 Kshitij GuptaDatastrateg
Kshitij GuptaDatastrateg
Registrera dig för att få de senaste insikterna och uppdateringarna inom teknik, AI och dataanalys, datavetenskap och innovationer från Polestar Analytics.
I årtionden innebar det att bygga en realtids-AI-applikation att hantera två fundamentalt inkompatibla system. Analys- och maskininlärningsinfrastrukturen stod på ena sidan – i en datasjö eller ett lager byggt för dataflöde. Den operativa databasen stod på den andra – en fristående PostgreSQL-instans som fångade upp vad användarna faktiskt gjorde just nu. Mellan dem fanns en spröd pipeline: ändringsdatainsamlingsjobb, ETL-synkroniseringar och replikeringslogik som gick sönder enligt ett schema och introducerade latens mätt i minuter, inte millisekunder.
Kostnaden för den här arkitekturfragmenteringen är väl dokumenterad. Organisationer lider i genomsnitt 12,9 miljoner dollar årligen i förluster som direkt kan hänföras till dålig datakvalitet – en siffra som förvärras när AI-system i realtid tvingas arbeta med inaktuella, försenade data.
Ändå kommer organisationer fram till 2026 att överge 60 % av AI-projekt som inte stöds av AI-klar data. Flaskhalsen är inte beräkningsförmågan, och det är inte modellkvaliteten. Det är avståndet mellan transaktionsdata och AI-systemen som försöker resonera kring den.
Databricks Lakebase är det arkitektoniska svaret på den bristen. Operativa databaser är en marknad på över 100 miljarder dollar som ligger till grund för varje applikation. Men de är baserade på årtionden gammal arkitektur utformad för långsamt föränderliga appar, vilket gör dem svåra att hantera, dyra och benägna att låsas in till leverantörer. AI introducerar en ny uppsättning krav: varje dataapplikation, agent, rekommendation och automatiserat arbetsflöde behöver nu snabba, tillförlitliga data med AI-agenters hastighet och skala .
Sedan lanseringen i juni 2025 har implementeringen ökat mer än dubbelt så snabbt som Databricks datalagerprodukt, med tusentals företag som kör produktionsarbetsbelastningar direkt på sina operativa data.
Det konventionella tillvägagångssättet för att bygga dataapplikationer tvingade fram en tung ingenjörsmässig avvägning. Man var tvungen att balansera det informativa användningsfallet – historisk kontext, generering av ML-funktioner, analytiska frågor – mot det transaktionella användningsfallet – att fånga vad en användare klickade på för tre sekunder sedan, uppdatera inventariet i realtid och bevara agentens tillstånd mitt i arbetsflödet.
Att hantera båda innebar att man behövde använda separata databaser som var sammankopplade med ömtåliga pipelines. Problemets omfattning är betydande: datateam rapporterar i genomsnitt 67 pipeline-incidenter per månad, och 68 % av teamen behöver fyra timmar eller mer bara för att upptäcka ett fel när det inträffar. Dataingenjörer blev pipeline-brandmän. ML-modeller frågade efter data som redan var föråldrad när den anlände. AI-applikationer i realtid blev en självmotsägelse.
Lakebase på Databricks databasplattform är inte bara "Postgres på Databricks". Det är ett skifte i hur vi tänker kring operativa och analytiska data som lever tillsammans – styrda, frågbara och drivna av samma plattform.
Istället för att skapa en separat databas, bygga omvända ETL-jobb och hantera autentisering på två ställen, kan team nu synkronisera styrda Lakehouse-tabeller till Postgres med frågetider på millisekunder , bygga applikationstillstånds- och transaktionstabeller direkt i Databricks Lakebase och säkra allt med Databricks-identiteter och Postgres-roller.
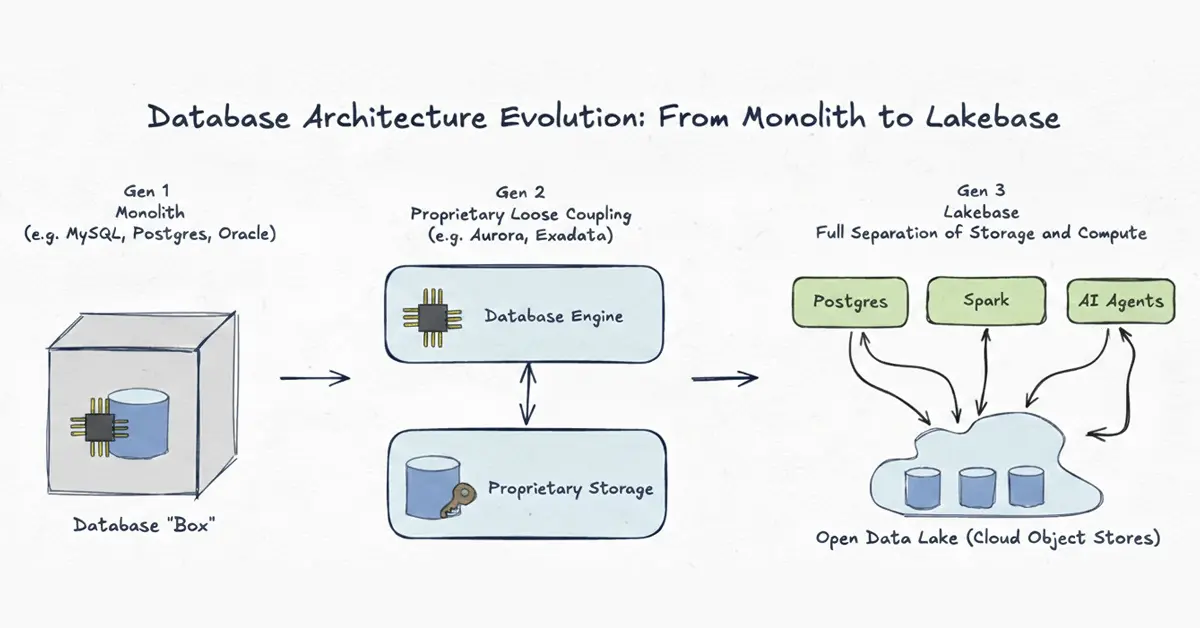
Hur databasarkitekturen har utvecklats över tre generationer – från monolitiska lokala system till helt frikopplad, öppen Lakebase-arkitektur. Separationen av beräkning och lagring är det centrala genombrottet som gör AI-applikationer i realtid gångbara utan ömtåliga pipelines.
Databricks Lakebase förenklar applikationsutveckling med en beprövad OLTP-databas, utan huvudvärken med databashantering. Det eliminerar komplexa, anpassade ETL-pipelines och säkerställer att transaktionsdata integreras i analys- och Databricks AI-nativa applikationer. Team kan undvika utvecklingsförseningar genom att använda välbekanta Postgres med öppen källkod med befintliga bibliotek , ramverk och SQL – med frikopplad beräkning och lagring för oberoende skalning, återställning vid tidpunkten och möjligheten att versionsgenerera en databas som kod.
Databricks Lakebase-arkitektur kombinerar Postgres tillförlitlighet och förtrogenhet med moderna databasfunktioner, inklusive autoskalning, skalning till noll, förgrening och omedelbar återställning. Dessa funktioner möjliggör flexibla utvecklingsarbetsflöden, kostnadseffektiv drift och snabb iteration. Plattformen integreras med realtidsfunktionsvisning för ML-modeller och Feature Store, agentstatus för AI-agenter och transaktionsdata för Databricks-appar eller andra applikationer som är anslutna till dem.
Data rör sig i två riktningar mellan Lakehouse och Lakebase:
Båda riktningarna. Inga anpassade pipelines!
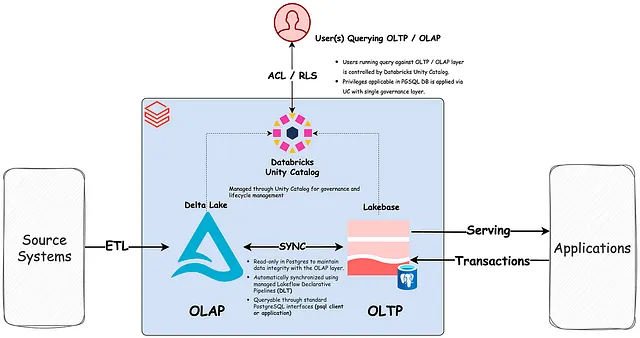
Databricks Lakebase-arkitektur: transaktionell beräkning (Postgres) körs oberoende ovanpå öppen lagring i sjön, vilket förenar OLTP- och OLAP-arbetsbelastningar på en enda styrd grund – utan ETL-pipelines mellan dem.
Lakebase Databricks-plattformen levererar en uppsättning funktioner i produktionsklass:
| Särdrag | Vad den gör | Varför det spelar roll |
|---|---|---|
| Serverlös autoskalning och skalning till noll | Beräkningen anpassar sig dynamiskt till trafiken; stängs av vid inaktivitet | Eliminerar slöseri med pengar på ledig infrastruktur |
| Omedelbar databasförgrening | Skapar nollkopia-kloner av produktionsdata på några sekunder | Riskfri testning utan att duplicera fullständiga datamängder |
| Återställning vid tidpunkten (PITR) | Återställer databasen till valfri millisekund inom kvarhållningsfönstret | Skydd mot oavsiktliga raderingar och programfel |
| Styrning av enhetskatalogen | En enda säkerhetsmodell för operativa och analytiska data | En åtkomstkontrollpolicy för hela datatillgången |
| Synkronisera tabeller | Håller Lakehouse- och Lakebase-data automatiskt justerade | Inga ömtåliga pipelines; inga manuella synkroniseringsjobb |
| Postgres 17-stöd + pgvector | Full Postgres-kompatibilitet inklusive AI-baserad vektorsökning | Använd befintliga verktyg; aktivera semantisk sökning och likhetssökning direkt |
Förgreningsfunktionen förtjänar särskild uppmärksamhet. Precis som Git för din databas låter förgreningar team skapa isolerade miljöer från produktionsdata på några sekunder – testa schemaändringar, validera ny applikationslogik, köra belastningstester – utan att behöva röra vid live-arbetsbelastningar eller betala för fullständig dataduplicering.
Att få en produktionsklar applikation att köras på Lakebase Databricks-plattformen följer en strukturerad process. Dokumentationen för Microsoft Azure Databricks Lakebase och Databricks-bloggen om att bygga produktionsklara appar beskriver båda detta i detalj.
De viktigaste faserna är:
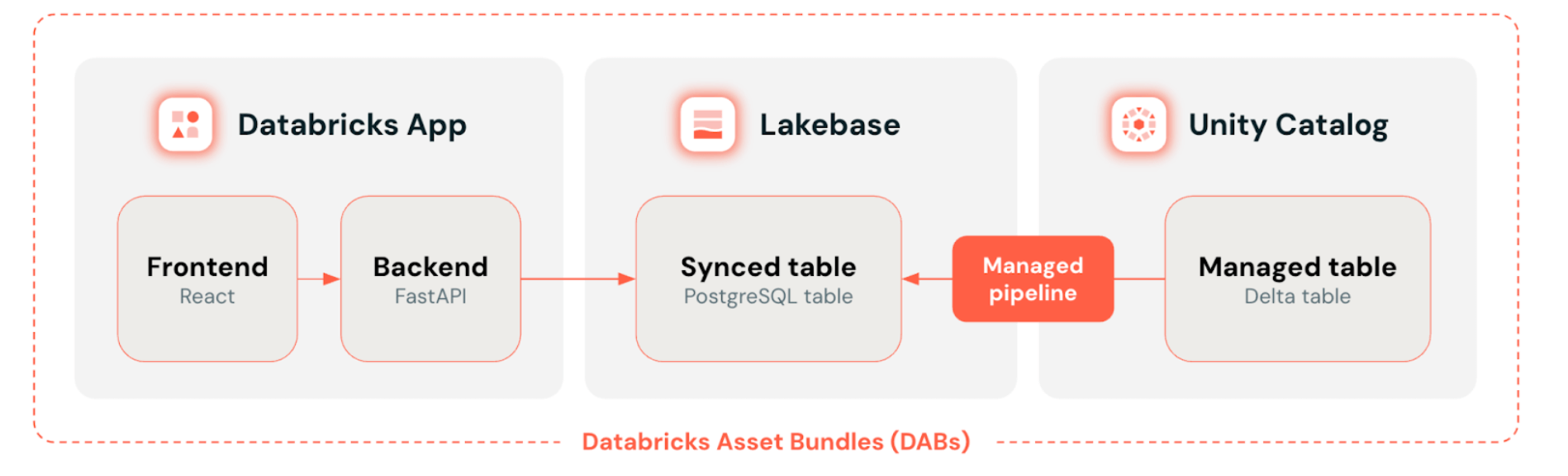
Hur en produktionsklar dataapplikation sätts samman på Lakebase Databricks-plattformen: Databricks Apps i frontend, Databricks Lakebase som transaktionsdatalager, Unity Catalog som hanterar styrda deltatabeller med automatisk synkronisering – allt distribuerat som kod via Databricks Asset Bundles.
Användningsfallen för Lakebase-databasen spänner över branscher och arkitekturmönster. Databricks Lakebase identifierar följande primära arbetsbelastningstyper:
| Industri | Användningsfall för Lakebase-databasen | Vad den ersätter |
|---|---|---|
| Detaljhandel och e-handel | Personliga rekommendationer och erbjudandeinriktning i realtid | Fristående rekommendationsmotorer som matas av fördröjda batchpipelines |
| Hälsovård | Datahantering för kliniska prövningar tillsammans med prediktiva diagnostiska modeller | Silo-baserade OLTP-databaser frånkopplade från analytiska ML-lager |
| Finansiella tjänster | Automatiserad analys av bedrägerier inom handel och streaming | Separata operativa databaser med CDC-pipelines till analyser |
| Tillverkning | Maskintelemetriinmatning och arbetsflöden för prediktivt underhåll | Lokala historiksystem med manuella dataexportjobb |
| Media och underhållning | Personliggörande av innehåll i realtid och spårning av publikens engagemang | Fragmenterad händelsespårning med fördröjd lagersynkronisering |
Databricks Lakebase är byggd för ett specifikt problem. Det är inte en universell ersättning för alla operativa databaser. Här är ett tydligt ramverk för att utvärdera lämplighet:
Använd Databricks Lakebase när:
Azure Databricks Lakebase- användare bör notera plattformens nuvarande regionala tillgänglighet för autoskalning – som täcker större AWS- och Azure-regioner – innan de granskar latenskänsliga globala distributioner. Azure-dokumentationen beskriver regioner som stöds och konfigurationsspecifikationer.
Databricks Lakebase stöder latens på under 10 ms för arbetsbelastningar med högt genomflöde, vilket täcker den stora majoriteten av kraven för företags AI-applikationer. Kombinationen av Databricks Lakebase med OLTP-databasen gör det möjligt att lösa arkitekturproblem på ett fundamentalt annorlunda sätt, med en tydlig väg bort från bräckliga ETL-pipelines och den påtvingade separationen av analytiska och operativa lager.
Databricks Lakebase är nu allmänt tillgänglig på AWS och i betaversion på Azure, med ett växande ekosystem av lanseringspartners som har validerat det för databasmodernisering, utveckling av realtidsapplikationer och agentbaserade AI-arbetsflöden. Databricks Lakebases lanseringspartners är redo att hjälpa kunder att dra nytta av denna förändring, efter att ha validerat Lakebase Databricks-plattformen för databasmodernisering, byggande av realtidsapplikationer och driftsättning av agentbaserade AI-arbetsflöden.
Polestar Analytics är bland dessa lanseringspartners. Som Databricks AI-native implementeringsspecialist inom datateknik, AI-applikationer och Databricks Lakebase-arkitektur , tillför Polestar Analytics implementeringsmetodiken – arkitekturdesign, dataflödesmappning, styrningskonfiguration och applikationsintegration – som omvandlar en tekniskt kapabel plattform till ett produktionssystem som fungerar tillförlitligt och skalas förutsägbart. Databricks databasplattform eliminerar den arkitektoniska flaskhalsen. En beprövad implementeringspartner eliminerar distributionsrisken.
Databricks Lakebase-integrationskarta: Var Lakebase befinner sig i den fullständiga plattformen
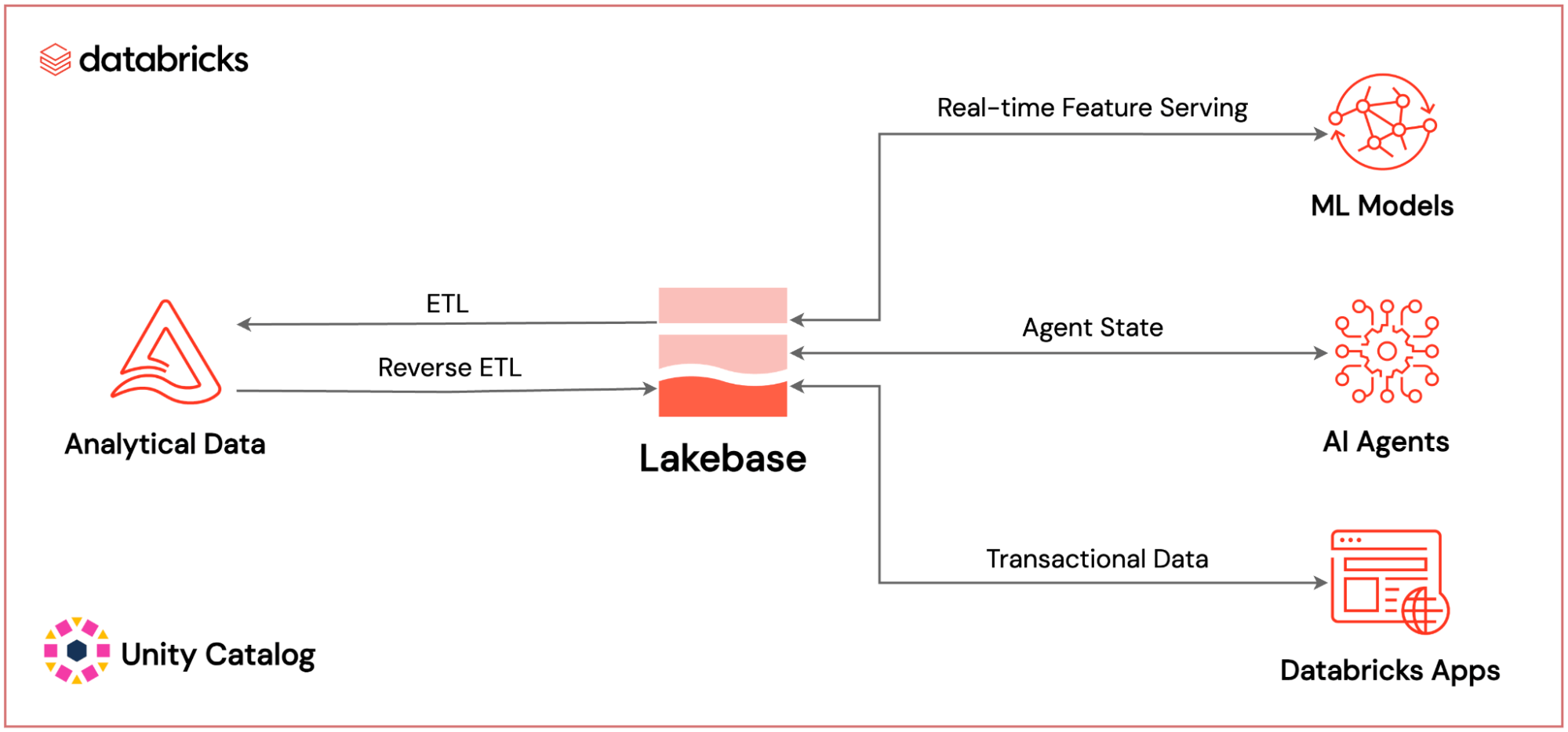
Var Databricks Lakebase sitter inom den fullständiga Databricks AI-nativa plattformen: driver ML-funktionsvisning i realtid, AI-agentstatuspersistens och applikationstransaktionsdata – allt styrs av Unity Catalog.
Bygg din realtids-AI-applikation på Databricks Lakebase. Från Databricks Lakebase-arkitekturdesign till produktionsdistribution – Polestar Analytics vägleder varje fas av din implementering.
Prata med vårt teknikteamLakebase hanterar dubbelriktad dataförflyttning genom två dedikerade mekanismer, Synced Tables och Lakehouse Sync, som båda fungerar utan anpassade pipelines. Konsekvens bibehålls på plattformsnivå, vilket eliminerar de manuella ETL-jobben som traditionellt driftar, misslyckas tyst eller introducerar latens.
Nej, Lakebase är Postgres 17-kompatibelt, så befintliga drivrutiner, ORM:er, SQL-frågor och bibliotek fortsätter att fungera utan modifieringar. Förändringen ligger i var Postgres körs och vad det ansluter till, inte i hur utvecklare interagerar med det dagligen.
Ja, team använder det idag för operativa dashboards, realtidsanpassning och transaktionella appar som helt enkelt behöver ren, styrd data utan pipeline-overhead. AI-funktionerna finns där när du är redo, men de är inte en förutsättning för att få värde från dag ett.
Om författaren
Datastrateg
De flesta data besvarar frågor. Rätt data ändrar riktning.
Relaterad blogg
Kshitij Gupta