
Summarize this blog post with:
Editor’s Note- You have the data. The question in 2026 is whether the infrastructure underneath it was built to act on it — or just report on it. The tech has matured. The architectures have converged. Now it's about making it work at scale.
The data analytics trends shaping 2026 aren't about new tools or bigger models — they're about what data teams are now responsible for, and what it costs when they get it wrong. Written for data engineers, analytics architects, and CDOs making infrastructure decisions right now.
Nearly every large enterprise today claims to be data driven. Only 37.8% of Fortune 1000 companies actually are — despite an average spend of $250 million annually on data initiatives. That gap has existed for years. What's different in 2026 is the cost of it.
When analytics infrastructure only needed to support reporting, a broken pipeline meant a broken dashboard. Recoverable. Visible. Contained. But as AI moves from pilot to production, that same infrastructure now triggers decisions automatically — and bad data no longer just produces a bad report. It produces a bad action, at machine speed, and at scale.
More than half have wasted significant resources training models on data they shouldn't have trusted.
The organisations widening the gap aren't the ones with the best models or the biggest teams. They are the ones that treated data architecture as the strategic decision — not a prerequisite to the strategic decision.
The global analytics market is projected to grow from $104 billion in 2026 to $496 billion 2034. What determines who captures that value is already being decided by the infrastructure choices being made right now. Here are the six shifts that separate the organisations getting it right.
For decades, analytics ran on a pull model. Someone formed a question, opened a tool, the system returned an answer. The insight was only as good as the question asked — which meant entire categories of signal went unnoticed simply because nobody thought to look.
Agentic analytics breaks that contract. Rather than waiting to be queried, these systems watch continuously — catching anomalies before they become problems, explaining the numbers in plain language, and where thresholds allow, acting on them directly. Humans stay in the loop, but at the decision level, not the retrieval level.
Here’s how AI Agents works -
What's driving this isn't one thing. Large language models (LLMs) gave agents the ability to reason over unstructured context. Smaller specialised models (SLMs) made that reasoning affordable at scale. Together they produce something traditional rules-based automation never could — judgment that adapts. Platforms like 1Platform are already embedding this natively into BI tools through their consumption layer, meaning agentic analytics is no longer a separate system. It's a behaviour inside the platforms teams already use.

Gartner projects 40% of enterprise applications will embed task-specific AI agents by end of 2026, up from less than 5% in 2025.
For analysts, the practical shift is this: less time retrieving data, more time interpreting it. The role doesn't shrink — it moves upstream.
Traditional analytics pipelines have a direction problem. Data flows one way — ingest, transform, model, serve. An insight lands in a dashboard, a human acts on it, and what happens next simply disappears. The outcome never returns to the model. The next prediction runs on the same historical data, blind to what the last decision actually produced.
Closed-loop decision intelligence fixes the direction. Every decision becomes a data event in its own right — captured, labelled, and fed back as a training signal. The model learns from what it did, not just what the data said before it acted. Accuracy compounds. The pipeline stops being a one-way street.
TL;DR
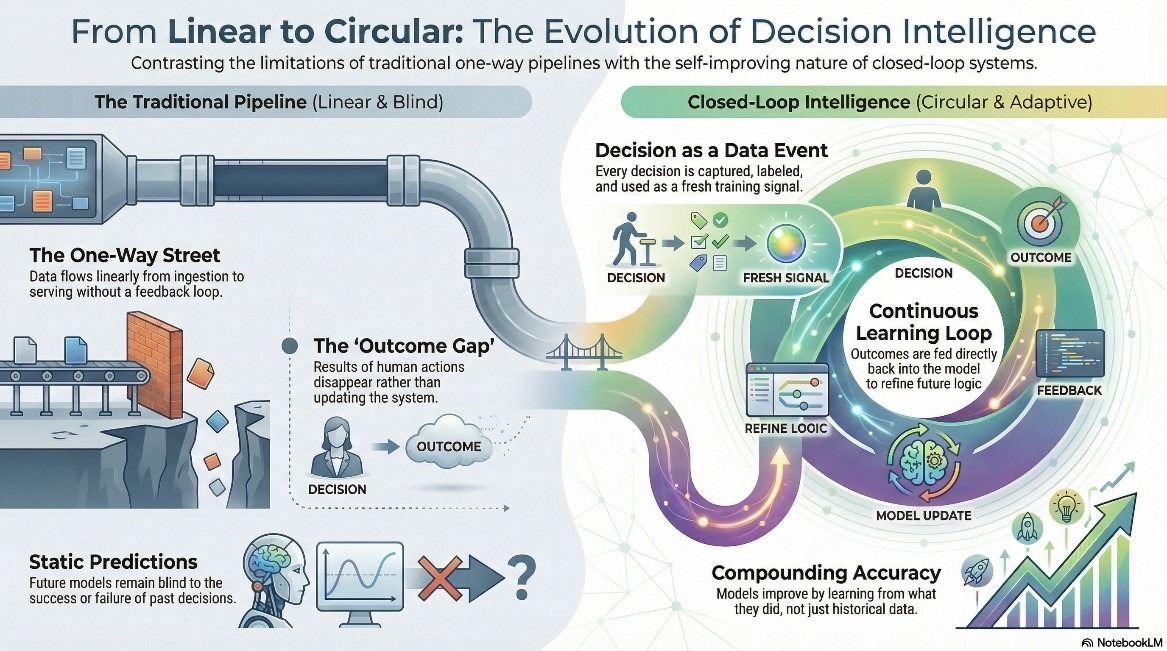
For data teams, this creates a new category of infrastructure responsibility. Outcome data is now a first-class entity — it needs to be modelled, governed, and monitored like any production source. That sounds straightforward until the feedback loop starts failing quietly. Outcome data arrives late. It arrives mislabelled. Sometimes it doesn't arrive at all. Each of these produces model drift that is significantly harder to detect than a broken ingestion job — and 89% of data leaders with AI in production have already experienced misleading outputs as a result of exactly these kinds of upstream failures.
This is where 1Platform's architecture makes the closed loop operational rather than theoretical. Data Nexus governs the full data estate including outcome signals, while Agenthood AI executes decisions within defined thresholds and writes every action and result back into the pipeline. Drift becomes detectable. Decisions become auditable. The feedback loop gets treated as infrastructure — because that's what it is.
Data ownership is moving out of central engineering and into the business — and the architecture is finally catching up. The lakehouse unified storage and compute. What it couldn't unify was ownership. As organisations scale, the real bottleneck isn't architecture — it's the governance vacuum that opens up when dozens of domain teams produce data with no clear accountability.
The data mesh picks up where the lakehouse leaves off. Rather than centralising everything into one platform owned by one team, the mesh distributes ownership to domain teams under federated governance — the lakehouse as technical substrate, Delta Lake, Apache Iceberg and Apache Hudi enabling cross-vendor interoperability, the mesh as the operating model on top. Data contracts between producers and consumers are emerging as the practical enforcement mechanism, turning SLAs from aspirational targets into operational commitments.
The data mesh market reflects how seriously enterprises are taking this: $1.5 billion in 2024, on course for $3.5 billion by 2030. When domain teams own their data with accountability attached, AI models train on cleaner inputs, cross-functional queries stop waiting in an engineering queue, and the business gets answers that reflect what's actually happening.
But only 18% of organisations have the governance maturity to execute this well, and 62% still name governance as their single biggest barrier to AI adoption. The gap is rarely the architecture — it's whether observability is built in from day one and whether SLA ownership genuinely transfers to domain teams. Federated ownership without a convergence layer just trades one bottleneck for another. 1Platform sits above the mesh to close that gap — unifying data management, decision intelligence, and agentic execution into one governed layer so distributed ownership doesn't fragment the analytics experience.
Harmonizing Data Mesh & DDH for a Global Alcobev Leader
SLMs don't generalise — that's the point. Fine-tuning on proprietary workflows like finance reconciliation, clinical documentation, or supply chain exception handling requires labelled, domain-specific training data at volume. Real-world data rarely delivers it. Edge cases are structurally underrepresented, regulation constrains what's usable for training, and annotation at scale is expensive and slow.
Synthetic data is the engineering answer. With it in place now you can :
- Generate the edge cases that never appear in production logs.
- Create regulation-compliant training sets without touching PII.
- Label at scale without human annotators.
Grand View Research puts the AI training dataset market at $3.2B in 2025, reaching $16.3B by 2033 — synthetic the fastest-growing segment at 30.5% CAGR. Gartner projects synthetic surpasses real data as primary AI training source by 2030.
For data teams, this is a new surface of ownership. Synthetic data pipelines require distributional validation — generated data that doesn't reflect real-world variance produces models that pass evaluation and fail silently in production. Schema coverage, class balance, and drift between synthetic and real distributions all need to be instrumented and monitored. The quality bar is identical to any production data source. The difference is the data team is now the originator, not just the custodian.
The organisations getting this right treat synthetic data generation as a first-class engineering practice — versioned, tested, governed — not a preprocessing step someone runs before model training.
Freshness, schema, volume, distribution, lineage — built for BI dashboards. In agentic pipelines, where data drives autonomous decisions, observability must exceed traditional standards.
The gap is upstream. Salesforce puts 89% of data leaders with AI in production having experienced misleading outputs. Most failures don't originate in the model — they originate in the data feeding it. Feature drift between training and serving. Schema changes that pass validation but break downstream logic. Outcome data returning late and corrupting the feedback loop.
The 2026 stack adds what classic observability misses: feature distribution monitoring between training and serving environments, data contract enforcement at producer-consumer boundaries, and outcome data observability to close the feedback loop. Teams instrumenting only the model layer are treating the symptom. The disease is upstream.
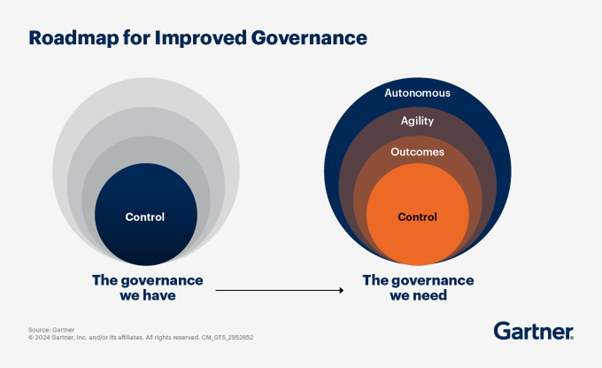
A model can have accuracy and still be ungovernable. No lineage to the training data. No documentation of how features were engineered. No way to explain to a regulator, an auditor, or a business stakeholder why the system produced a specific output. In 2026, that's not a compliance gap — it's a deployment blocker.
The shift happening across data teams is governance moving upstream into the build process. Data contracts defined before pipelines go live, not negotiated after something breaks. Quality SLAs owned by the domain team producing the data, not a central function reviewing it after the fact. Training data versioned and documented the same way production code is — because when a model misbehaves, the first question is always what data trained it.
 Gartner
Gartner
The EU AI Act enforcing from August 2026 formalises what leading data teams are already treating as standard: lineage from raw source to model output is a first-class engineering deliverable. The organisations ahead of this aren't doing more governance work — they've just moved it earlier, into architecture and pipeline design where it costs a fraction of what retrofitting it costs later.
Most data teams in 2026 are one architecture decision away from either compounding their AI investments or undermining them. The difference isn't budget or talent. It's whether the data estate — the pipelines, the contracts, the feedback loops, the governance — was designed for autonomous decision-making or just reporting.
Gartner's predictions make the direction clear. By 2028, the fragmented data management market converges into a single ecosystem around data fabric and GenAI. By 2027, AI embedded in data engineering tools reduces manual intervention by 60%. By 2026, natural language becomes the dominant interface for data consumption. The infrastructure isn't being built around AI anymore. It's being rebuilt by it.
The organisations ahead aren't doing more. They built the right foundation earlier. 1Platform by Polestar Analytics converges data management, decision intelligence, and agentic execution into one governed layer — so the distance between what the data says and what the business does with it stops being an architecture problem.