
Sammanfatta detta blogginlägg med:
Redaktörens anmärkning: Sökandet efter den optimala molnbaserade datalagringslösningen är både kostnadsintensivt och tekniskt krävande. Denna analys dissekerar de tekniska aspekterna av AWS Redshift och Google BigQuery, och erbjuder en utforskning av deras arkitekturer, funktioner och lämplighet för olika affärsbehov. Även om det finns ett "noize-fits-all"-koncept när det gäller datalager , syftar bloggen till att hjälpa CXO:er och beslutsfattare att skapa kopplingar mellan sina befintliga arkitekturer och hitta det bästa alternativet.
Datalagerhantering har utvecklats avsevärt under det senaste decenniet tack vare framväxten av molntjänster och big data-tekniker. Molnbaserade datalagerlösningar har blivit det föredragna valet för många företag, eftersom de erbjuder skalbarhet, prestanda, kostnadseffektivitet och tillgänglighet. Dessutom har ökningen av hybrida och heterogena dataarkitekturer blivit normen.
Vilken komponent ska användas för en specifik operation inom datateknik eller analys?
Behöver vi en molnbaserad datalagerlösning eller inte?
Hur spelar varje OEM en central roll i en multimolnarkitektur?
Dessa beslut är ofta skrämmande för CDO:er eftersom de har potential att avsevärt påverka effektiviteten och ändamålsenligheten i en organisations dataverksamhet.
AWS Redshift, med sin lagrings- och MPP-arkitektur (Massively Parallel Processing), och Google BigQuery, med ett unikt kolumnbaserat lagringssystem, står som två framstående aktörer inom detta område, där var och en erbjuder en unik uppsättning funktioner och möjligheter skräddarsydda för olika användningsfall.
Den globala marknaden för datalagring värderades till 28,73 miljarder USD år 2022 och de totala intäkterna förväntas växa med en årlig tillväxttakt (CAGR) på 10,7 % från 2023 till 2029 och nå nästan 58,54 miljarder USD [1].
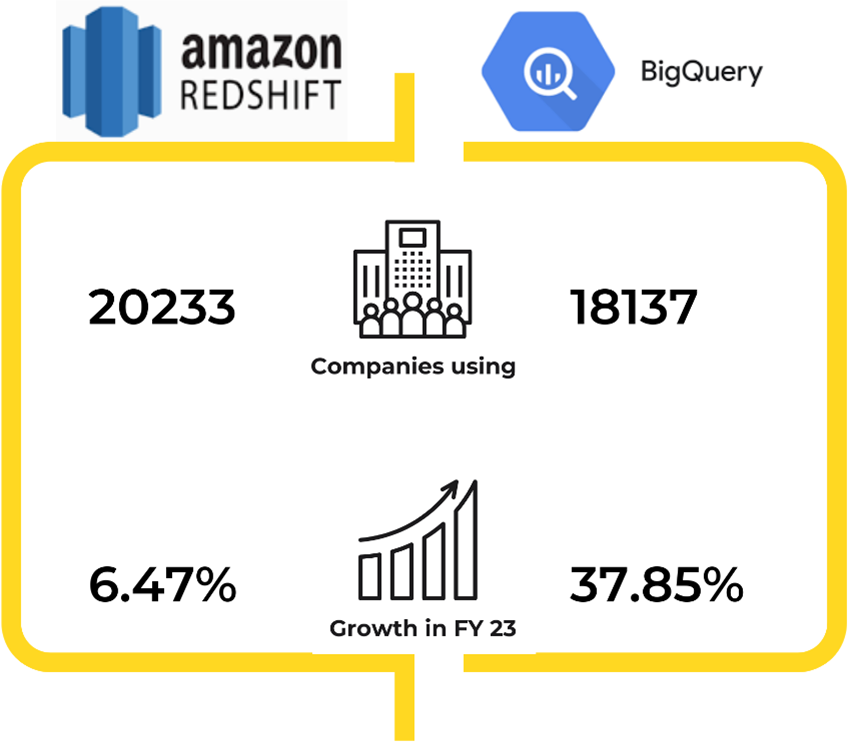
Arkitektur och datalagring
Amazon Redshift använder en kolumnbaserad lagringsarkitektur som organiserar data efter kolumner snarare än rader. Denna design möjliggör mycket effektiva fråge- och aggregeringsoperationer, särskilt för analysarbetsbelastningar. Dessutom fungerar Redshift på en klusterbaserad modell där flera noder samarbetar för att bearbeta frågor. Data distribueras över dessa noder, vilket möjliggör parallell bearbetning för förbättrad prestanda.
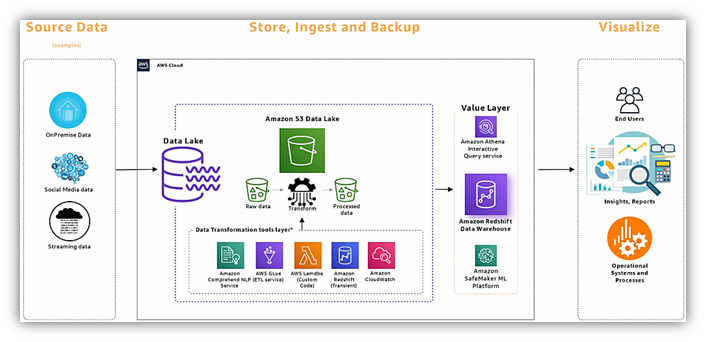
Datainmatning
Datainmatning i Redshift kan uppnås genom olika metoder, inklusive batchinläsning, direkta frågor och dataströmning. Den integreras sömlöst med AWS Glue, vilket möjliggör effektiva ETL-processer. Redshift stöder ett brett utbud av datakopplingar och API:er, vilket möjliggör smidig integration med olika datakällor. I prestandatester har Redshift visat inmatningshastigheter på upp till 10 GBps.
Avancerade analys- och maskininlärningsfunktioner
Amazon Redshift erbjuder en robust miljö för avancerad analys och maskininlärningsapplikationer (ML). Den integreras sömlöst med populära ML-ramverk som TensorFlow och Apache MXNet. Dessutom möjliggör Redshift Spectrum datasökning direkt från Amazon S3, vilket gör det möjligt för dataforskare att utnyttja kraften i externa datakällor i sina ML-modeller.
Säkerhet och efterlevnad
Redshift tillhandahåller ett robust säkerhetsramverk, inklusive funktioner som kryptering i vila och under överföring. Åtkomstkontroll hanteras via AWS Identity and Access Management (IAM), vilket möjliggör detaljerad kontroll över användarbehörigheter. Redshift följer olika branschstandarder och certifieringar, vilket ger en säker miljö för känsliga data. Det är värt att notera att Redshift har uppnått certifieringar som SOC 2, HIPAA och PCI DSS.
Prissättning och kostnadsöverväganden
Amazons flexibilitet utan långsiktiga åtaganden, medan reserverade instanser erbjuder betydande kostnadsbesparingar för förutsägbara arbetsbelastningar. Dessutom möjliggör Redshift Spectrum kostnadseffektiva frågor om data lagrade i Amazon S3, vilket ger en balans mellan prestanda och kostnad.
Ta en djupdykning i jämförelserna mellan RedShift och Snowflake
En upplysande utforskning som kommer att stärka ditt företag i många år framöver – Gör det bästa valet för dina databehov.

Till skillnad från den ovan nämnda konkurrenten från Amazon, använder BigQuery på Google Cloud Platform ett distribuerat lagringssystem som möjliggör sömlös skalning av beräkningsresurser efter behov. Data i BigQuery lagras i Capacitor, ett anpassat lagringsformat utformat för effektiv frågekörning. Denna arkitektur säkerställer att beräkningsresurserna enbart är avsedda för att bearbeta frågor, vilket leder till imponerande prestandavinster.
Datainmatning
BigQuery erbjuder en mängd olika inmatningsalternativ, inklusive batchinläsning, streaming och federerade frågor för att fråga externa datakällor. Dess nära integration med andra Google Cloud-tjänster förenklar dataarbetsflöden. Dessutom säkerställer BigQuerys stöd för standard SQL och kompatibilitet med populära ETL-verktyg smidiga dataintegrationsprocesser. BigQuery kan hantera strömmande data med en hastighet på upp till 100 000 rader per sekund och tabell.
Avancerade analys- och ML-funktioner
Google BigQuery erbjuder en inbyggd ML-tjänst som heter BigQuery ML, som låter användare bygga ML-modeller direkt i plattformen med hjälp av vanliga SQL-frågor. Detta eliminerar behovet av datautvinning och överföring till externa ML-verktyg. BigQuery ML stöder en mängd olika modelltyper, inklusive linjär och logistisk regression, tidsserieprognoser och mer.
Säkerhet och efterlevnad
Google Cloud-plattformen har utrustat BigQuery med omfattande säkerhetsåtgärder, inklusive kryptering av data både under överföring och i vila. Åtkomstkontroll hanteras via Google Cloud IAM, vilket möjliggör finjusterade åtkomstpolicyer. BigQuery följer också ett flertal branschregler, vilket säkerställer att de uppfyller de strängaste säkerhets- och efterlevnadskraven. BigQuery är certifierad enligt ISO 27001, SOC 2 och HIPAA, bland annat.
Prissättning och kostnadsöverväganden
BigQuery använder en prismodell baserat på användning, baserad på pay-as-you-go. Den separerar lagrings- och frågekostnader, vilket möjliggör exakt kontroll över kostnaderna. BigQuery har en distribuerad karaktär som innebär att användare bara betalar för de resurser som används under frågekörningen, vilket gör det till ett ekonomiskt val för organisationer som söker kostnadseffektiva dataanalyslösningar.
Amazon Redshift hittar sin nisch i scenarier där hög prestanda och komplex analys är av största vikt. De utmärker sig inom datalager, business intelligence och data science-applikationer, särskilt i organisationer som är starkt investerade i AWS-ekosystemet.
Google BigQuery, å andra sidan, lyser inom realtidsdataanalys och scenarier där snabb frågekörning är avgörande. Dess serverlösa arkitektur gör det till ett utmärkt val för organisationer som letar efter en molnbaserad datalagerlösning med lågt underhållsbehov och hög prestanda.
Amazon Redshift vs BigQuery: De viktigaste skillnaderna
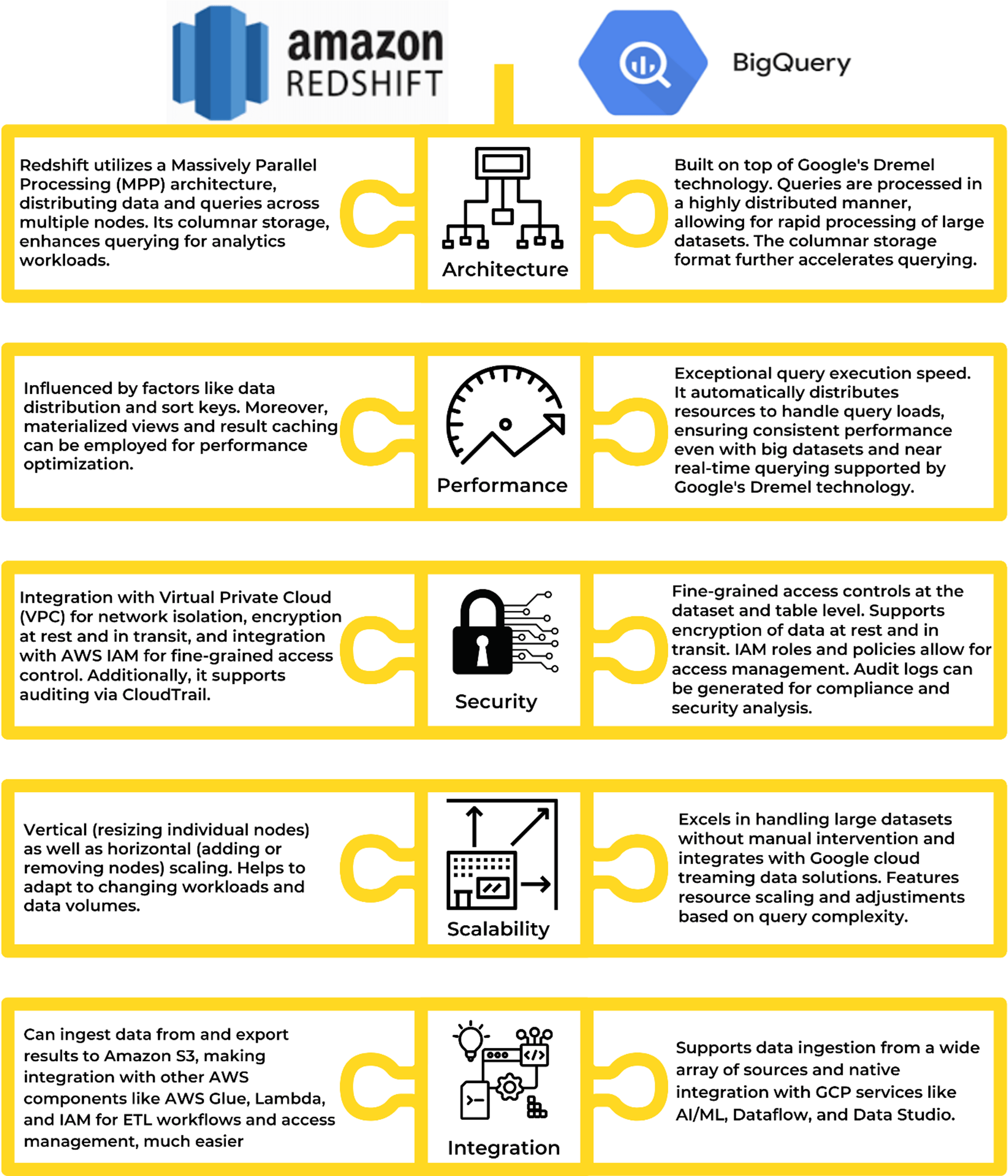
Övergripande datastrategi: Trots att Redshift har kapacitet att arbeta i ett hybridmolnsystem, kan det fungera sömlöst för organisationer med en väl etablerad AWS-infrastruktur – genom att utnyttja befintliga VPC:er, IAM-roller och datasjöintegrationer. Dess inbyggda integration med tjänster som AWS Glue för ETL och SageMaker för ML skapar ett sammanhängande dataekosystem. Omvänt positionerar BigQuerys multimolnkompatibilitet dem som en mångsidig aktör i heterogena eller hybridarkitekturer. Dess förmåga att fråga extern data direkt från molnlagring, i kombination med dess nära integration med Google Cloud AI/ML-tjänster, ger organisationer med olika molnmiljöer möjlighet att hantera olika typer av data.
Expertis/Talangernas tillgänglighet: Utöver själva plattformarna är det avgörande att överväga den expertis som krävs för att utnyttja deras fulla potential. Redshift lutar sig starkt mot SQL, vilket gör det till ett naturligt val för team som är vana vid relationsdatabaser. Dess integration med AWS-ekosystemtjänster som Glue, Lambda och Kinesis kräver en viss nivå av AWS-kunskaper. Å andra sidan kan BigQuerys egenutvecklade SQL-dialekt vara en bekväm anpassning för vissa team, men dess sömlösa integration med datasjöar och Google Clouds AI/ML-tjänster ger en inlärningskurva.
Prisjämförelse för Redshift och BigQuery: I det rådande osäkra affärsscenariot är en av de största faktorerna för de flesta företag kostnadsövervägandena. AWS RedShift-priset är lite lättare att förutsäga på grund av dess on-demand-, timme-till-timme-karaktär. Men i många affärsscenarier kan BigQuerys frågekostnad på 6,25 USD/TiB vara mer rimlig. Amazon Redshift, med sin kolumnära lagring och klusterbaserade arkitektur, är skräddarsydd för organisationer som kräver hög prestanda och skalbarhet, särskilt de som redan är etablerade i AWS-ekosystemet. Google BigQuery, med sin distribuerade arkitektur och pay-as-you-go-prissättning, erbjuder ett mer anpassningsbart pris- och lagringspaket – en effektiv lösning för organisationer som söker snabb frågekörning och sömlös skalbarhet.
Framtida användningsfall: Samspelet mellan datalagerplattformar och ML är ett område där potentialen hos Redshift och BigQuery kommer i förgrunden. Redshift, med sin MPP-arkitektur, lämpar sig utmärkt för parallelliserad bearbetning för ML-modellträning. Redshifts klusters elasticitet och skalbarhet, i kombination med GPU-stöd, ger dataforskare möjlighet att hantera alltmer komplexa modeller. BigQuery, med sina inbyggda ML-funktioner, utmärker sig vid snabb, iterativ modelldistribution och inferens. Beslutet beror därför på typen av dina ML-arbetsbelastningar – från intensiv modellträning till realtidsförutsägelser.
Redo att fördjupa dig i analysen av de fyra stora sjöhusen – AWS vs Snowflake vs Azure vs Google Cloud?
Kundsegmentering och personalisering för en detaljhandelskedja
AWS Redshifts MPP-arkitektur (Massively Parallel Processing) används för att effektivt hantera stora datamängder som innehåller kundtransaktionshistorik, demografisk information och beteendedata. Genom avancerade analystekniker som Singular Value Decomposition (SVD) eller t-distribuerad Stochastic Neighbour Embedding (t-SNE) utför detaljhandelskedjan invecklade kundsegmenteringsanalyser. Genom att integrera med maskininlärningsramverk som Apache Sparks MLlib eller sci-kit-learn kan kedjan utveckla personliga rekommendationsmotorer med hjälp av tekniker som samarbetsbaserad filtrering eller innehållsbaserad filtrering.
Värdeökning: Denna metod gör det möjligt för detaljhandelskedjan att leverera hyperpersonliga marknadsföringskampanjer, produktrekommendationer och kampanjerbjudanden. Genom att använda Redshifts beräkningsfunktioner och maskininlärning uppnår kedjan högre konverteringsfrekvenser och ökad kundlojalitet.
Förutsägande underhåll för en tillverkningsanläggning
BigQuerys strömbehandlingsfunktioner hanterar inkommande sensordata från tillverkningsutrustning. Tidsserieanalystekniker som använder Fast Fourier Transforms (FFT) eller Wavelet Transforms används för att upptäcka mönster som indikerar förestående utrustningsfel. Maskininlärningsalgoritmer integrerade med BigQuery genom plattformar som Google AI Platform möjliggör utveckling och driftsättning av prediktiva underhållsmodeller.
Värdeökning: Denna tekniska metod gör det möjligt för tillverkningsanläggningen att förutsäga och schemalägga underhållsaktiviteter innan kritiska utrustningsfel inträffar. Genom att utnyttja Bigquerys realtidsdatabehandlingskapacitet och maskininlärning uppnår anläggningen betydande kostnadsbesparingar genom minimerad oplanerad driftstopp och ökad driftseffektivitet.
Valet mellan Amazon Redshift och Google BigQuery beror i slutändan på en organisations specifika krav och prioriteringar. Det finns vissa skillnader, men det finns betydligt fler likheter.
Sammanfattningsvis är en grundlig förståelse av de tekniska nyanserna hos varje plattform avgörande för att fatta ett välgrundat beslut. Genom att anpassa styrkorna hos Amazon Redshift eller Google BigQuery till din organisations specifika behov kan du frigöra den fulla potentialen i dina dataanalysinsatser .