
Sammanfatta detta blogginlägg med:
Redaktörens anmärkning: Att hantera datapipelines (eller kvalitet) kan vara ett huvudvärk. I den här bloggen kommer vi att prata om dataobservabilitet. Föreställ dig röntgenvision för dina datapipelines, upptäck avvikelser, säkerställ kvalitet och förebygg katastrofer innan de inträffar. Lär dig de 5 pelarna inom dataobservabilitet och få det förtroende du vill ha från dina data. Lär dig hur AI kan ge dina insikter kraft och hjälpa dig att övervaka dina data i realtid. Ta kontroll över din datahälsa idag!
Om du har ställt dig själv följande frågor hela tiden kanske du vill ta en titt på dina datahanteringsrutiner och den här bloggen hjälper dig att lära dig mer om hur du kan lösa ditt problem.
→ Är informationen aktuell?
→ Är inte detta värde misstänkt högt?
→ Varför finns det så många nollor?
→ Varför har vi dubbletter av ID-handlingar?
Vilka rapporter kommer jag att förstöra med en schemauppdatering?
Om dessa frågor resonerar med dig, kolla in vår MDM-e-bok för att börja förbättra dina datarutiner!
Tänk dig detta: Det är tisdag morgon och du är datamästaren i ditt IT-team. Plötsligt exploderar din telefon med frenetiska samtal – rapporter går i vasken, dashboards visar alarmerande trender och viktiga affärsbeslut är pausade. Boven? Dålig data.
Här kommer Data Observability in som din superhjälte-sidekick. Istället för att kämpa i blindo skulle du ha en komplett röntgenbild av ditt dataekosystem. Du skulle veta:
- Var problemet har sitt ursprung: Inget mer jagande av spöken i koden!
- Vad är fel med informationen: avslöjar avvikelser som saknade värden, inkonsekvenser eller oväntade toppar.
- Hur det påverkar nedströmsprocesser: visa dominoeffekten på rapporter, instrumentpaneler och kritiska applikationer.
Med denna djupa förståelse kan du:
- Diagnostisera grundorsaken snabbt: Glöm timmar av att gå igenom loggar. AI-driven analys skulle identifiera boven i dramat och spara värdefull tid och frustration.
- Åtgärda problemet effektivt: Inget mer kastande av pilar i mörkret. Tydliga insikter vägleder dig till exakt rätt punkt för ingripande, vilket minimerar driftstopp och datadrivet kaos.
- Förhindra framtida katastrofer: Dataobservabilitet är proaktiv, inte reaktiv. Du kan ställa in automatiska varningar för att upptäcka avvikelser innan de utvecklas till större problem.
Så, inga fler tisdagsmorgons sammanbrott. Istället skulle du vara datagurun, som lugnt navigerar komplexiteten i ditt ekosystem och säkerställer att varje beslut baseras på tillförlitlig och trovärdig information. Det är en superkraft värd att ha!
Dataobservabilitet är praxisen att övervaka och förstå kvaliteten, tillförlitligheten och prestandan hos dina data. Det innebär att spåra och analysera data i realtid för att säkerställa att de är korrekta, fullständiga och konsekventa. Genom att implementera dataobservabilitet kan organisationer få värdefulla insikter i sina data och fatta välgrundade beslut.
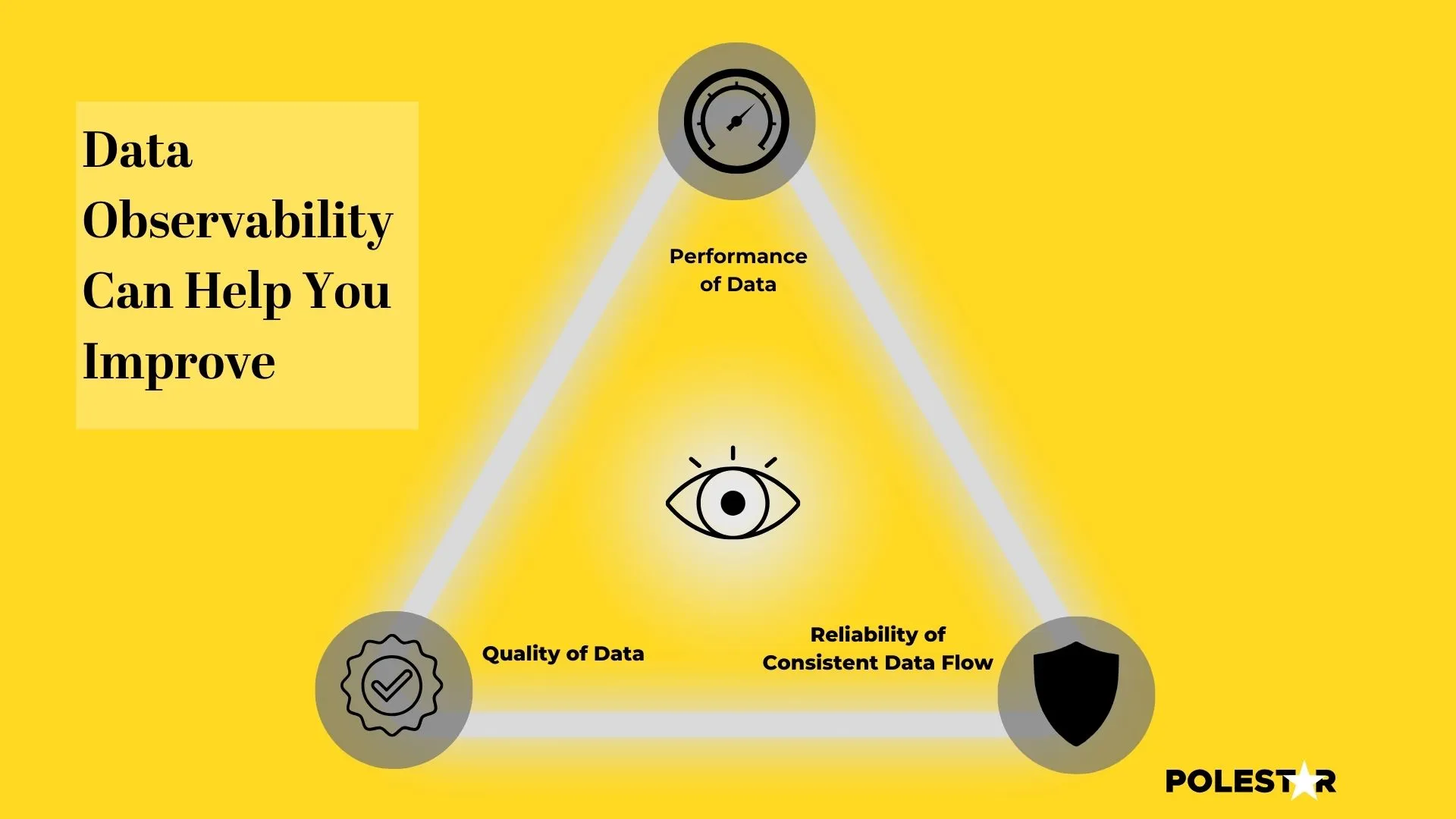
En av de viktigaste aspekterna av dataobservabilitet är datakvalitet. Det är viktigt att säkerställa att de data som samlas in och bearbetas är av hög kvalitet och uppfyller de krav som ställs. Dataobservabilitet hjälper till att identifiera och lösa problem relaterade till datakvalitet , såsom saknade eller felaktiga data, dubbla poster och datainkonsekvenser.
En annan viktig aspekt av dataobserverbarhet är datatillförlitlighet. Organisationer måste säkerställa att den data de förlitar sig på är tillförlitlig och kan användas för kritiskt beslutsfattande. Dataobserverbarhet hjälper till att övervaka datakällor, upptäcka avvikelser och säkerställa tillförlitligheten hos datapipelines.
Dataobserverbarhet spelar också en avgörande roll för att säkerställa datasystemens prestanda. Det hjälper till att övervaka prestandan hos datapipelines, identifiera flaskhalsar och optimera databehandling för att förbättra systemets övergripande prestanda.
Det är viktigt att förstå att dataprestandahantering och dataobservabilitet är sammanflätade partners. De ska inte förväxlas med varandra. Medan prestationshantering spårar pulsen i ditt dataekosystem, fungerar observabilitet som röntgenbilden och avslöjar dess interna hälsa och potentiella sårbarheter.
Enligt Gartner kommer 30 % av företag som implementerar distribuerade dataarkitekturer år 2026 att ha antagit dataobservationstekniker för att förbättra insynen i datalandskapets tillstånd, en ökning från mindre än 5 % år 2023.
De fem pelarna färskhet, kvalitet, volym, schema och avstamning ger dig möjlighet att optimera datapipelines , förebygga problem innan de uppstår och frigöra den verkliga potentialen hos dina data för välgrundade beslutsfattande.
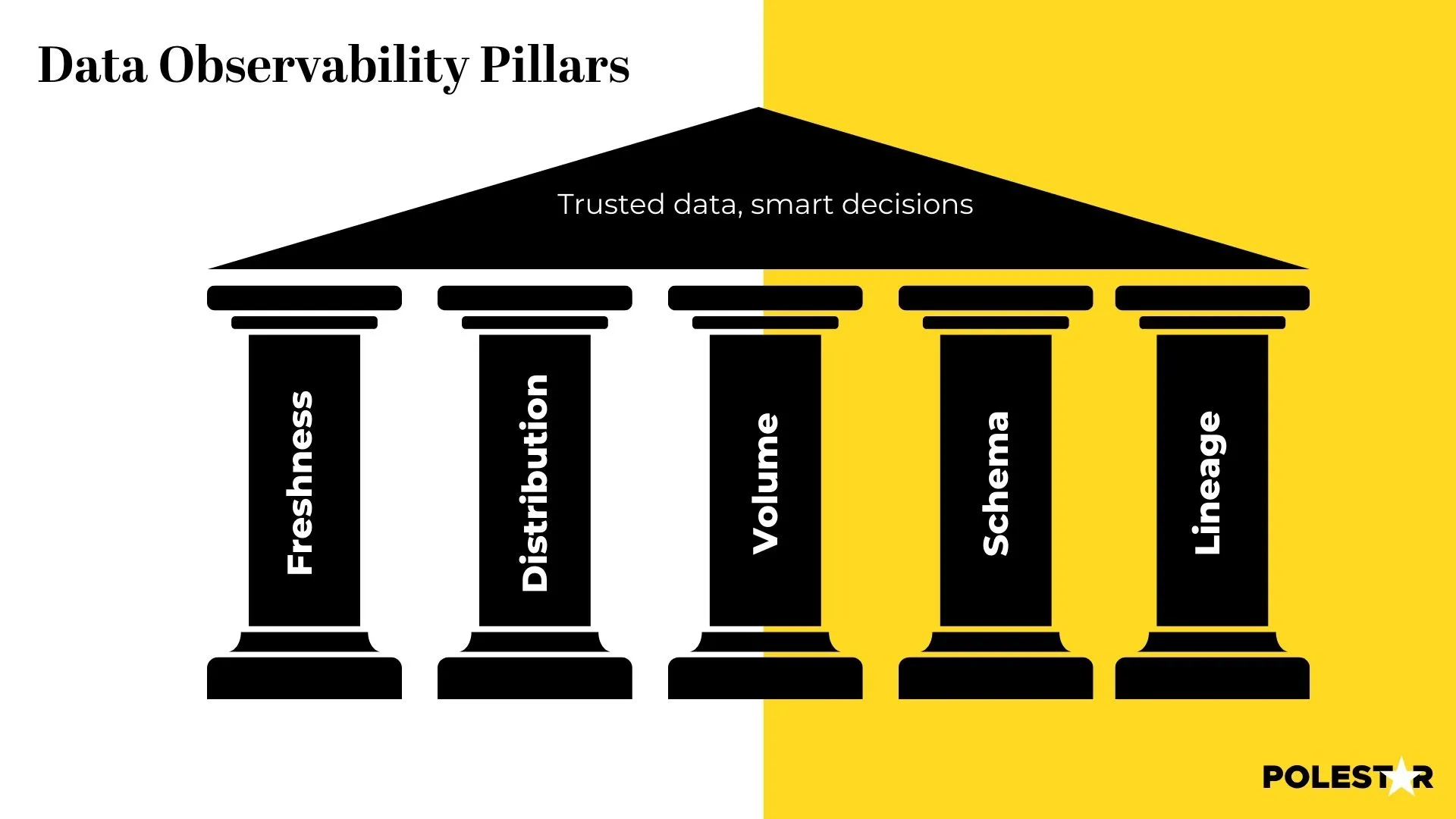
Automatiserad övervakning av aktualitet: Att säkerställa att data är uppdaterade och mindre benägna att förfalla är en prioritet, det möjliggör snabb identifiering och lösning av potentiella problem.
Distributions-KPI:er: Distributionen övervakas för att säkerställa att den följs inom tillförlitliga intervall, samtidigt som dataintegritet och tillförlitlighet upprätthålls.
Volym och fullständighet: Mått fastställer tillgängligheten av viktiga data.
Schema: Definierar datastrukturen, inklusive datatyper, relationer och begränsningar, och säkerställer att data är strukturerade, organiserade och tolkningsbara.
Härstamning: Att identifiera källan till problem, bidra till snabba lösningar.
Dataobservabilitet ses ofta huvudsakligen utifrån datakvalitetsperspektiv, och vissa anser att termerna är utbytbara. Även om det finns likheter mellan de två koncepten finns det skillnader. Datakvalitet fokuserar främst på själva data, medan dataobservabilitet utvidgar sina perspektiv till att omfatta systemet och miljön som ansvarar för att leverera data.
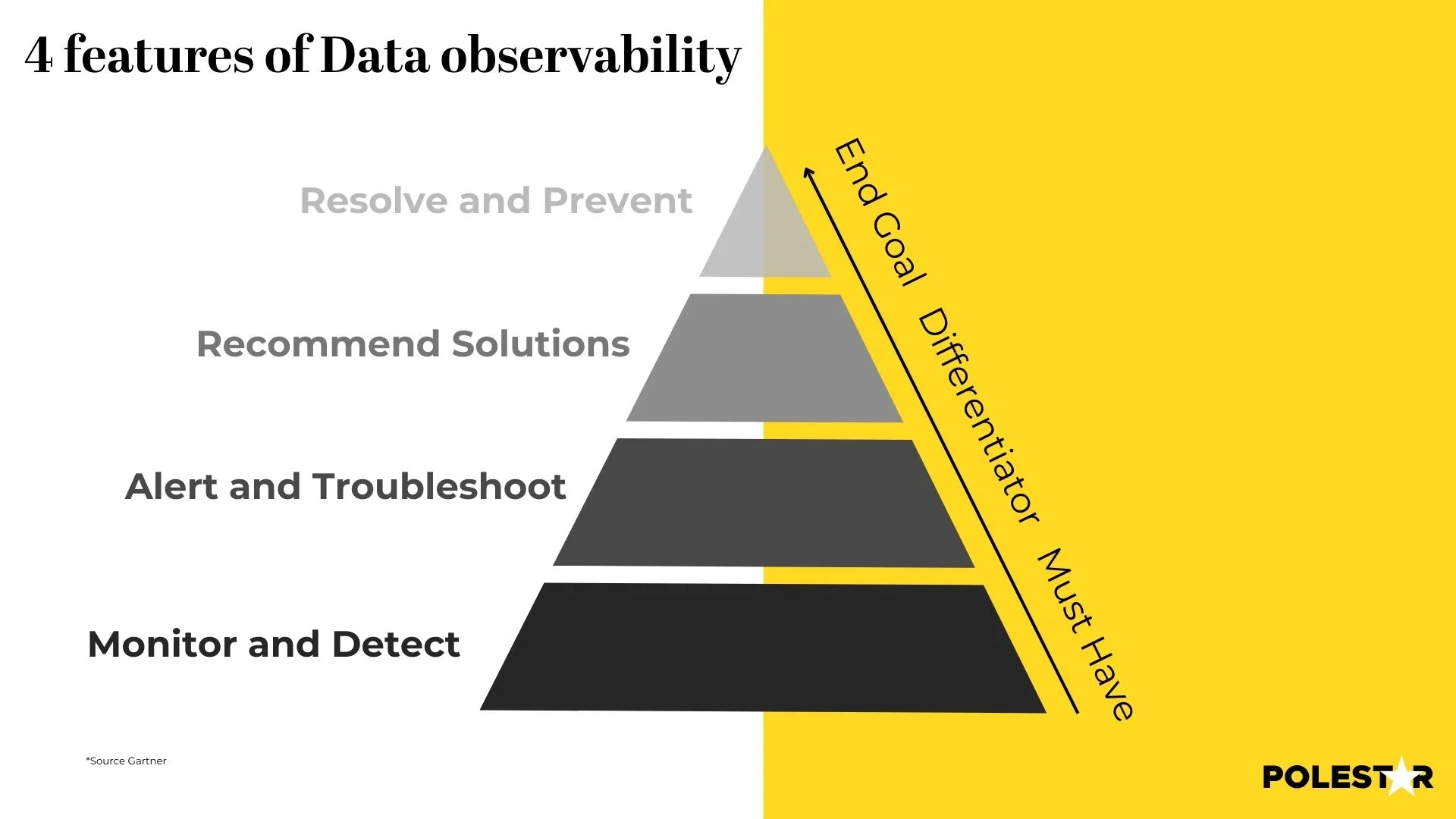
→ Övervaka och upptäck: Dataobservabilitet samlar in och analyserar signaler från olika kanaler och erbjuder ett heltäckande perspektiv på prestandan hos datapipelines. Den bedömer datakvaliteten, identifierar problem och säkerställer sömlös drift.
→ Aviseringar och felsökning: Den kategoriserar problem efter brådska och allvarlighetsgrad och skickar ut aviseringar i rätt tid för snabb respons. Grundorsaksanalys utförs, vilket möjliggör effektiv felsökning och lösning.
→ Rekommendationer: Skräddarsydda rekommendationer ges baserat på analysen – allt från informativa insikter för äldre system till brådskande lösningar för kritiska problem. Denna personliga strategi skiljer leverantörer åt.
→ Lös och förebygg: Genom att implementera rekommendationer kan användare åtgärda problem, optimera datapipelines och undvika systemavbrott. Denna proaktiva metod säkerställer kontinuerlig dataintegritet och systemstabilitet.
För att uppnå effektiv dataobserverbarhet bör organisationer sträva efter att nå detta steg:
End-to-End-synlighet: Säkerställ observerbarhet över dataströmmar, sjöar och lager. Upptäck och åtgärda dataproblem tidigt genom att förstå hela dataflödet.
Flexibelt stöd för dataformat: Använd en mängd olika dataformat, inklusive strukturerade och semistrukturerade (t.ex. JSON-blobbar). Omfattande observerbarhet kräver övervakning av olika datatyper.
Granulära valideringstekniker: Gå bortom endimensionell statistik för att validera enskilda datapunkter och beakta beroenden mellan fält. Univariat och multivariat validering säkerställer datanoggrannhet på alla nivåer.
Konfigurerbara validerare: Hitta en balans mellan automatiserade förslag och manuell konfiguration. Säkerställ skalbarhet genom att tillåta anpassning utan komplexa kodningskrav.
Validering av flera kadenser: Stöd för validering vid olika tidshorisonter, inklusive realtid. Anpassa till olika datauppdateringsfrekvenser för snabba insikter.
Användarcentrerat tillvägagångssätt: Tillgodoser både tekniska och icke-tekniska användare. Erbjud flera kontrolllägen, demokratiserar datakvaliteten och främjar samarbete mellan avdelningar.
Att implementera dataobservabilitet erbjuder många fördelar för organisationer. Några av de viktigaste fördelarna inkluderar:
1. Förbättrad datakvalitet: Dataobserverbarhet hjälper till att övervaka och säkerställa datakvaliteten, vilket leder till förbättrad noggrannhet och tillförlitlighet.
2. Förbättrad datatillförlitlighet: Genom att övervaka datakällor och pipelines kan organisationer säkerställa datatillförlitligheten, vilket gör att de kan fatta viktiga beslut med tillförsikt.
3. Snabbare problemdetektering och lösning: Dataobservabilitet möjliggör realtidsövervakning av data, vilket gör det möjligt för organisationer att snabbt upptäcka och lösa problem relaterade till datakvalitet, tillförlitlighet och prestanda.
4. Ökad datasynlighet: Dataobservabilitet ger organisationer insyn i sina datapipelines, vilket gör att de kan identifiera flaskhalsar, optimera databehandling och förbättra den övergripande systemets prestanda.
Sammantaget kan implementering av dataobservabilitet hjälpa organisationer att frigöra den fulla potentialen hos sina data, förbättra den operativa effektiviteten och få en konkurrensfördel på marknaden.
Området dataobservabilitet är i ständig utveckling, och flera framtida trender förväntas forma dess utveckling. Några av de viktigaste framtida trenderna inom dataobservabilitet inkluderar:
1. AI-driven dataobservabilitet: Användning av artificiell intelligens och maskininlärningstekniker för att förbättra dataobservabilitet och automatisera dataövervakning och analys.
2. Dataobservabilitet i realtid: Övergången till dataobservabilitet i realtid gör det möjligt för organisationer att övervaka och analysera data i realtid, vilket leder till snabbare problemupptäckt och lösning.
3. Dataobservabilitet för moln- och hybridmiljöer: Det ökade antagandet av moln- och hybridmiljöer kräver utveckling av dataobservabilitetsmetoder som är specifikt utformade för dessa miljöer.
4. Integrering med datastyrning: Integrering av dataobservationsmetoder med ramverk för datastyrning för att säkerställa dataefterlevnad, integritet och säkerhet.
5. Prediktiv dataobserverbarhet: Användning av prediktiv analys för att förutse och förebygga dataproblem innan de uppstår, vilket förbättrar datatillförlitlighet och prestanda.
Genom att anamma dessa framtida trender kan organisationer ligga steget före och utnyttja dataobserverbarhet för att driva innovation och affärsframgång.
Genom att utnyttja vår djupa analysexpertis kan ni sömlöst implementera mätningar av dataobservabilitet. Våra workshops för dataupptäckt avslöjar dataflöden och potentiella flaskhalsar, vilket underlättar strategisk implementering av observabilitet.
Vi vägleder valet och integrationen av optimala observationsverktyg och skräddarsyr lösningar för att möta specifika datapipelines och kvalitetskrav. Med Polestars omfattande stöd får företag en tydlig bild av sin datahälsa, vilket banar väg för förbättrad effektivitet och datadrivna beslut.
Vi hjälper dig att implementera "Automatiserad observerbarhet" för molnbaserade och hybridmiljöer så att din molnkomplexitet förenklas.