
Sammanfatta detta blogginlägg med:
Redaktörens anmärkning: I takt med att molnbaserade datalager fortsätter att utvecklas kan innovationer och förändringar uppstå. I den här bloggen har vi fördjupat oss i de transformerande möjligheterna hos de bästa molnbaserade datalagerlösningarna – Amazon Redshift, Google BigQuery, Snowflake och Azure Data Platform. Dessa tekniker står som pelare inom molnbaserad datalagring, och var och en erbjuder unika styrkor och funktioner som tillgodoser olika affärsbehov.
Introduktion
Data är den viktigaste resursen i alla företag idag. Ett generellt paradigmskifte under åren har sett lagrings- och beräkningsrollen öka för att stärka affärsmodulernas omfattning och intensitet.
När det gäller lagring är vi alla medvetna om datalagerkonceptet som ger företag möjlighet att segmentera och urskilja data för att utvinna värdefulla insikter från dem för att fatta exakta och kloka affärsbeslut.
Ett datalager fungerar också som ett centralt arkiv för all data som samlas in av ett företag via olika interna och externa källor. Det hjälper till vid rapportering och dataanalys.
Eftersom datalagret använder data från olika källor och medier, inklusive relationsdatabaser, NoSQL-databaser eller tredjeparts-API:er, är kvoten av tvetydiga data exceptionellt hög. Därför måste all insamlad data kombineras till en enda sammanhängande datamängd och optimeras för att leverera snabba lösningar för kritiska databasfrågor.
En modern strategi för molnmigrering: De 6 R:na
Tidigare var datalagret endast tillgängligt som lokala lösningar, vilka mestadels var applikationsbaserade, vilket gjorde det svårt att expandera datalager.
Så, med tanke på marknadens behov, har vi här några av de robusta datalagerplattformarna .

Amazon Redshift är en datalagerprodukt som ingår i den större molntjänstplattformen Amazon Web Services . Det är en enkel och kostnadseffektiv datalagerlösning som analyserar all användardata i deras lokala datalager och datasjöar.
Amazon Redshift kan leverera tio gånger snabbare prestanda än traditionella lösningar och utnyttjar kraften i maskininlärning, massivt parallell frågekörning och kolumnär lagring på en högpresterande disk. Användare kan enkelt konfigurera och driftsätta ett nytt datalager på några minuter och köra frågor över petabyte data i Redshift-datalagret och exabyte data i sin datasjö som är byggd på Amazon S3.
Nu ska vi titta på Amazons Redshift-arkitektur . Det här avsnittet belyser komponenterna i AWS Redshift-arkitektur, vilket ger dig tillräckligt med tips för att avgöra om den är gynnsam för ditt användningsfall. Nedan visas ett diagram över Redshift-arkitekturen:
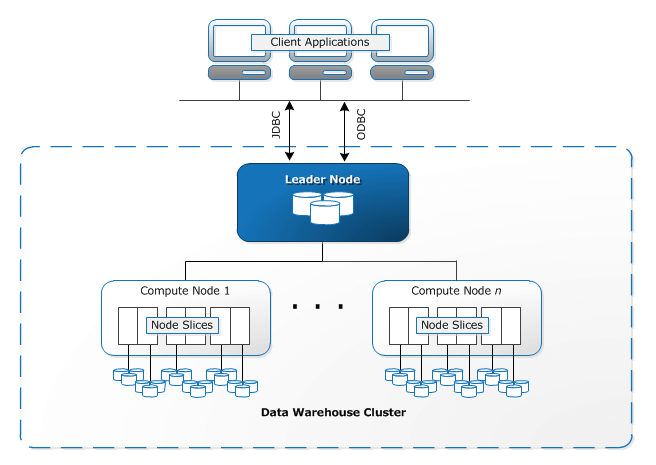
Redshift-kluster: Redshift använder ett kluster av noder som sin kärninfrastrukturkomponent. Ett kluster har vanligtvis en ledarnod och flera beräkningsnoder. I de fall där det bara finns en beräkningsnod finns det ingen ytterligare ledarnod.
Beräkningsnoder: Varje beräkningsnod har sin egen processor, minne och lagringsdisk. Klientapplikationer är omedvetna om att det finns beräkningsnoder och behöver aldrig ha direkt kontakt med beräkningsnoder.
Ledarnod: Ledarnoden ansvarar för all kommunikation med klientapplikationer. Ledarnoden hanterar även samordningen av beräkningsnoder. Frågeparsning och utveckling av exekveringsplaner är också ledarnodens ansvar. När ledarnoden tar emot en fråga skapar den exekveringsplanen och tilldelar den kompilerade koden till beräkningsnoder. En del av data tilldelas varje beräkningsnod. Den slutliga aggregeringen av resultaten utförs av ledarnoden.
Drag
Massivt parallell
Amazon Redshift levererar snabb frågeprestanda på datamängder som varierar i storlek från gigabyte till exabyte. Redshift använder kolumnlagring, datakomprimering och zonkartor för att minska mängden I/O som behövs för att utföra frågor. Den använder MPP-datalagerarkitektur (Massivt Parallel Processing) för att parallellisera och distribuera SQL-operationer för att dra nytta av alla tillgängliga resurser. Den underliggande hårdvaran är utformad för högpresterande databehandling , med lokalt ansluten lagring för att maximera genomströmningen mellan processorer och hårddiskar, och ett bandbreddfritt mesh-nätverk för att maximera genomströmningen mellan noder.
Maskininlärning
Amazon Redshift använder maskininlärning för att leverera hög kvalitet genomgående, oavsett arbetsbelastning eller samtidig användning. Den använder sofistikerade algoritmer för att förutsäga körtider för inkommande frågor och tilldela dem den optimala kön för snabbast möjliga bearbetning. Till exempel dirigeras frågor som dashboards och rapporter med höga samtidighetskrav till en expresskö för omedelbar bearbetning.
Automatiserad provisionering
Amazon Redshift är enkelt att konfigurera och använda. Du kan driftsätta en ny DW med bara några få klick i AWS Management Redshift och konsolen etablerar automatiskt infrastrukturen för användare. De flesta omfattande uppgifter automatiseras, som säkerhetskopiering och replikering, så att du kan fokusera på dina data, inte administrationen. Redshift erbjuder alternativ som hjälper dig att anpassa dig till dina specifika arbetsbelastningar när du vill kontrollera dem. Nya funktioner släpps transparent, vilket eliminerar behovet av att schemalägga och tillämpa uppgraderingar och patchar.
Feltolerant
Amazon Redshift har flera funktioner som förbättrar tillförlitligheten hos ditt datalagerkluster. Redshift övervakar kontinuerligt klustrets hälsa, replikerar automatiskt data från trasiga hårddiskar och ersätter noder vid behov för feltolerans.
Flexibel frågehantering
Amazon Redshift ger dig flexibiliteten att köra frågor i konsolen eller ansluta SQL-klientverktyg, bibliotek eller Business Intelligence-verktyg som du använder. Query Editor i AWS-konsolen tillhandahåller ett kraftfullt gränssnitt för att köra SQL-frågor på Redshift-kluster och visa frågeresultat och frågekörningsplan (för frågor som körs på beräkningsnoder) intill dina frågor.
Lista över några nöjda Amazon Redshift-kunder
- Gläfsa
- Duolingo
- Comcast
- Dagjämning
- Dow Jones

Googles BigQuery är ett molnbaserat datalager i företagsklass. Det lanserades först som en tjänst 2010 med allmän tillgänglighet i november 2011. Sedan starten har BigQuery utvecklats till ett mer ekonomiskt och fullständigt hanterat datalager som kan köra blixtsnabba interaktiva och ad hoc-frågor på datamängder i petabyte-skala. Dessutom integreras BigQuery nu med en mängd olika Google Cloud Platform (GCP)-tjänster och tredjepartsverktyg, vilket gör det mer användbart.
BigQuery är serverlös, eller mer exakt, ett datalager som en tjänst . Det finns inga servrar att hantera eller databasprogramvara att installera. BigQuery-tjänsten hanterar underliggande programvara samt infrastruktur inklusive skalbarhet och hög tillgänglighet. BigQuery erbjuder ett enkelt klientgränssnitt som gör det möjligt för användare att köra interaktiva frågor. Det har också inbyggda maskininlärningsfunktioner.
Nu ett djupdykning i Googles Big Query-arkitektur.
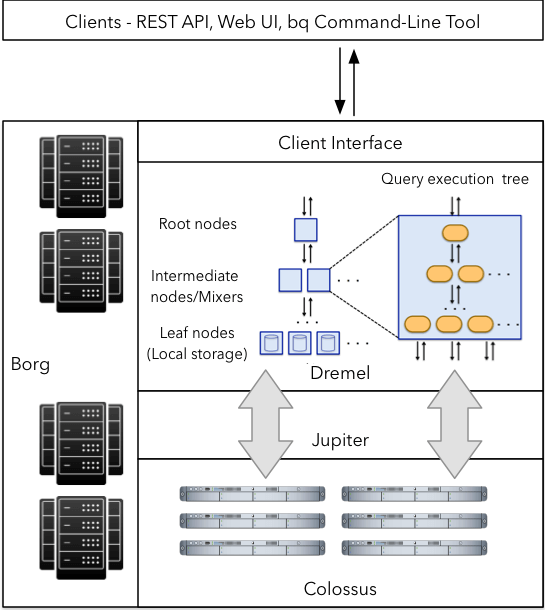
Dremel: Dremel är frågekörningsmotorn som driver BigQuery. Det är ett mycket skalbart system utformat för att köra frågor på petabyte-skaliga dataset. Dremel använder en kombination av kolumnära datalayouter och trädarkitektur för att bearbeta inkommande frågeförfrågningar. Denna kombination gör det möjligt för Dremel att bearbeta biljoner rader på sekunder. Till skillnad från många databasarkitekturer kan Dremel oberoende skala beräkningsnoder för att möta kraven från även de mest krävande frågorna.
Colossus: Colossus är det distribuerade filsystem som används av Google för många av sina produkter. I varje Google-datacenter kör Google ett kluster av lagringsskivor som erbjuder lagringskapacitet för dess olika tjänster. Colossus säkerställer att ingen dataförlust av data lagras på hårddiskarna genom att välja lämpliga replikerings- och katastrofåterställningsstrategier.
Jupiter-nätverket: Jupiter-nätverket är bryggan mellan Colossus-lagringen och Dremels exekveringsmotor. Nätverket i Googles datacenter erbjuder oöverträffade nivåer av dubbelriktad trafik som möjliggör stora volymer dataöverföring mellan Dremel och Colossus.
Drag
BigQuery ML
Detta hjälper experter som analytiker och forskare att bygga och använda ML-modeller på olika datastrukturer med hjälp av enkel SQL. Därefter kan modellerna exporteras till AI-plattformar för vidare förutsägelser och andra operationer.
BigQuery BI-motor
En av BigQuerys bästa funktioner är dess hastighet. Den är ganska snabb och gör det möjligt för användare att analysera även de mest komplexa datagrupperna på bara några sekunder, och det med en högre noggrannhet. BigQuerys BI-motor hjälper också till att integrera med olika verktyg som Data Studio och hjälper experter med olika dataanalyser och utforskningar.
Geospatial analys med BigQuery GIS
BigQuery GIS kombinerar specifikt BigQuerys serverlösa arkitektur med inbyggt stöd för geospatial analys för att utöka analysflöden med platsinformation. Förenkla dina analyser, se spatial data på nya sätt och upptäck helt nya affärsområden med stöd för godtyckliga punkter, polygoner, linjer och multipolygoner i standard geospatiala dataformat.
ML och prediktiv modellering med BigQuery ML
BigQuery ML ger dataanalytiker och dataforskare möjlighet att bygga och operationalisera maskininlärningsmodeller på semistrukturerad eller strukturerad data i planetskala, direkt i BigQuery, med hjälp av enkel SQL – på en bråkdel av tiden. Användare kan exportera BigQuery ML-modeller för online-förutsägelser till Vertex AI eller deras serverlager med den här funktionen.
Dataanalys i flera moln med BigQuery Omni
BigQuery Omni är en flexibel, heltäckande analyslösning för flera moln som ger användarna säker analys och kostnadseffektiv data över moln som Azure och AWS. Den använder standard SQL och BigQuerys välbekanta gränssnitt för att snabbt besvara frågor och dela resultat från en enda ruta över dina datamängder.
Kopplade ark
Användare som inte har SQL-kunskaper kan fortfarande analysera en enorm mängd data med hjälp av sammankopplade ark i BigQuery. Olika verktyg kan användas, såsom diagram, pivottabeller och många andra, för att utvinna insikter från data.
Förutom dessa många funktioner är lagret utrustat med många andra funktioner, såsom realtidsanalys, logisk datalagring, materialiserade vyer, automatisk säkerhetskopiering, dataöverföringstjänster, flexibla kostnadsmodeller, hög säkerhet, programmatisk interaktion och många andra.
Några framstående kunder hos Google BigQuery
- UPS
- Kvittra
- Home Depot
- Dow Jones

Snowflake Inc. är en molnbaserad datalagerstartup som grundades 2012. Snowflake erbjuder en molnbaserad datalagrings- och analystjänst, allmänt kallad "datalager som en tjänst". Det gör det möjligt för företagsanvändare att lagra och analysera data med hjälp av molnbaserad hårdvara och mjukvara.
Snowflakes datalager använder en ny SQL-databasmotor med en unik arkitektur utformad för molnet. Snowflake har många likheter med andra företagsdatalager men har också ytterligare funktionalitet och unika möjligheter.
Låt oss lära oss om snöflingearkitektur .
Snowflakes unika arkitektur består av tre viktiga lager:
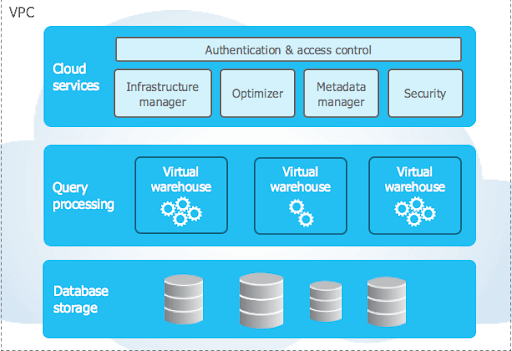
- Databaslagring
- Frågebehandling
- Molntjänster
Databaslagring
När data laddas in i Snowflake omorganiserar Snowflake den informationen till sitt interna optimerade, komprimerade, kolumnära format. Snowflake lagrar denna optimerade information i molnlagring.
Snowflake hanterar alla aspekter av hur dessa data lagras – Snowflake hanterar organisation, filstorlek, struktur, komprimering, metadata, statistik och andra aspekter av datalagring. Dataobjekten som lagras av Snowflake är inte direkt synliga eller tillgängliga för kunder; de är endast tillgängliga via SQL-frågeoperationer som körs med Snowflake.
Frågebehandling
Frågekörning utförs i bearbetningslagret. Snowflake bearbetar frågor med hjälp av "virtuella lager". Varje virtuellt lager är ett MPP-beräkningskluster som består av flera beräkningsnoder som allokerats av Snowflake från en molnleverantör.
Varje virtuellt lager är ett oberoende beräkningskluster som inte delar beräkningsresurser med andra virtuella lager. Som ett resultat har varje virtuellt lager ingen inverkan på prestandan för olika virtuella lager.
Molntjänster
Molntjänstlagret är en samling tjänster som koordinerar aktiviteter över Snowflake. Dessa tjänster knyter samman alla olika komponenter i Snowflake för att bearbeta användarförfrågningar, från inloggning till förfrågning. Molntjänstlagret körs också på beräkningsinstanser som tillhandahålls av Snowflake från molnleverantören.
Turboladda ditt företag med Snowflake Cloud Data Platform
Drag
Enskild plattform
En av de bästa funktionerna hos Snowflake, som den ofta skryter med, är möjligheten att utföra olika aktiviteter på en enda plattform. Användarna kan utföra ett brett spektrum av aktiviteter som apputveckling, datasjöborrning, forskning av dataforskare och mycket annat.
Säkra data
Lagret erbjuder användarna möjligheten att säkert dela data med olika delar av företaget eller till och med kunder utan att behöva stressa över säkerhetsrelaterade problem. Oavsett om det är strukturerad data eller semistrukturerad data, kan användaren dela den live utan att behöva oroa sig för några problem.
Skalbarhet
Snowflakes arkitektur för delad data med flera kluster eliminerar lagrings- och beräkningsresurser. Denna strategi gör det möjligt för användare att skala upp resurser när de behöver enorma mängder data som ska laddas snabbare och skala ner igen när hela processen är över utan några problem med tjänsten. Användare kan börja med ett extra litet virtuellt lager och skala upp och ner efter behov.
Noll underhåll
Användaren får möjlighet att välja olika uppsättningar infrastrukturleverantörer medan Snowflake tar hand om dataplattformen. Lagret är känt för att vara ett av de bästa alternativen för att stödja verksamhetens effektivitet och datasuveräniteten.
Säkerhet
Från hur användare får åtkomst till Snowflake till hur data lagras har Snowflake ett brett utbud av säkerhetsfunktioner. Du kan hantera nätverkspolicyer genom att vitlista IP-adresser för att begränsa åtkomsten till kontot. Snowflake stöder många autentiseringstekniker, inklusive stöd för SSO genom federerad autentisering och tvåfaktorsautentisering. Åtkomst till objekt i kontot utlöses genom en hybridmodell av diskretionär åtkomstkontroll (varje objekt har en ägare som beviljar åtkomst till objektet) och rollbaserad åtkomstkontroll. Denna hybridmetod ger en betydande mängd kontroll och flexibilitet.
Återställ snöflingeobjekt med hjälp av Undrop
Detta är en av de unika funktionerna som är inbyggda i Snowflake. Du kan återställa Snowflake-objekt som av misstag tappas. Ett tappat objekt kan återställas med hjälp av kommandot undrop i Snowflake, så länge objektet fortfarande finns i återställningsfönstret.
Några kunder hos Snowflake
- Mikron
- Yamaha
- Nielsen
- Överlager
- HubSpot
- Adobe

Azure Data Platform är en molnbaserad dataintegrationstjänst som låter dig skapa datadrivna arbetsflöden i molnet för att orkestrera och automatisera dataförflyttning och datatransformation.
Det låter dig skapa datadrivna arbetsflöden för att orkestrera dataförflyttningen mellan stödda datalager och bearbetningen av data med hjälp av beräkningstjänster i andra regioner eller en lokal miljö. Det låter dig också övervaka och hantera arbetsflöden med hjälp av både programmatiska och användargränssnittsmekanismer.
Med hjälp av Azure Data Factory kan du skapa och schemalägga datadrivna arbetsflöden (kallade pipelines) som kan mata in data från olika datalager. Du kan bygga komplexa ETL-processer som visuellt omvandlar data med dataflöden.
Dessutom kan du publicera dina transformerade data till datalager som Azure SQL Data Warehouse för Business Intelligence (BI)-applikationer att använda. I slutändan kan rådata organiseras i meningsfulla datalager och datasjöar för bättre affärsbeslut genom Azure Data Factory.
FÖRSLAG TILL LÄSNING: DATA WAREHOUSE OCH DATA LAKE SAMEXISTENS FÖR FÖRETAG
Nu ska vi dyka in i Azure Data-plattformens arkitektur.
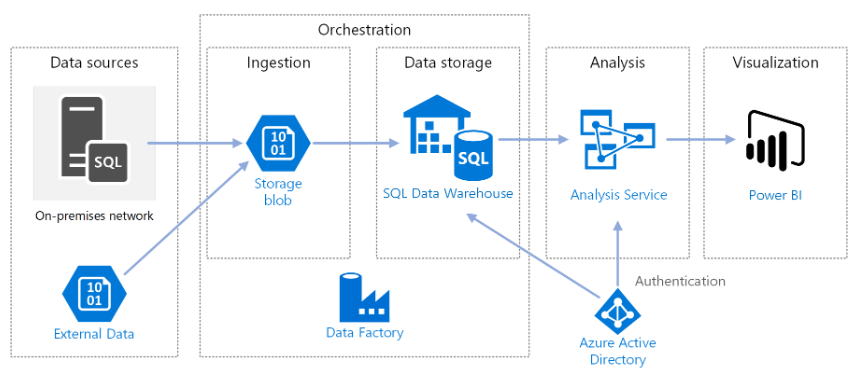
Datakällor
Extern data – Ett vanligt scenario för datalager är att integrera flera datakällor. Denna referensarkitektur laddar en extern datamängd som innehåller stadsbefolkning per år och integrerar den med data från OLTP-databasen. Du kan använda dessa data för insikter som: "Matchar eller överstiger försäljningstillväxten i varje region befolkningstillväxten?"
Inmatning och datalagring
Blob Storage – Blob Storage används som ett mellanlagringsområde för källdata innan de läses in i Azure Synapse .
Azure Synapse – Azure Synapse är ett distribuerat system utformat för att utföra analyser på omfattande data. Det stöder massiv parallell bearbetning (MPP), vilket gör det lämpligt för att köra högpresterande analyser.
Azure Data Factory – Data Factory är en hanterad tjänst som automatiserar dataförflyttning och datatransformation. I den här arkitekturen koordinerar den de olika stegen i ELT-processen.
Analys och rapportering
Azure Analysis Services – Analysis Services är en helt hanterad tjänst som tillhandahåller datamodelleringsfunktioner. Den semantiska modellen laddas in i Analysis Services.
Power BI – Power BI är en svit med affärsanalysverktyg för att analysera data för affärsinsikter. I den här arkitekturen frågar den den semantiska modellen som lagras i Analysis Services.
Autentisering
Azure Active Directory (Azure AD) autentiserar användare som ansluter till Analysis Services-servern via Power BI.
Data Factory kan också använda Azure AD för att autentisera mot Azure Synapse med hjälp av ett tjänstens huvudnamn eller en Managed Service Identity (MSI). För enkelhetens skull använder exempeldistributionen SQL Server-autentisering.
Drag
Datamotståndskraft
Det allra första som alla företag letar efter i ett molnbaserat datalager är säkerhet. När det gäller Microsoft Azure lagras all data säkert i Microsofts datacenter. Microsoft Azure erbjuder extra säkerhet för data om användarna väljer bland olika säkerhetsalternativ som finns tillgängliga i lagret. Detta gör Azure till ett av de säkraste molnbaserade datalagren och en av anledningarna till att fler företag väljer det.
BCDR-integration
Azure-lagring erbjuder inte bara datasäkerhet utan säkerställer också att den är redo för alla typer av dataåterställningsåtgärder. Det betyder att den också tillhandahåller rätt mängd säkerhetskopieringsfunktioner för data. Flera kunder och företag använder också Microsoft Azure enbart för att det kan tillhandahålla en av de bästa säkerhetskopiorna som stöder data.
Kapacitetshantering
Kapacitetsplanering och hantering kan vara mycket tidskrävande. Å andra sidan används Microsoft Azure med hybridarkitektur i lagringslösningar. Under denna funktion erbjuder lagret många alternativ som arkivering, datanivåer, komprimering och många andra för att hantera kapaciteten väl.
Enskilda rutor
Tillsammans med de andra funktionerna som erbjuds av Microsoft Azure, är en annan framträdande funktion som erbjuds enkelpanelsfunktioner. Detta hjälper användarna att få bättre överblick över insikterna och hantera dem bättre.
Några kända kunder som använder Microsoft Azure
- Ö
- Kennametal
- H&R-blocket
- Cincinnatis barnsjukhus
När data har blivit en av de viktigaste delarna av verksamheten är det avgörande att ta hand om den på det mest effektiva sättet. Att ha rätt molnbaserade datalagertjänster är den perfekta lösningen i ett sådant fall. Att välja rätt plattform kan vara en utmanande uppgift, men att välja den bästa leverantören kan erbjuda rätt plattform till företag.