI- of analyse-uitkomsten.
Wanneer een compliance-audit documentatie over de herkomst van gegevens vereist, of wanneer een AI-initiatief een governance-review door de CISO ondergaat, bieden de mogelijkheden voor tijdreizen en dataherkomst van de Databricks Data Lakehouse-architectuur gestructureerd, doorzoekbaar bewijsmateriaal dat met handmatige documentatieprocessen niet mogelijk is. De voorbereidingstijd voor een audit daalt van dagen naar uren – niet omdat het proces is veranderd, maar omdat het bewijsmateriaal bij elke stap automatisch is vastgelegd.
In gefragmenteerde architecturen wordt governance in elke omgeving afzonderlijk toegepast: toegangsrechten voor datawarehouses in het ene systeem, beheer van datalakes in een ander, en toegang tot machine learning wordt onafhankelijk beheerd. De herkomst van gegevens wordt binnen de omgevingen bijgehouden, niet tussen omgevingen. Wanneer een AI-initiatief een CISO-evaluatie ondergaat met vragen over welke data het model heeft getraind, wie toegang had en welke beheersmaatregelen er waren, kan een architectuur zonder governance hier geen antwoord op geven. Projecten komen dan stil te liggen.
72% van de bedrijfsleiders maakt zich zorgen over de betrouwbaarheid van AI-resultaten. De governancekloof is geen bijkomstig probleem, maar vormt het grootste obstakel tussen AI-experimenten en AI op grote schaal.
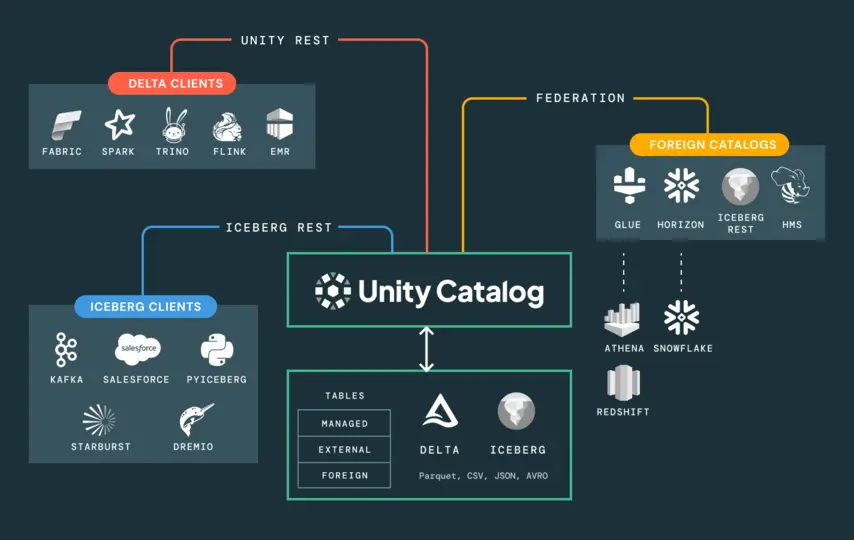
Unity Catalog biedt één beheerslaag voor het gehele Lakehouse-platform: data, analyses, ML-modellen, notebooks en dashboards worden beheerd in één metastore met consistente toegangsregels. Toegangsrechten op rij- en kolomniveau worden toegepast met behulp van standaard ANSI SQL. De volledige datalijn volgt elke transformatie, van de ruwe bron via elke pipelinelaag tot de uiteindelijke model- of rapportoutput, in een doorzoekbare grafiek.
Unity Catalog moet worden geconfigureerd voordat pipelines worden gebouwd en voordat modellen worden getraind. Het achteraf toevoegen van governance aan een werkend systeem kost aanzienlijk meer – in termen van ontwikkeltijd en vertrouwen van stakeholders – dan het vanaf het begin correct te ontwerpen.
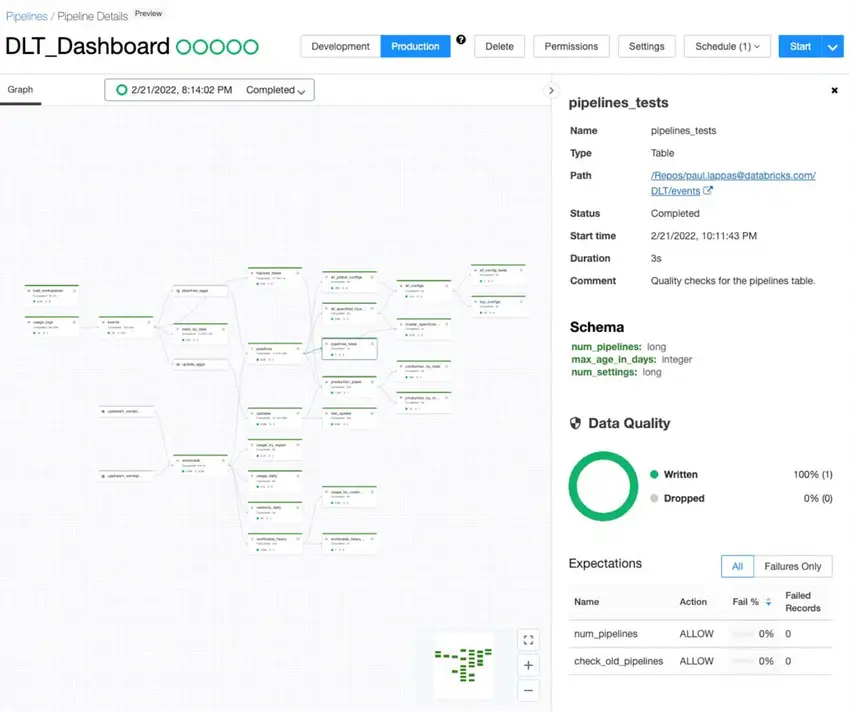
Handmatig gecodeerde streamingpipelines vereisen dat engineers elke mogelijke foutmodus expliciet onderhouden – checkpointbeheer, statusherstel, schema-evolutie, herhalingslogica. Op grote schaal wordt dit een onderhoudslast die ten koste gaat van de capaciteit die nodig is voor de ontwikkeling van nieuwe systemen. Fouten in pipelines zijn geen uitzonderingen. Het zijn terugkerende gebeurtenissen waar de storingsdiensten op gebaseerd zijn.
Delta Live Tables (DLT) keert het ontwikkelingsmodel van de pipeline om van imperatief naar declaratief. Engineers definiëren hoe de data eruit moet zien en aan welke kwaliteitsnormen deze moet voldoen. DLT beheert automatisch de afhankelijkheidsresolutie, automatische schaling, foutafhandeling, herhalingslogica en het afdwingen van datakwaliteit – via configureerbare verwachtingen die waarschuwen, in quarantaine plaatsen of stoppen bij kwaliteitsschendingen.
Databricks Workflows breidt dit uit naar orkestratie in meerdere stappen: het plannen van complexe pipelines die notebooks, DLT-taken en ML-modellen combineren, met ingebouwde herstel- en herstartmogelijkheden die verdergaan vanaf het punt van falen in plaats van helemaal opnieuw te beginnen.
Handmatig clusterbeheer zorgt voor aanhoudende kosten en overhead. Kiest u voor de piekbelasting, dan betaalt u voor inactieve rekenkracht buiten de piekuren. Kiest u voor de gemiddelde belasting, dan ontstaan er wachtrijen voor taken tijdens piekuren. Handmatige afstemming — VACUUM, OPTIMIZE, partitieaanpassingen — is tijdrovend en inconsistent voor verschillende soorten workloads.
Serverless computing op het Databricks Lakehouse-platform abstraheert het infrastructuurbeheer volledig. Compute wordt direct geprovisioneerd wanneer een workload start en vrijgegeven wanneer deze is voltooid — geen clusterconfiguratie, geen beheer van inactieve resources, geen vertragingen bij een koude start. De beveiligingsarchitectuur scheidt het besturingsvlak van het datavlak, waardoor klantgegevens in het eigen cloudaccount van de klant blijven, versleuteld in rust en tijdens transport — ongeacht of het is geïmplementeerd als een AWS Data Lakehouse of een Azure Databricks Lakehouse.
Predictive Optimization sluit de cyclus van handmatige afstemming: AI-gestuurde algoritmen analyseren continu querypatronen en voeren achtergrondonderhoud uit — VACUUM, OPTIMIZE — alleen wanneer de prestatieanalyse een significante verbetering aangeeft. Handmatige afstemming wordt vervangen door geautomatiseerd, op ROI gebaseerd onderhoud.
Weet je dat?
Het Databricks Lakehouse-platform met gestructureerd computerbeheer behaalde een ROI van 247% over drie jaar, met een terugverdientijd van minder dan zeven maanden!
Lagere totale eigendomskosten, snellere uitvoering van workloads en consistent hoge queryprestaties zonder handmatige afstemming. De engineeringcapaciteit wordt omgeleid van infrastructuurbeheer naar pipeline-ontwikkeling – werk dat in de loop der tijd in waarde toeneemt!
De volgorde waarin implementatiebeslissingen worden genomen, bepaalt of de Databricks Lakehouse-architectuur een nieuwe categorie technische schuld oplevert of juist creëert. Implementeer eerst Unity Catalog. Voer compute governance in voordat workloads schalen. Neem Delta Live Tables in gebruik voordat handmatige orchestratie de last wordt waar uw on-call-dienst op is gebaseerd. Deze beslissingen zijn lastiger achteraf aan te passen dan om ze vanaf het begin goed te nemen – en de kosten van fouten worden snel merkbaar in cloudfacturen, compliance-audits en het moreel van de engineers.
Precies hier maakt onze ervaring met het nemen van deze beslissingen in diverse productieomgevingen het verschil. Polestar Analytics heeft Lakehouse-architecturen gebouwd voor logistiek, productie en financiële dienstverlening – met implementatie van Unity Catalog-governanceframeworks, DLT-pipeline-architecturen en computerbeleid dat bestand is tegen de druk van een echte productieomgeving. Wij adviseren niet van een afstand. We hebben deze beslissingen onder tijdsdruk genomen, in een productieomgeving, met reële gevolgen.
Als uw organisatie het Databricks Lakehouse-platform voor het eerst evalueert of probeert meer te halen uit een bestaande implementatie die niet aan de architectonische verwachtingen heeft voldaan, is een goed startpunt een gesprek over de huidige status van uw architectuur en de meest logische volgorde van implementaties, rekening houdend met uw dataomgeving, team en AI-roadmap.
Over de auteur
Data-strateeg
De meeste data geeft antwoord op vragen. De juiste data verandert de richting.
Gerelateerde blog
Kshitij Gupta
 Ali Kidwai
Ali Kidwai