 Kshitij GuptaData-strateeg
Kshitij GuptaData-strateeg
Meld u aan om de nieuwste inzichten en updates over technologie, AI & data-analyse, datawetenschap en innovaties van Polestar Analytics te ontvangen.
Decennialang betekende het bouwen van een realtime AI-applicatie het beheren van twee fundamenteel incompatibele systemen. De analyse- en machine learning-infrastructuur bevond zich aan de ene kant – in een data lake of datawarehouse dat was ontworpen voor hoge doorvoersnelheden. De operationele database bevond zich aan de andere kant – een standalone PostgreSQL-instantie die vastlegde wat gebruikers op dat moment daadwerkelijk deden. Daartussen bevond zich een kwetsbare pipeline: change data capture-taken, ETL-synchronisaties en replicatielogica die volgens een vast schema vastliepen en latentie introduceerden die in minuten, en niet in milliseconden, werd gemeten.
De zakelijke kosten van die architecturale fragmentatie zijn goed gedocumenteerd. Organisaties lijden gemiddeld $12,9 miljoen aan verliezen per jaar die direct toe te schrijven zijn aan slechte datakwaliteit – een bedrag dat nog hoger oploopt wanneer realtime AI-systemen moeten werken met verouderde data die door vertragingen in de dataverwerking zijn ontstaan.
Toch zullen organisaties tot 2026 60% van de AI-projecten stopzetten die niet worden ondersteund door data die geschikt is voor AI. Het knelpunt zit niet in de rekenkracht en ook niet in de kwaliteit van de modellen. Het zit hem in de afstand tussen de transactionele data en de AI-systemen die deze data proberen te verwerken.
Databricks Lakebase is het architectonische antwoord op die lacune. Operationele databases vertegenwoordigen een markt van meer dan 100 miljard dollar en vormen de basis van elke applicatie. Maar ze zijn gebaseerd op een decenniaoude architectuur, ontworpen voor applicaties die langzaam veranderen. Dit maakt ze moeilijk te beheren, duur en gevoelig voor vendor lock-in. AI introduceert een nieuwe reeks vereisten: elke data-applicatie, agent, aanbeveling en geautomatiseerde workflow heeft nu snelle, betrouwbare data nodig met de snelheid en schaal van AI-agents .
Sinds de lancering in juni 2025 is het gebruik ervan meer dan twee keer zo snel gegroeid als dat van Databricks' datawarehouseproduct, waarbij duizenden bedrijven productieworkloads rechtstreeks op hun operationele data uitvoeren.
De conventionele aanpak voor het bouwen van data-applicaties dwong tot een zware technische afweging. Je moest de informatieve use case – historische context, het genereren van ML-features, analytische query's – afwegen tegen de transactionele use case – vastleggen wat een gebruiker drie seconden geleden aanklikte, de voorraad in realtime bijwerken, de agentstatus tijdens een workflow behouden.
Het beheren van beide systemen betekende dat er aparte databases moesten worden beheerd die met elkaar verbonden waren door kwetsbare pijplijnen. De omvang van dit probleem is aanzienlijk: datateams melden gemiddeld 67 incidenten met de pijplijn per maand, en 68% van de teams heeft vier uur of langer nodig om een storing te detecteren wanneer deze zich voordoet. Data-engineers werden pijplijnbrandbestrijders. Machine learning-modellen haalden gegevens op die al verouderd waren tegen de tijd dat ze binnenkwamen. Realtime AI-toepassingen bleken een contradictie op zich.
Lakebase op het Databricks-databaseplatform is meer dan alleen "Postgres op Databricks". Het is een fundamentele verandering in de manier waarop we denken over operationele en analytische data die naast elkaar bestaan — beheerd, doorzoekbaar en aangedreven door hetzelfde platform.
In plaats van een aparte database op te zetten, reverse ETL-taken te bouwen en authenticatie op twee plaatsen te beheren, kunnen teams nu beheerde Lakehouse-tabellen synchroniseren met PostgreSQL met querytijden van milliseconden , applicatiestatus- en transactietabellen rechtstreeks in Databricks Lakebase bouwen en alles beveiligen met Databricks-identiteiten en PostgreSQL-rollen.
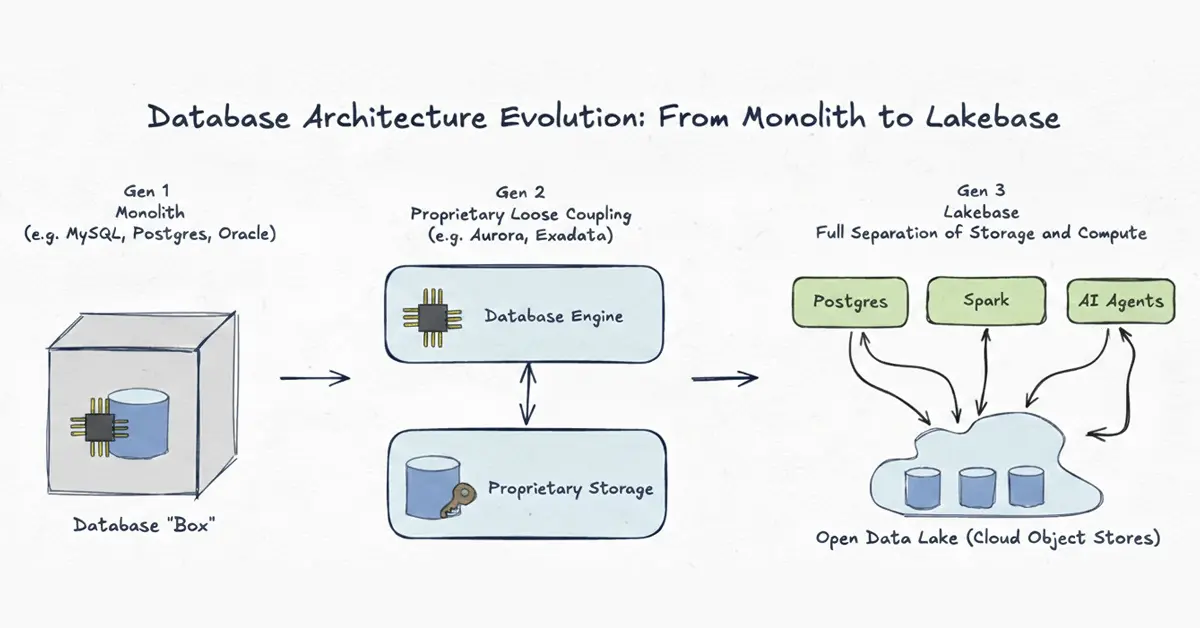
Hoe de databasearchitectuur zich over drie generaties heeft ontwikkeld: van monolithische on-premises systemen tot volledig ontkoppelde, open Lakebase-architectuur. De scheiding van rekenkracht en opslag is de belangrijkste doorbraak die realtime AI-toepassingen mogelijk maakt zonder kwetsbare pipelines.
Databricks Lakebase vereenvoudigt applicatieontwikkeling met een bewezen OLTP-database, zonder de problemen van databasebeheer. Het elimineert complexe, op maat gemaakte ETL-pipelines en zorgt ervoor dat transactionele data wordt geïntegreerd in analyses en Databricks AI-native applicaties. Teams kunnen ontwikkelvertragingen voorkomen door gebruik te maken van de vertrouwde, open-source PostgreSQL met bestaande bibliotheken , frameworks en SQL — met ontkoppelde reken- en opslagprocessen voor onafhankelijke schaling, herstel naar een specifiek tijdstip en de mogelijkheid om een database te versioneren zoals code.
De Databricks Lakebase-architectuur combineert de betrouwbaarheid en bekendheid van PostgreSQL met moderne databasefunctionaliteiten, waaronder automatisch schalen, schalen naar nul, vertakkingen en direct herstel. Deze functies maken flexibele ontwikkelworkflows, kostenefficiënte processen en snelle iteratie mogelijk. Het platform integreert met realtime feature serving voor ML-modellen en Feature Store, agentstatus voor AI-agents en transactionele data voor Databricks Apps of elke andere applicatie die ermee verbonden is.
Gegevens worden in twee richtingen tussen het Lakehouse en Lakebase uitgewisseld:
Beide richtingen. Geen aangepaste pipelines!
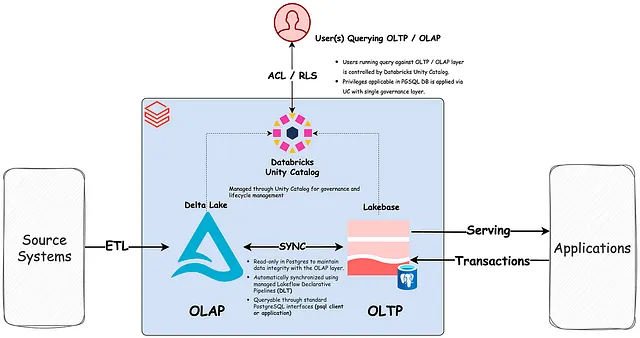
De Databricks Lakebase-architectuur: transactionele berekeningen (Postgres) draaien onafhankelijk bovenop open-formaat opslag in de lake, waardoor OLTP- en OLAP-workloads worden verenigd op één beheerd platform — zonder ETL-pipelines ertussen.
Het Lakebase Databricks-platform biedt een reeks mogelijkheden die geschikt zijn voor productieomgevingen:
| Functie | Wat het doet | Waarom het belangrijk is |
|---|---|---|
| Serverloze automatische schaling en schaalbaarheid naar nul | De computer past zich dynamisch aan het verkeer aan; hij schakelt zichzelf uit wanneer hij inactief is. | Elimineert verspilling van geld aan ongebruikte infrastructuur. |
| Directe databasevertakking | Creëert binnen enkele seconden kopieën van productiedata zonder enige kopie. | Risicovrij testen zonder volledige datasets te dupliceren. |
| Point-in-Time Recovery (PITR) | Herstelt de database naar een willekeurige milliseconde binnen het bewaarvenster. | Bescherming tegen onbedoelde verwijderingen en applicatiefouten. |
| Unity Catalog Governance | Eén uniform beveiligingsmodel voor operationele en analytische gegevens. | Eén toegangsbeheerbeleid voor het gehele data-landschap. |
| Tabellen synchroniseren | Zorgt ervoor dat de gegevens van Lakehouse en Lakebase automatisch op elkaar zijn afgestemd. | Geen kwetsbare pipelines; geen handmatige synchronisatietaken. |
| Postgres 17-ondersteuning + pgvector | Volledige PostgreSQL-compatibiliteit, inclusief AI-native vectorzoekopdrachten. | Gebruik bestaande tools; schakel semantisch en gelijkeniszoeken standaard in. |
De mogelijkheid om branches te creëren verdient bijzondere aandacht. Net als Git voor je database, stellen branches teams in staat om binnen enkele seconden geïsoleerde omgevingen te creëren, los van de productiedata. Zo kunnen ze schemawijzigingen testen, nieuwe applicatielogica valideren en belastingstests uitvoeren, zonder de live workloads aan te raken of de kosten van volledige dataduplicatie te hoeven dragen.
Het opzetten van een productieklare applicatie op het Lakebase Databricks-platform volgt een gestructureerd traject. De Microsoft Azure Databricks Lakebase-documentatie en de Databricks-blog over het bouwen van productieklare apps beschrijven dit beide in detail.
De belangrijkste fasen zijn:
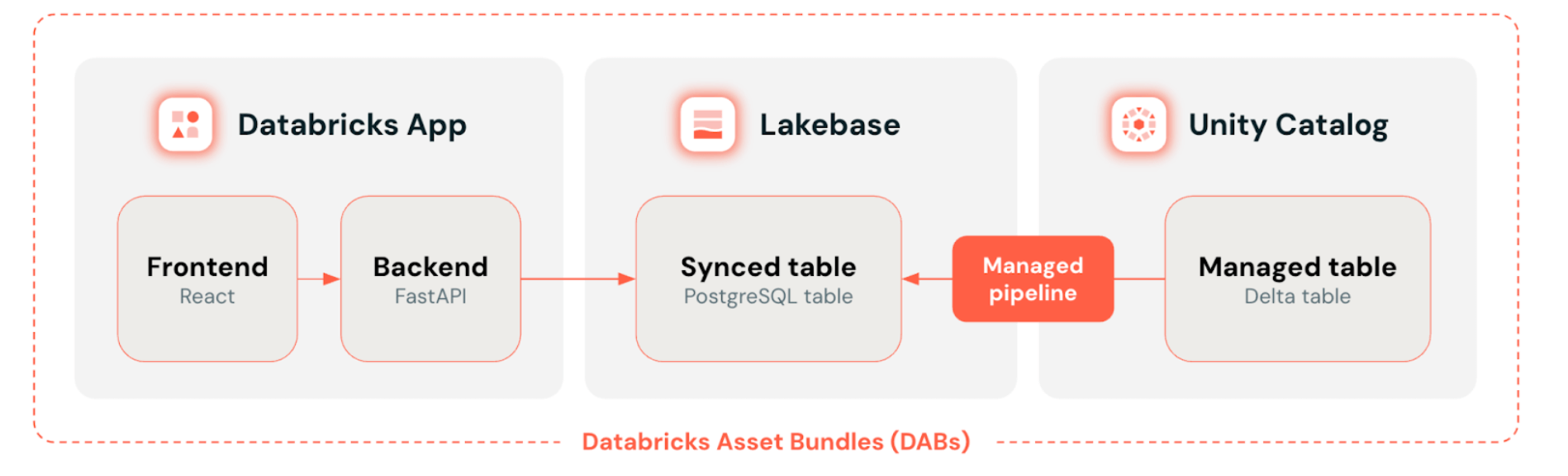
Hoe een productiegereed data-applicatie wordt samengesteld op het Lakebase Databricks-platform: Databricks Apps aan de front-end, Databricks Lakebase als de transactionele datalaag, Unity Catalog voor het beheer van gecontroleerde Delta-tabellen met automatische synchronisatie — alles geïmplementeerd als code via Databricks Asset Bundles.
De toepassingsmogelijkheden van de Lakebase-database bestrijken diverse sectoren en architectuurpatronen. Databricks Lakebase identificeert de volgende primaire workloadtypen:
| Industrie | Gebruiksvoorbeeld van de Lakebase-database | Wat het vervangt |
|---|---|---|
| Detailhandel en e-commerce | Gepersonaliseerde aanbevelingen en realtime gerichte aanbiedingen | Op zichzelf staande aanbevelingssystemen die worden gevoed door vertraagde batchverwerkingsprocessen. |
| Gezondheidszorg | Gegevensbeheer van klinische onderzoeken in combinatie met voorspellende diagnostische modellen. | Geïsoleerde OLTP-databases, losgekoppeld van analytische ML-lagen. |
| Financiële diensten | Geautomatiseerde handels- en streamingfraudedetectie-analyses | Gescheiden operationele databases met CDC-pipelines voor analyses. |
| Productie | Werkprocessen voor het verwerken van machinetelemetrie en voorspellend onderhoud. | Lokale historie-systemen met handmatige data-exporttaken |
| Media & Entertainment | Realtime personalisatie van content en tracking van publieksbetrokkenheid | Gefragmenteerde gebeurtenisregistratie met vertraagde synchronisatie van het datawarehouse |
Databricks Lakebase is ontwikkeld voor een specifiek probleem. Het is geen universele vervanging voor elke operationele database. Hieronder vindt u een duidelijk kader om te beoordelen of het geschikt is:
Gebruik Databricks Lakebase wanneer:
Gebruikers van Azure Databricks Lakebase moeten rekening houden met de huidige regionale beschikbaarheid van Autoscaling voor het platform – die de belangrijkste AWS- en Azure-regio's omvat – voordat ze latencygevoelige wereldwijde implementaties plannen. De Azure-documentatie beschrijft de ondersteunde regio's en configuratie-details.
Databricks Lakebase ondersteunt een latentie van minder dan 10 ms voor workloads met een hoge doorvoer, wat voldoet aan de eisen van de overgrote meerderheid van AI-toepassingen binnen bedrijven. De combinatie van Databricks Lakebase met de OLTP-database maakt het mogelijk om architectuurproblemen op een fundamenteel andere manier op te lossen, met een duidelijke weg weg van kwetsbare ETL-pipelines en de gedwongen scheiding van analytische en operationele lagen.
Databricks Lakebase is nu algemeen beschikbaar op AWS en in bèta op Azure, met een groeiend ecosysteem van lanceringspartners die het platform hebben gevalideerd voor databasemodernisering, realtime applicatieontwikkeling en agentische AI-workflows. De lanceringspartners van Databricks Lakebase staan klaar om klanten te helpen profiteren van deze verschuiving, nadat ze het Lakebase Databricks-platform hebben gevalideerd voor databasemodernisering, het bouwen van realtime applicaties en het implementeren van agentische AI-workflows.
Polestar Analytics is een van de lanceringspartners. Als specialist in Databricks AI-native implementaties op het gebied van data-engineering, AI-toepassingen en Databricks Lakebase-architectuur , biedt Polestar Analytics de implementatiemethodologie – architectuurontwerp, dataflow-mapping, governance-configuratie en applicatie-integratie – die een technisch capabel platform transformeert in een productiesysteem dat betrouwbaar presteert en voorspelbaar schaalbaar is. Het Databricks-databaseplatform elimineert de architecturale bottleneck. Een bewezen implementatiepartner elimineert het implementatierisico.
Integratiekaart van Databricks Lakebase: Waar Lakebase zich bevindt in het volledige platform
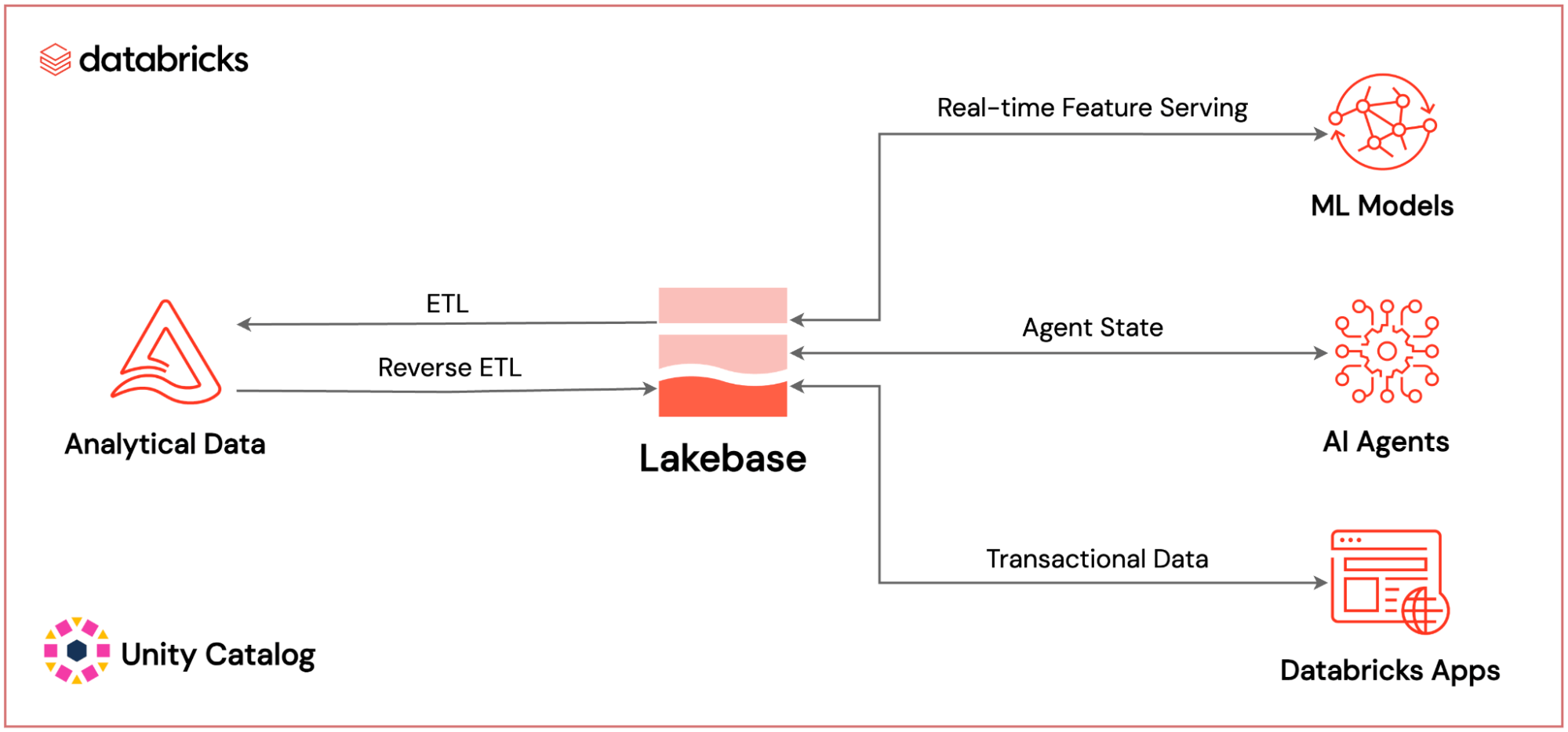
De positie van Databricks Lakebase binnen het complete, native Databricks AI-platform: het levert realtime ML-functionaliteit, bewaart de status van AI-agenten en beheert transactionele applicatiegegevens – allemaal beheerd door Unity Catalog.
Bouw uw realtime AI-applicatie op Databricks Lakebase. Van het architectuurontwerp van Databricks Lakebase tot de implementatie in productie: Polestar Analytics begeleidt u in elke fase van uw implementatie.
Neem contact op met ons engineeringteam.Lakebase beheert bidirectionele gegevensverplaatsing via twee speciale mechanismen: Synced Tables en Lakehouse Sync, die beide zonder aangepaste pipelines werken. Consistentie wordt op platformniveau gewaarborgd, waardoor handmatige ETL-taken die traditioneel kunnen afwijken, stilletjes mislukken of vertraging veroorzaken, overbodig worden.
Nee, Lakebase is compatibel met PostgreSQL 17, dus bestaande drivers, ORM's, SQL-query's en bibliotheken blijven zonder aanpassingen werken. De verandering zit hem in waar PostgreSQL draait en waarmee het verbinding maakt, niet in hoe ontwikkelaars er dagelijks mee omgaan.
Ja, teams gebruiken het tegenwoordig voor operationele dashboards, realtime personalisatie en transactionele apps die simpelweg schone, gecontroleerde data nodig hebben zonder de overhead van een dataverwerkingspipeline. De AI-mogelijkheden zijn beschikbaar wanneer je er klaar voor bent, maar ze zijn geen vereiste om vanaf dag één waarde te behalen.
Over de auteur
Data-strateeg
De meeste data geeft antwoord op vragen. De juiste data verandert de richting.
Gerelateerde blog
Kshitij Gupta